 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Bag Semantics of Ontology-Based Data Access
May 19, 2017Ontology-based data access (OBDA) is a popular approach for integrating and querying multiple data sources by means of a shared ontology. The ontology is linked to the sources using mappings, which assign views over the data to ontology predicates. Motivated by the need for OBDA systems supporting database-style aggregate queries, we propose a bag semantics for OBDA, where duplicate tuples in the views defined by the mappings are retained, as is the case in standard databases. We show that bag semantics makes conjunctive query answering in OBDA coNP-hard in data complexity. To regain tractability, we consider a rather general class of queries and show its rewritability to a generalisation of the relational calculus to bags.
Towards Analytics Aware Ontology Based Access to Static and Streaming Data (Extended Version)
Aug 15, 2016
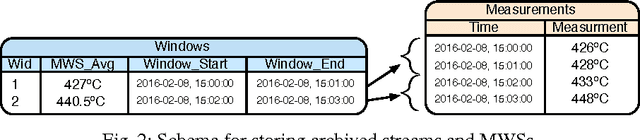
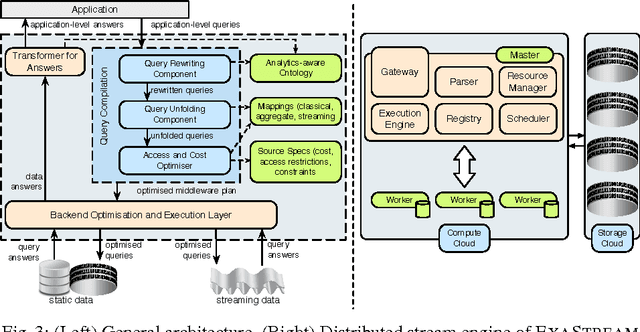
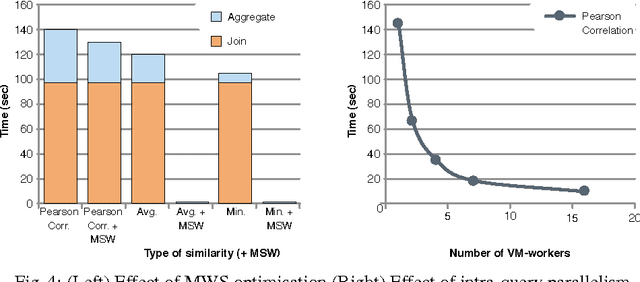
Real-time analytics that requires integration and aggregation of heterogeneous and distributed streaming and static data is a typical task in many industrial scenarios such as diagnostics of turbines in Siemens. OBDA approach has a great potential to facilitate such tasks; however, it has a number of limitations in dealing with analytics that restrict its use in important industrial applications. Based on our experience with Siemens, we argue that in order to overcome those limitations OBDA should be extended and become analytics, source, and cost aware. In this work we propose such an extension. In particular, we propose an ontology, mapping, and query language for OBDA, where aggregate and other analytical functions are first class citizens. Moreover, we develop query optimisation techniques that allow to efficiently process analytical tasks over static and streaming data. We implement our approach in a system and evaluate our system with Siemens turbine data.