 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling Knowledge Gaps in a Broad-Coverage Machine Translation System
Jun 10, 1995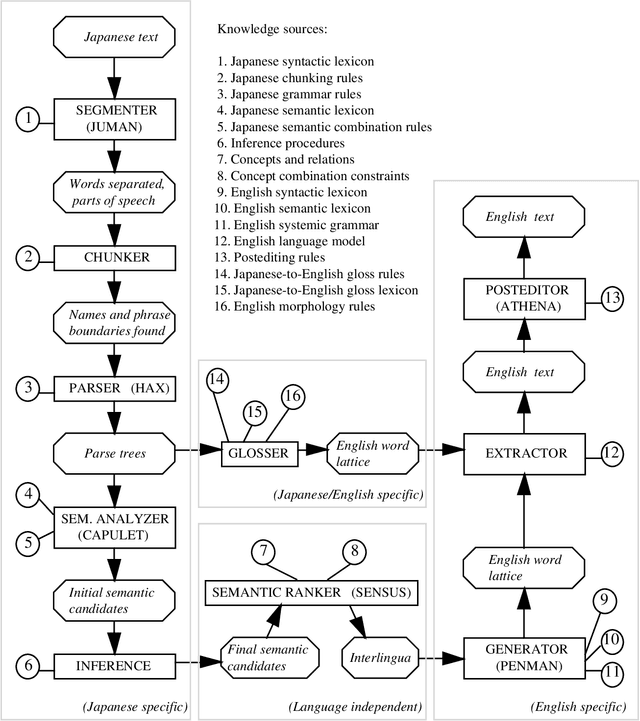
Knowledge-based machine translation (KBMT) techniques yield high quality in domains with detailed semantic models, limited vocabulary, and controlled input grammar. Scaling up along these dimensions means acquiring large knowledge resources. It also means behaving reasonably when definitive knowledge is not yet available. This paper describes how we can fill various KBMT knowledge gaps, often using robust statistical techniques. We describe quantitative and qualitative results from JAPANGLOSS, a broad-coverage Japanese-English MT system.
Integrating Knowledge Bases and Statistics in MT
Sep 05, 1994
We summarize recent machine translation (MT) research at the Information Sciences Institute of USC, and we describe its application to the development of a Japanese-English newspaper MT system. Our work aims at scaling up grammar-based, knowledge-based MT techniques. This scale-up involves the use of statistical methods, both in acquiring effective knowledge resources and in making reasonable linguistic choices in the face of knowledge gaps.
* 8 pages, compressed, uuencoded postscript
Building a Large-Scale Knowledge Base for Machine Translation
Jul 29, 1994
Knowledge-based machine translation (KBMT) systems have achieved excellent results in constrained domains, but have not yet scaled up to newspaper text. The reason is that knowledge resources (lexicons, grammar rules, world models) must be painstakingly handcrafted from scratch. One of the hypotheses being tested in the PANGLOSS machine translation project is whether or not these resources can be semi-automatically acquired on a very large scale. This paper focuses on the construction of a large ontology (or knowledge base, or world model) for supporting KBMT. It contains representations for some 70,000 commonly encountered objects, processes, qualities, and relations. The ontology was constructed by merging various online dictionaries, semantic networks, and bilingual resources, through semi-automatic methods. Some of these methods (e.g., conceptual matching of semantic taxonomies) are broadly applicable to problems of importing/exporting knowledge from one KB to another. Other methods (e.g., bilingual matching) allow a knowledge engineer to build up an index to a KB in a second language, such as Spanish or Japanese.