 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Window Validity Problem in Rule-Based Stream Reasoning
Aug 07, 2018Rule-based temporal query languages provide the expressive power and flexibility required to capture in a natural way complex analysis tasks over streaming data. Stream processing applications, however, typically require near real-time response using limited resources. In particular, it becomes essential that the underpinning query language has favourable computational properties and that stream processing algorithms are able to keep only a small number of previously received facts in memory at any point in time without sacrificing correctness. In this paper, we propose a recursive fragment of temporal Datalog with tractable data complexity and study the properties of a generic stream reasoning algorithm for this fragment. We focus on the window validity problem as a way to minimise the number of time points for which the stream reasoning algorithm needs to keep data in memory at any point in time.
Stratified Negation in Limit Datalog Programs
Apr 25, 2018There has recently been an increasing interest in declarative data analysis, where analytic tasks are specified using a logical language, and their implementation and optimisation are delegated to a general-purpose query engine. Existing declarative languages for data analysis can be formalised as variants of logic programming equipped with arithmetic function symbols and/or aggregation, and are typically undecidable. In prior work, the language of $\mathit{limit\ programs}$ was proposed, which is sufficiently powerful to capture many analysis tasks and has decidable entailment problem. Rules in this language, however, do not allow for negation. In this paper, we study an extension of limit programs with stratified negation-as-failure. We show that the additional expressive power makes reasoning computationally more demanding, and provide tight data complexity bounds. We also identify a fragment with tractable data complexity and sufficient expressivity to capture many relevant tasks.
Foundations of Declarative Data Analysis Using Limit Datalog Programs
Nov 12, 2017Motivated by applications in declarative data analysis, we study $\mathit{Datalog}_{\mathbb{Z}}$---an extension of positive Datalog with arithmetic functions over integers. This language is known to be undecidable, so we propose two fragments. In $\mathit{limit}~\mathit{Datalog}_{\mathbb{Z}}$ predicates are axiomatised to keep minimal/maximal numeric values, allowing us to show that fact entailment is coNExpTime-complete in combined, and coNP-complete in data complexity. Moreover, an additional $\mathit{stability}$ requirement causes the complexity to drop to ExpTime and PTime, respectively. Finally, we show that stable $\mathit{Datalog}_{\mathbb{Z}}$ can express many useful data analysis tasks, and so our results provide a sound foundation for the development of advanced information systems.
Stream Reasoning in Temporal Datalog
Nov 10, 2017In recent years, there has been an increasing interest in extending traditional stream processing engines with logical, rule-based, reasoning capabilities. This poses significant theoretical and practical challenges since rules can derive new information and propagate it both towards past and future time points; as a result, streamed query answers can depend on data that has not yet been received, as well as on data that arrived far in the past. Stream reasoning algorithms, however, must be able to stream out query answers as soon as possible, and can only keep a limited number of previous input facts in memory. In this paper, we propose novel reasoning problems to deal with these challenges, and study their computational properties on Datalog extended with a temporal sort and the successor function (a core rule-based language for stream reasoning applications).
The Bag Semantics of Ontology-Based Data Access
May 19, 2017Ontology-based data access (OBDA) is a popular approach for integrating and querying multiple data sources by means of a shared ontology. The ontology is linked to the sources using mappings, which assign views over the data to ontology predicates. Motivated by the need for OBDA systems supporting database-style aggregate queries, we propose a bag semantics for OBDA, where duplicate tuples in the views defined by the mappings are retained, as is the case in standard databases. We show that bag semantics makes conjunctive query answering in OBDA coNP-hard in data complexity. To regain tractability, we consider a rather general class of queries and show its rewritability to a generalisation of the relational calculus to bags.
