 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnification-Based Glossing
Jun 10, 1995
We present an approach to syntax-based machine translation that combines unification-style interpretation with statistical processing. This approach enables us to translate any Japanese newspaper article into English, with quality far better than a word-for-word translation. Novel ideas include the use of feature structures to encode word lattices and the use of unification to compose and manipulate lattices. Unification also allows us to specify abstract features that delay target-language synthesis until enough source-language information is assembled. Our statistical component enables us to search efficiently among competing translations and locate those with high English fluency.
Two-level, Many-Paths Generation
Jun 10, 1995Large-scale natural language generation requires the integration of vast amounts of knowledge: lexical, grammatical, and conceptual. A robust generator must be able to operate well even when pieces of knowledge are missing. It must also be robust against incomplete or inaccurate inputs. To attack these problems, we have built a hybrid generator, in which gaps in symbolic knowledge are filled by statistical methods. We describe algorithms and show experimental results. We also discuss how the hybrid generation model can be used to simplify current generators and enhance their portability, even when perfect knowledge is in principle obtainable.
Filling Knowledge Gaps in a Broad-Coverage Machine Translation System
Jun 10, 1995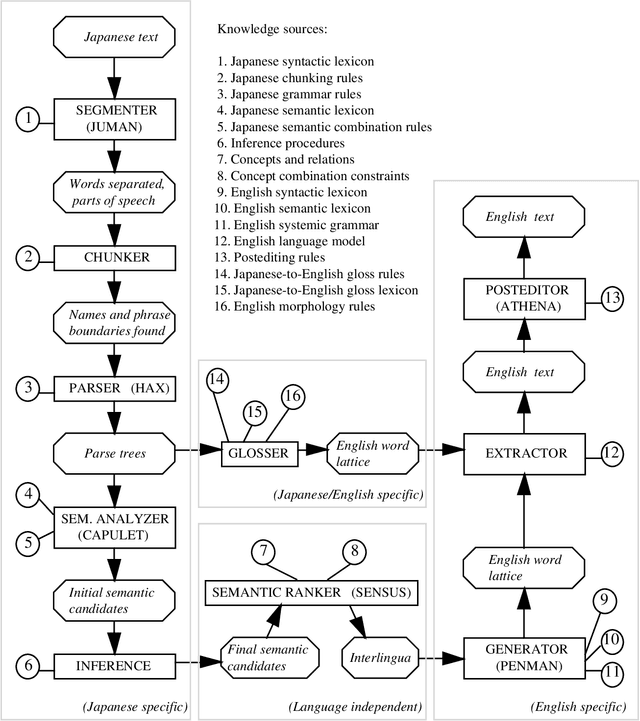
Knowledge-based machine translation (KBMT) techniques yield high quality in domains with detailed semantic models, limited vocabulary, and controlled input grammar. Scaling up along these dimensions means acquiring large knowledge resources. It also means behaving reasonably when definitive knowledge is not yet available. This paper describes how we can fill various KBMT knowledge gaps, often using robust statistical techniques. We describe quantitative and qualitative results from JAPANGLOSS, a broad-coverage Japanese-English MT system.
Integrating Knowledge Bases and Statistics in MT
Sep 05, 1994
We summarize recent machine translation (MT) research at the Information Sciences Institute of USC, and we describe its application to the development of a Japanese-English newspaper MT system. Our work aims at scaling up grammar-based, knowledge-based MT techniques. This scale-up involves the use of statistical methods, both in acquiring effective knowledge resources and in making reasonable linguistic choices in the face of knowledge gaps.
* 8 pages, compressed, uuencoded postscript