 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling Knowledge Gaps in a Broad-Coverage Machine Translation System
Jun 10, 1995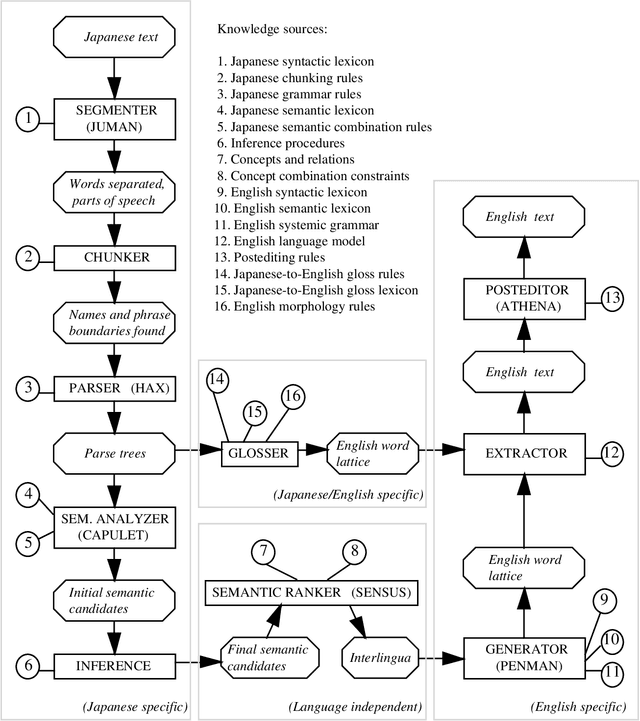
Knowledge-based machine translation (KBMT) techniques yield high quality in domains with detailed semantic models, limited vocabulary, and controlled input grammar. Scaling up along these dimensions means acquiring large knowledge resources. It also means behaving reasonably when definitive knowledge is not yet available. This paper describes how we can fill various KBMT knowledge gaps, often using robust statistical techniques. We describe quantitative and qualitative results from JAPANGLOSS, a broad-coverage Japanese-English MT system.
Integrating Knowledge Bases and Statistics in MT
Sep 05, 1994
We summarize recent machine translation (MT) research at the Information Sciences Institute of USC, and we describe its application to the development of a Japanese-English newspaper MT system. Our work aims at scaling up grammar-based, knowledge-based MT techniques. This scale-up involves the use of statistical methods, both in acquiring effective knowledge resources and in making reasonable linguistic choices in the face of knowledge gaps.
* 8 pages, compressed, uuencoded postscript
Automated Postediting of Documents
Jul 29, 1994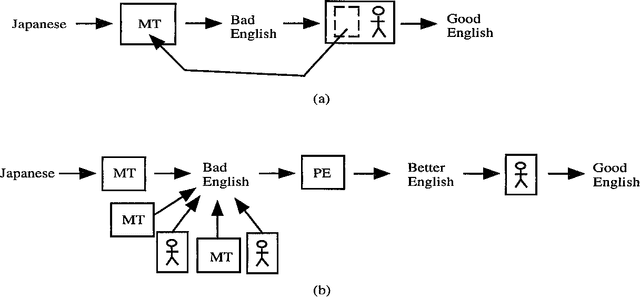
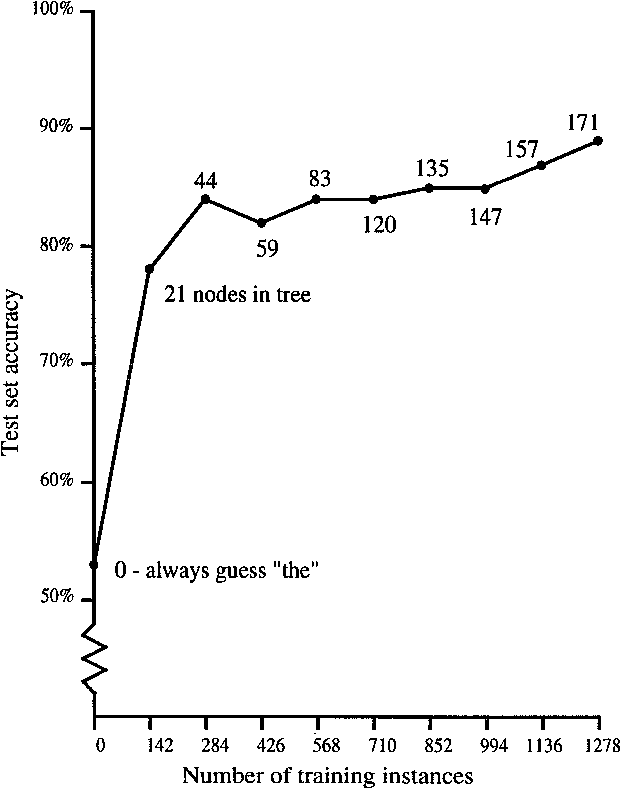
Large amounts of low- to medium-quality English texts are now being produced by machine translation (MT) systems, optical character readers (OCR), and non-native speakers of English. Most of this text must be postedited by hand before it sees the light of day. Improving text quality is tedious work, but its automation has not received much research attention. Anyone who has postedited a technical report or thesis written by a non-native speaker of English knows the potential of an automated postediting system. For the case of MT-generated text, we argue for the construction of postediting modules that are portable across MT systems, as an alternative to hardcoding improvements inside any one system. As an example, we have built a complete self-contained postediting module for the task of article selection (a, an, the) for English noun phrases. This is a notoriously difficult problem for Japanese-English MT. Our system contains over 200,000 rules derived automatically from online text resources. We report on learning algorithms, accuracy, and comparisons with human performance.