 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Exact Signal Scanning with Deep Convolutional Neural Networks
Aug 02, 2017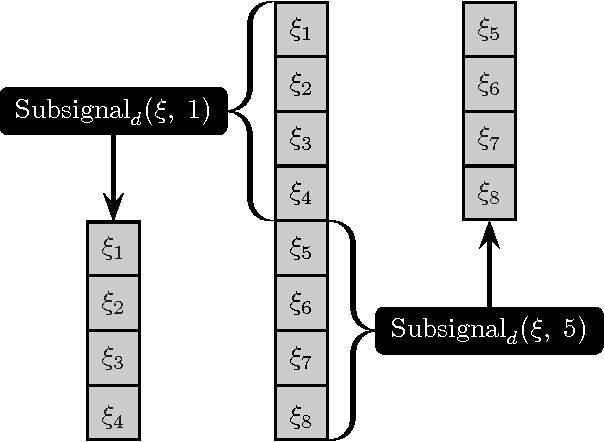
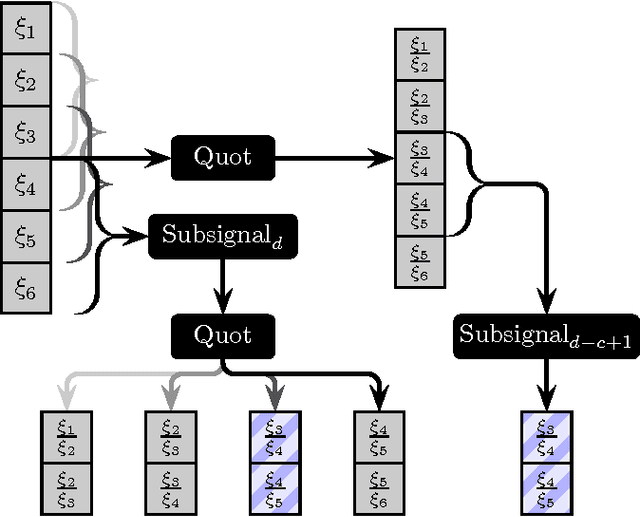
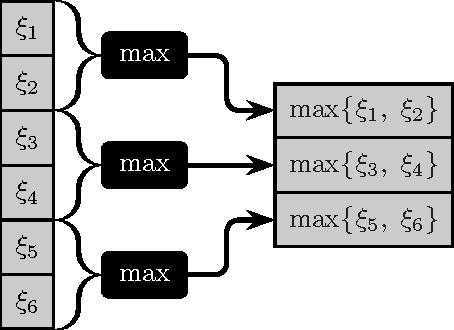
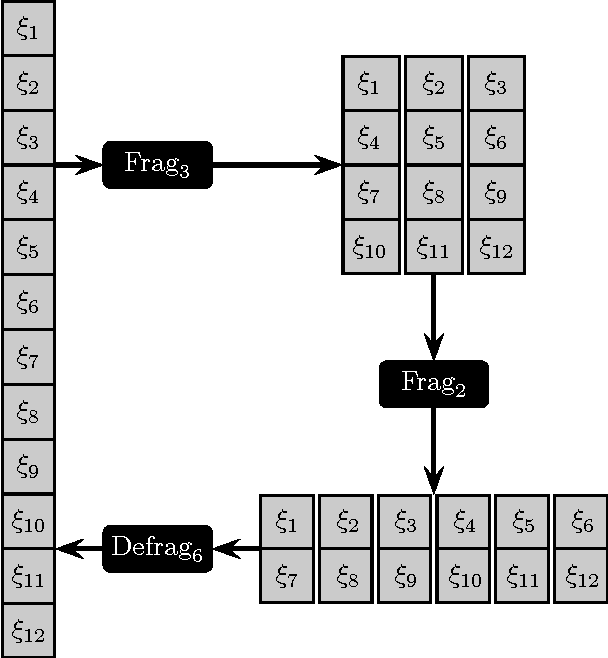
A rigorous formulation of the dynamics of a signal processing scheme aimed at dense signal scanning without any loss in accuracy is introduced and analyzed. Related methods proposed in the recent past lack a satisfactory analysis of whether they actually fulfill any exactness constraints. This is improved through an exact characterization of the requirements for a sound sliding window approach. The tools developed in this paper are especially beneficial if Convolutional Neural Networks are employed, but can also be used as a more general framework to validate related approaches to signal scanning. The proposed theory helps to eliminate redundant computations and renders special case treatment unnecessary, resulting in a dramatic boost in efficiency particularly on massively parallel processors. This is demonstrated both theoretically in a computational complexity analysis and empirically on modern parallel processors.
