 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Group Level Insights with Accordant Clustering
Apr 07, 2017
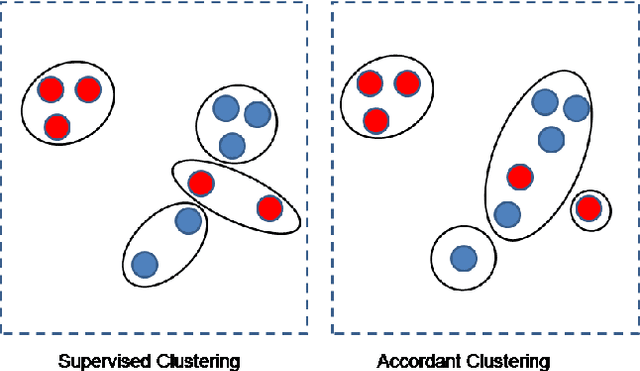


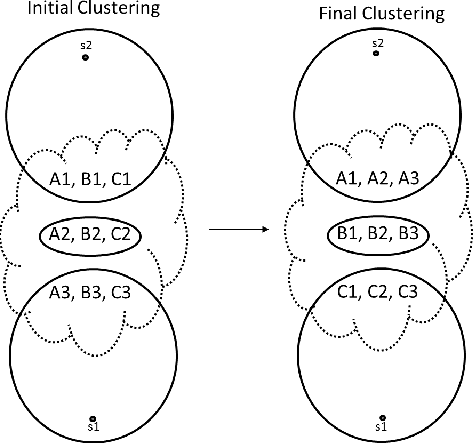
Clustering is a widely-used data mining tool, which aims to discover partitions of similar items in data. We introduce a new clustering paradigm, \emph{accordant clustering}, which enables the discovery of (predefined) group level insights. Unlike previous clustering paradigms that aim to understand relationships amongst the individual members, the goal of accordant clustering is to uncover insights at the group level through the analysis of their members. Group level insight can often support a call to action that cannot be informed through previous clustering techniques. We propose the first accordant clustering algorithm, and prove that it finds near-optimal solutions when data possesses inherent cluster structure. The insights revealed by accordant clusterings enabled experts in the field of medicine to isolate successful treatments for a neurodegenerative disease, and those in finance to discover patterns of unnecessary spending.
Algorithmic Songwriting with ALYSIA
Dec 04, 2016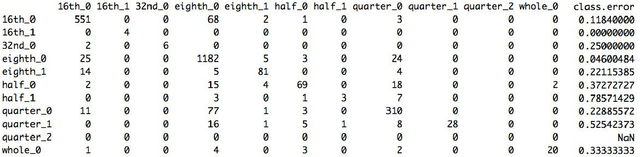
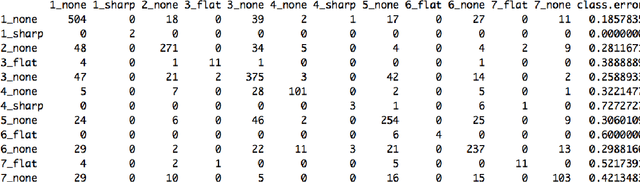
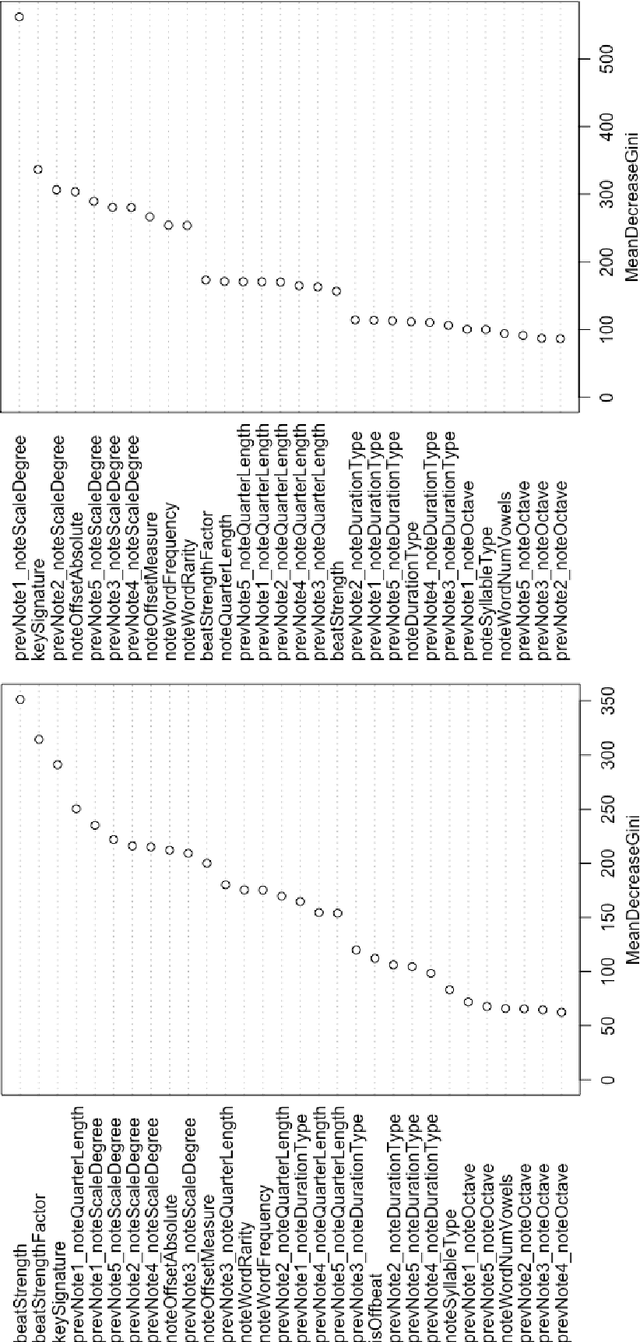

This paper introduces ALYSIA: Automated LYrical SongwrIting Application. ALYSIA is based on a machine learning model using Random Forests, and we discuss its success at pitch and rhythm prediction. Next, we show how ALYSIA was used to create original pop songs that were subsequently recorded and produced. Finally, we discuss our vision for the future of Automated Songwriting for both co-creative and autonomous systems.
Weighted Clustering
Oct 04, 2016