Computing Horn Rewritings of Description Logics Ontologies
Apr 21, 2015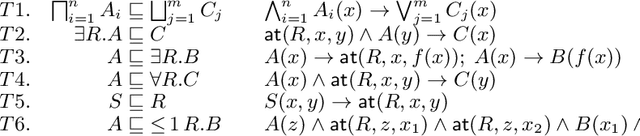
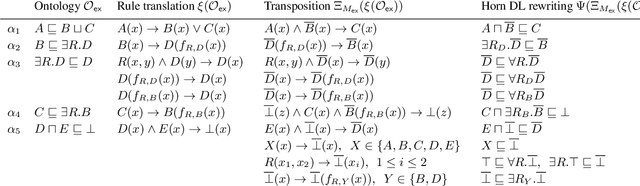
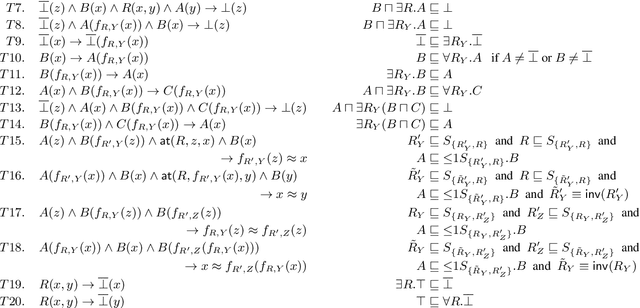
We study the problem of rewriting an ontology O1 expressed in a DL L1 into an ontology O2 in a Horn DL L2 such that O1 and O2 are equisatisfiable when extended with an arbitrary dataset. Ontologies that admit such rewritings are amenable to reasoning techniques ensuring tractability in data complexity. After showing undecidability whenever L1 extends ALCF, we focus on devising efficiently checkable conditions that ensure existence of a Horn rewriting. By lifting existing techniques for rewriting Disjunctive Datalog programs into plain Datalog to the case of arbitrary first-order programs with function symbols, we identify a class of ontologies that admit Horn rewritings of polynomial size. Our experiments indicate that many real-world ontologies satisfy our sufficient conditions and thus admit polynomial Horn rewritings.
Ontology Module Extraction via Datalog Reasoning
Nov 20, 2014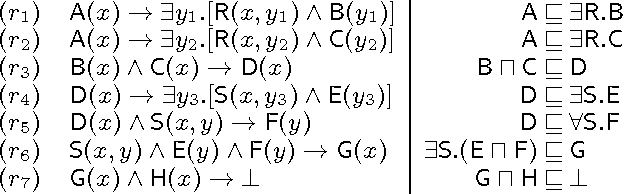
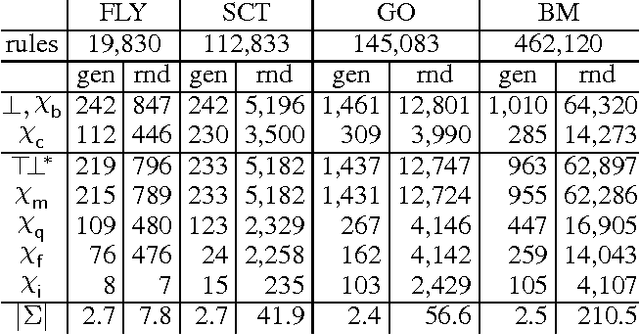
Module extraction - the task of computing a (preferably small) fragment M of an ontology T that preserves entailments over a signature S - has found many applications in recent years. Extracting modules of minimal size is, however, computationally hard, and often algorithmically infeasible. Thus, practical techniques are based on approximations, where M provably captures the relevant entailments, but is not guaranteed to be minimal. Existing approximations, however, ensure that M preserves all second-order entailments of T w.r.t. S, which is stronger than is required in many applications, and may lead to large modules in practice. In this paper we propose a novel approach in which module extraction is reduced to a reasoning problem in datalog. Our approach not only generalises existing approximations in an elegant way, but it can also be tailored to preserve only specific kinds of entailments, which allows us to extract significantly smaller modules. An evaluation on widely-used ontologies has shown very encouraging results.
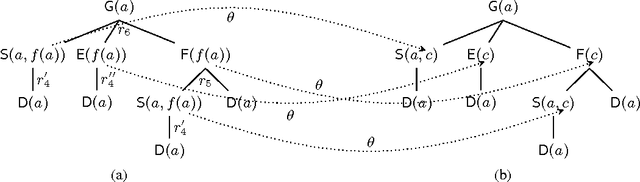
Datalog Rewritability of Disjunctive Datalog Programs and its Applications to Ontology Reasoning
Apr 11, 2014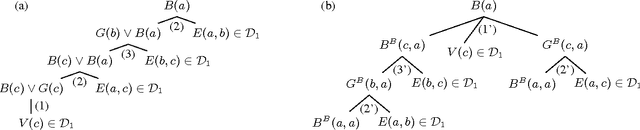


We study the problem of rewriting a disjunctive datalog program into plain datalog. We show that a disjunctive program is rewritable if and only if it is equivalent to a linear disjunctive program, thus providing a novel characterisation of datalog rewritability. Motivated by this result, we propose weakly linear disjunctive datalog---a novel rule-based KR language that extends both datalog and linear disjunctive datalog and for which reasoning is tractable in data complexity. We then explore applications of weakly linear programs to ontology reasoning and propose a tractable extension of OWL 2 RL with disjunctive axioms. Our empirical results suggest that many non-Horn ontologies can be reduced to weakly linear programs and that query answering over such ontologies using a datalog engine is feasible in practice.