* Pages 1-16 only: Copyright (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission
A Random Finite Set Approach for Dynamic Occupancy Grid Maps with Real-Time Application
Sep 10, 2016
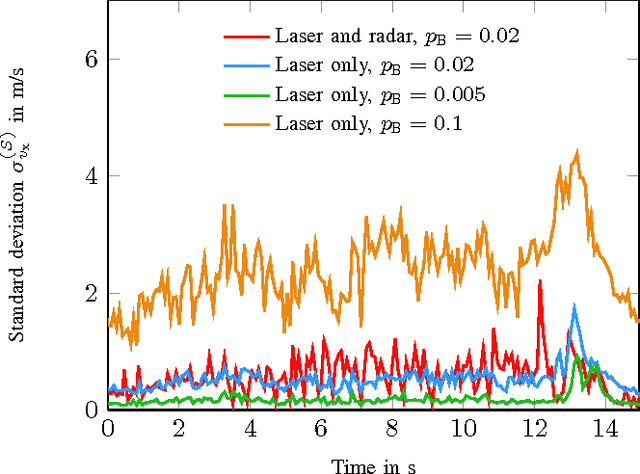
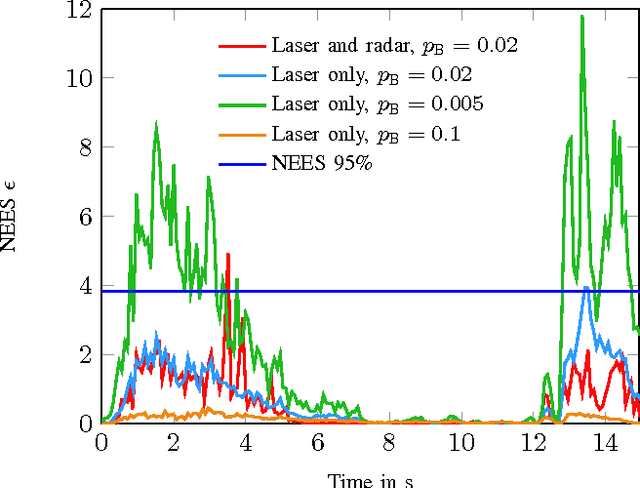

Grid mapping is a well established approach for environment perception in robotic and automotive applications. Early work suggests estimating the occupancy state of each grid cell in a robot's environment using a Bayesian filter to recursively combine new measurements with the current posterior state estimate of each grid cell. This filter is often referred to as binary Bayes filter (BBF). A basic assumption of classical occupancy grid maps is a stationary environment. Recent publications describe bottom-up approaches using particles to represent the dynamic state of a grid cell and outline prediction-update recursions in a heuristic manner. This paper defines the state of multiple grid cells as a random finite set, which allows to model the environment as a stochastic, dynamic system with multiple obstacles, observed by a stochastic measurement system. It motivates an original filter called the probability hypothesis density / multi-instance Bernoulli (PHD/MIB) filter in a top-down manner. The paper presents a real-time application serving as a fusion layer for laser and radar sensor data and describes in detail a highly efficient parallel particle filter implementation. A quantitative evaluation shows that parameters of the stochastic process model affect the filter results as theoretically expected and that appropriate process and observation models provide consistent state estimation results.
Efficient Dictionary Learning with Sparseness-Enforcing Projections
Apr 16, 2016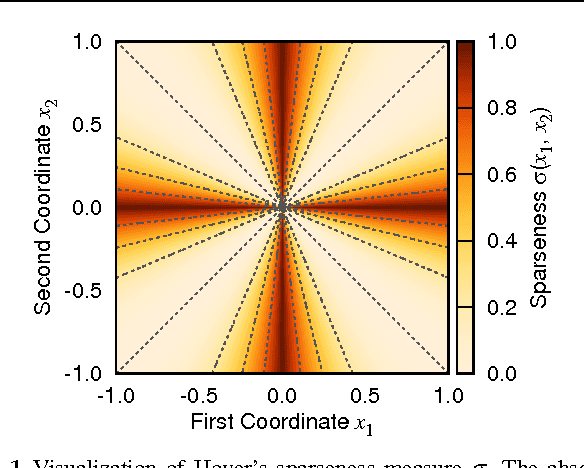
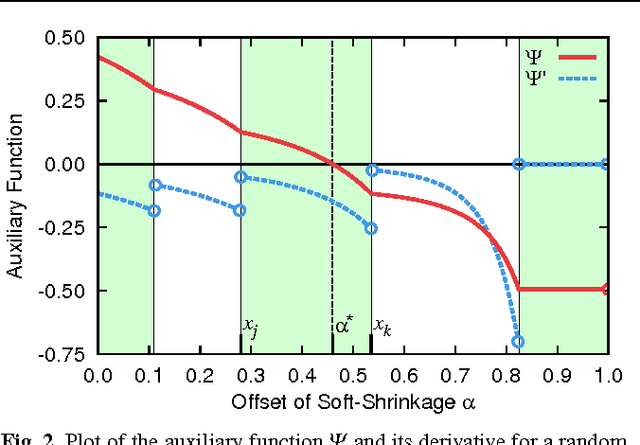
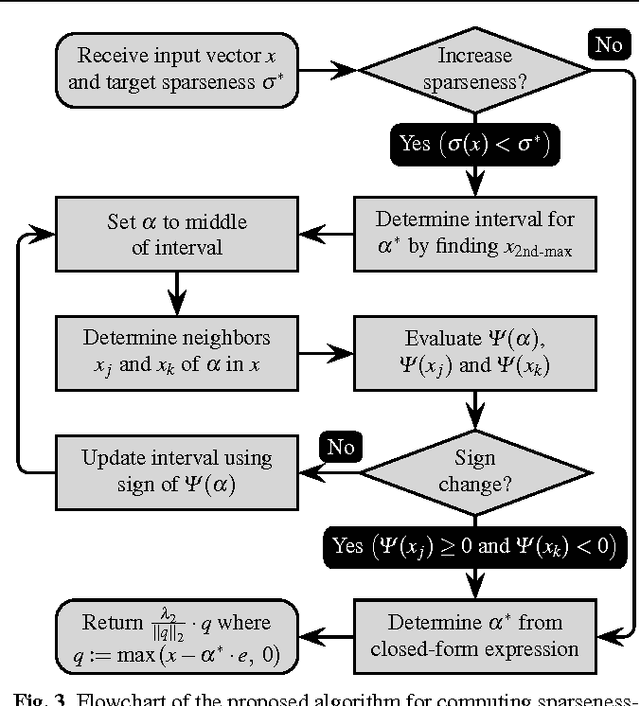
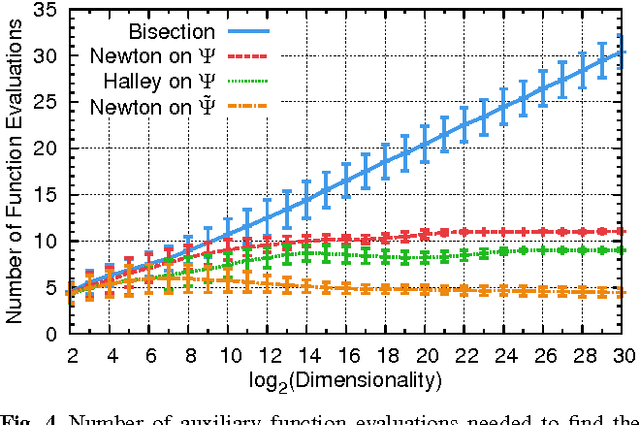
Learning dictionaries suitable for sparse coding instead of using engineered bases has proven effective in a variety of image processing tasks. This paper studies the optimization of dictionaries on image data where the representation is enforced to be explicitly sparse with respect to a smooth, normalized sparseness measure. This involves the computation of Euclidean projections onto level sets of the sparseness measure. While previous algorithms for this optimization problem had at least quasi-linear