 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse Coherence and Shifting Centers in Japanese Texts
Sep 24, 1996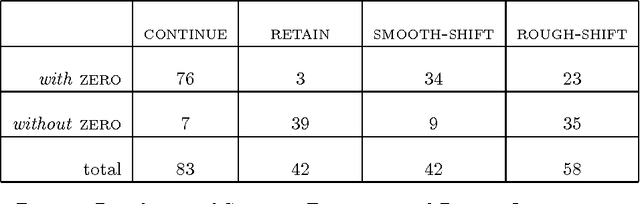
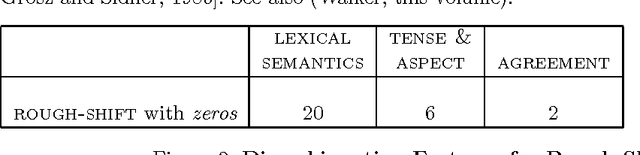

In languages such as Japanese, the use of {\it zeros}, unexpressed arguments of the verb, in utterances that shift the topic involves a risk that the meaning intended by the speaker may not be transparent to the hearer. However, this potentially undesirable conversational strategy often occurs in the course of naturally-occurring discourse. In this chapter, I report on an empirical study of 250 utterances with {\it zeros} in 20 Japanese newspaper articles. Each utterance is analyzed in terms of centering transitions and the form in which centers are realized by referring expressions. I also examine lexical subcategorization information, and tense and aspect in order to test the hypothesis that the speaker expects the hearer to use this information in determining global discourse structure. I explain the occurrence of {\it zeros} in {\sc retain} and {\sc rough-shift} centering transitions, by claiming that a {\it zero} can only be used in these cases when the shift of centers is supported by contextual information such as lexical semantics, tense and aspect, and agreement features. I then propose an algorithm by which centering can incorporate these observations to integrate centering with global discourse structure, and thus enhance its ability for non-local pronoun resolution.
* 20 pages, uses elsart12.sty, lingmacros.sty, named.sty
Japanese Discourse and the Process of Centering
Sep 24, 1996This paper has three aims: (1) to generalize a computational account of the discourse process called {\sc centering}, (2) to apply this account to discourse processing in Japanese so that it can be used in computational systems for machine translation or language understanding, and (3) to provide some insights on the effect of syntactic factors in Japanese on discourse interpretation. We argue that while discourse interpretation is an inferential process, syntactic cues constrain this process, and demonstrate this argument with respect to the interpretation of {\sc zeros}, unexpressed arguments of the verb, in Japanese. The syntactic cues in Japanese discourse that we investigate are the morphological markers for grammatical {\sc topic}, the postposition {\it wa}, as well as those for grammatical functions such as {\sc subject}, {\em ga}, {\sc object}, {\em o} and {\sc object2}, {\em ni}. In addition, we investigate the role of speaker's {\sc empathy}, which is the viewpoint from which an event is described. This is syntactically indicated through the use of verbal compounding, i.e. the auxiliary use of verbs such as {\it kureta, kita}. Our results are based on a survey of native speakers of their interpretation of short discourses, consisting of minimal pairs, varied by one of the above factors. We demonstrate that these syntactic cues do indeed affect the interpretation of {\sc zeros}, but that having previously been the {\sc topic} and being realized as a {\sc zero} also contributes to the salience of a discourse entity. We propose a discourse rule of {\sc zero topic assignment}, and show that {\sc centering} provides constraints on when a {\sc zero} can be interpreted as the {\sc zero topic}.
* 38 pages, uses clstyle, lingmacros
Centering in Japanese Discourse
Sep 24, 1996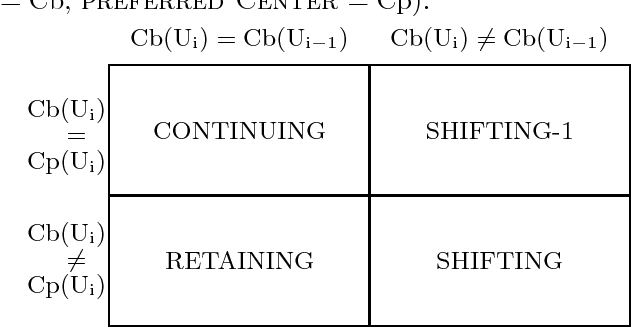
In this paper we propose a computational treatment of the resolution of zero pronouns in Japanese discourse, using an adaptation of the centering algorithm. We are able to factor language-specific dependencies into one parameter of the centering algorithm. Previous analyses have stipulated that a zero pronoun and its cospecifier must share a grammatical function property such as {\sc Subject} or {\sc NonSubject}. We show that this property-sharing stipulation is unneeded. In addition we propose the notion of {\sc topic ambiguity} within the centering framework, which predicts some ambiguities that occur in Japanese discourse. This analysis has implications for the design of language-independent discourse modules for Natural Language systems. The centering algorithm has been implemented in an HPSG Natural Language system with both English and Japanese grammars.
* 7 pages, uses twocolumn
Filling Knowledge Gaps in a Broad-Coverage Machine Translation System
Jun 10, 1995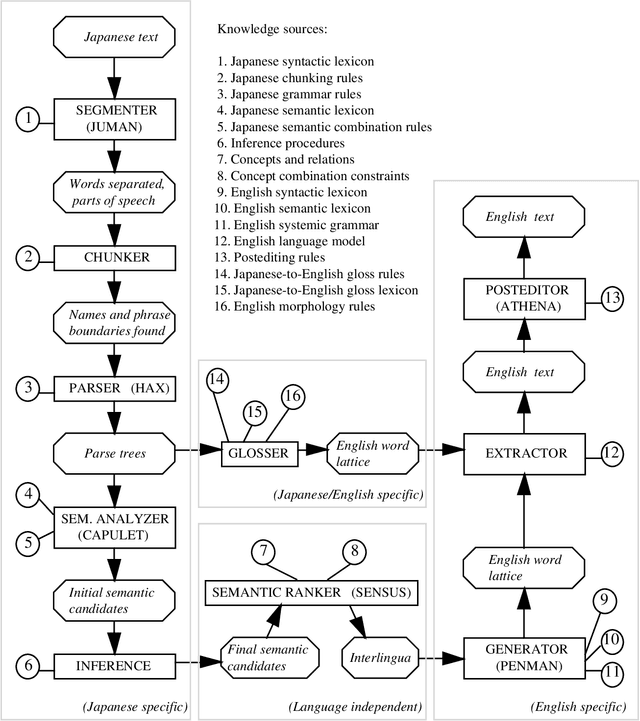
Knowledge-based machine translation (KBMT) techniques yield high quality in domains with detailed semantic models, limited vocabulary, and controlled input grammar. Scaling up along these dimensions means acquiring large knowledge resources. It also means behaving reasonably when definitive knowledge is not yet available. This paper describes how we can fill various KBMT knowledge gaps, often using robust statistical techniques. We describe quantitative and qualitative results from JAPANGLOSS, a broad-coverage Japanese-English MT system.
Integrating Knowledge Bases and Statistics in MT
Sep 05, 1994
We summarize recent machine translation (MT) research at the Information Sciences Institute of USC, and we describe its application to the development of a Japanese-English newspaper MT system. Our work aims at scaling up grammar-based, knowledge-based MT techniques. This scale-up involves the use of statistical methods, both in acquiring effective knowledge resources and in making reasonable linguistic choices in the face of knowledge gaps.
* 8 pages, compressed, uuencoded postscript