One of the most prominent challenges in clustering is "the user's dilemma," which is the problem of selecting an appropriate clustering algorithm for a specific task. A formal approach for addressing this problem relies on the identification of succinct, user-friendly properties that formally capture when certain clustering methods are preferred over others. Until now these properties focused on advantages of classical Linkage-Based algorithms, failing to identify when other clustering paradigms, such as popular center-based methods, are preferable. We present surprisingly simple new properties that delineate the differences between common clustering paradigms, which clearly and formally demonstrates advantages of center-based approaches for some applications. These properties address how sensitive algorithms are to changes in element frequencies, which we capture in a generalized setting where every element is associated with a real-valued weight.
An Effective and Efficient Approach for Clusterability Evaluation
Feb 22, 2016

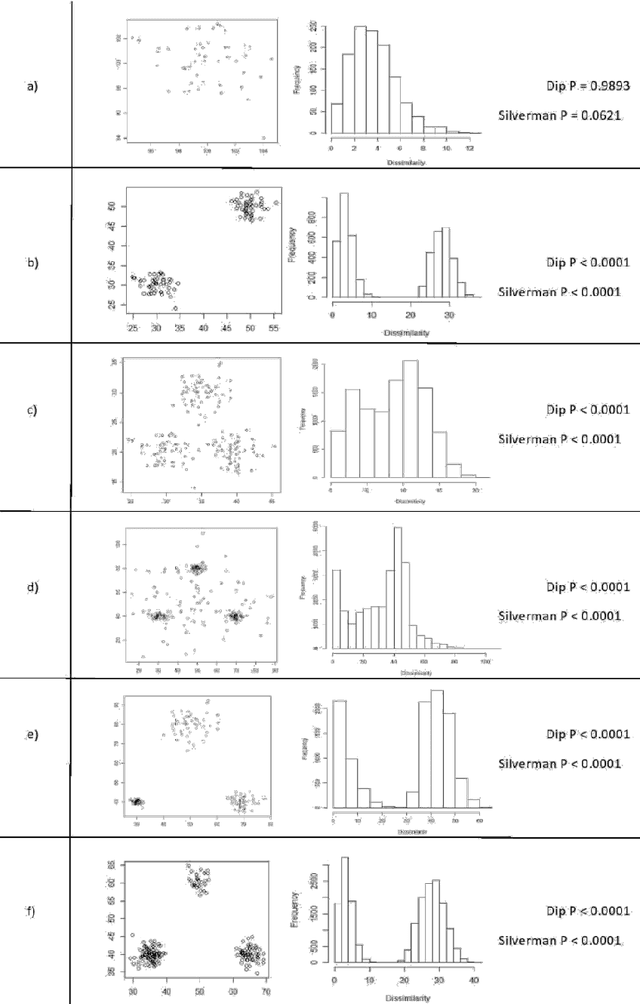
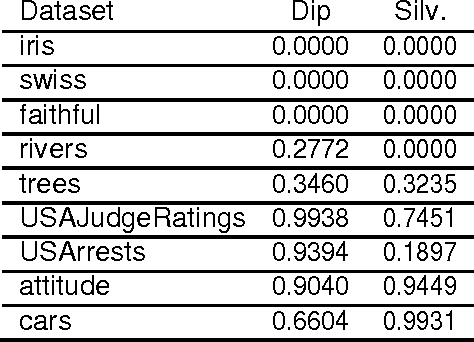
Clustering is an essential data mining tool that aims to discover inherent cluster structure in data. As such, the study of clusterability, which evaluates whether data possesses such structure, is an integral part of cluster analysis. Yet, despite their central role in the theory and application of clustering, current notions of clusterability fall short in two crucial aspects that render them impractical; most are computationally infeasible and others fail to classify the structure of real datasets. In this paper, we propose a novel approach to clusterability evaluation that is both computationally efficient and successfully captures the structure of real data. Our method applies multimodality tests to the (one-dimensional) set of pairwise distances based on the original, potentially high-dimensional data. We present extensive analyses of our approach for both the Dip and Silverman multimodality tests on real data as well as 17,000 simulations, demonstrating the success of our approach as the first practical notion of clusterability.