time complexity, here the first algorithm with linear time complexity and constant space complexity is proposed. The key for this is the mathematically rigorous derivation of a characterization of the projection's result based on a soft-shrinkage function. This theory is applied in an original algorithm called Easy Dictionary Learning (EZDL), which learns dictionaries with a simple and fast-to-compute Hebbian-like learning rule. The new algorithm is efficient, expressive and particularly simple to implement. It is demonstrated that despite its simplicity, the proposed learning algorithm is able to generate a rich variety of dictionaries, in particular a topographic organization of atoms or separable atoms. Further, the dictionaries are as expressive as those of benchmark learning algorithms in terms of the reproduction quality on entire images, and result in an equivalent denoising performance. EZDL learns approximately 30 % faster than the already very efficient Online Dictionary Learning algorithm, and is therefore eligible for rapid data set analysis and problems with vast quantities of learning samples.
* The final publication is available at Springer via http://dx.doi.org/10.1007/s11263-015-0799-8
Sparse Activity and Sparse Connectivity in Supervised Learning
Mar 28, 2016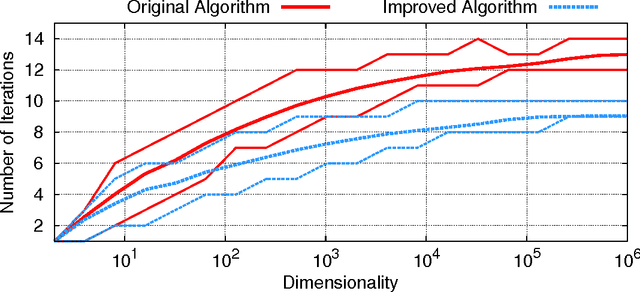



Sparseness is a useful regularizer for learning in a wide range of applications, in particular in neural networks. This paper proposes a model targeted at classification tasks, where sparse activity and sparse connectivity are used to enhance classification capabilities. The tool for achieving this is a sparseness-enforcing projection operator which finds the closest vector with a pre-defined sparseness for any given vector. In the theoretical part of this paper, a comprehensive theory for such a projection is developed. In conclusion, it is shown that the projection is differentiable almost everywhere and can thus be implemented as a smooth neuronal transfer function. The entire model can hence be tuned end-to-end using gradient-based methods. Experiments on the MNIST database of handwritten digits show that classification performance can be boosted by sparse activity or sparse connectivity. With a combination of both, performance can be significantly better compared to classical non-sparse approaches.
* See http://jmlr.org/papers/v14/thom13a.html for the authoritative version