When is Clustering Perturbation Robust?
Jan 22, 2016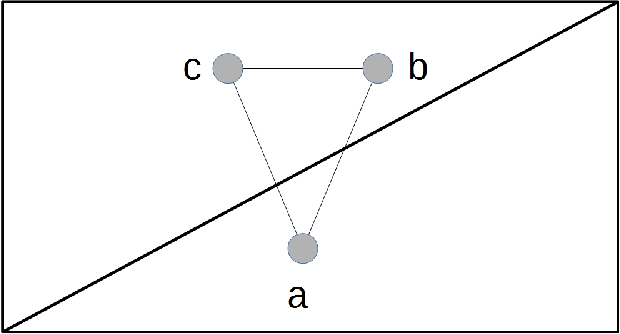
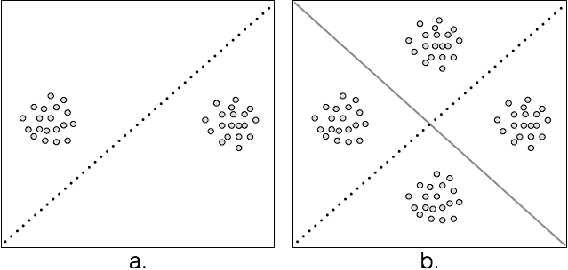
Clustering is a fundamental data mining tool that aims to divide data into groups of similar items. Generally, intuition about clustering reflects the ideal case -- exact data sets endowed with flawless dissimilarity between individual instances. In practice however, these cases are in the minority, and clustering applications are typically characterized by noisy data sets with approximate pairwise dissimilarities. As such, the efficacy of clustering methods in practical applications necessitates robustness to perturbations. In this paper, we perform a formal analysis of perturbation robustness, revealing that the extent to which algorithms can exhibit this desirable characteristic is inherently limited, and identifying the types of structures that allow popular clustering paradigms to discover meaningful clusters in spite of faulty data.
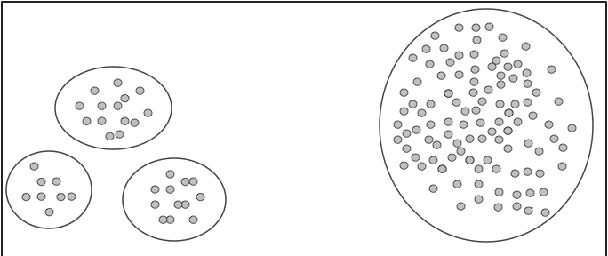
Incremental Clustering: The Case for Extra Clusters
Jun 24, 2014

The explosion in the amount of data available for analysis often necessitates a transition from batch to incremental clustering methods, which process one element at a time and typically store only a small subset of the data. In this paper, we initiate the formal analysis of incremental clustering methods focusing on the types of cluster structure that they are able to detect. We find that the incremental setting is strictly weaker than the batch model, proving that a fundamental class of cluster structures that can readily be detected in the batch setting is impossible to identify using any incremental method. Furthermore, we show how the limitations of incremental clustering can be overcome by allowing additional clusters.