 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective and Efficient Approach for Clusterability Evaluation
Paper and Code
Feb 22, 2016

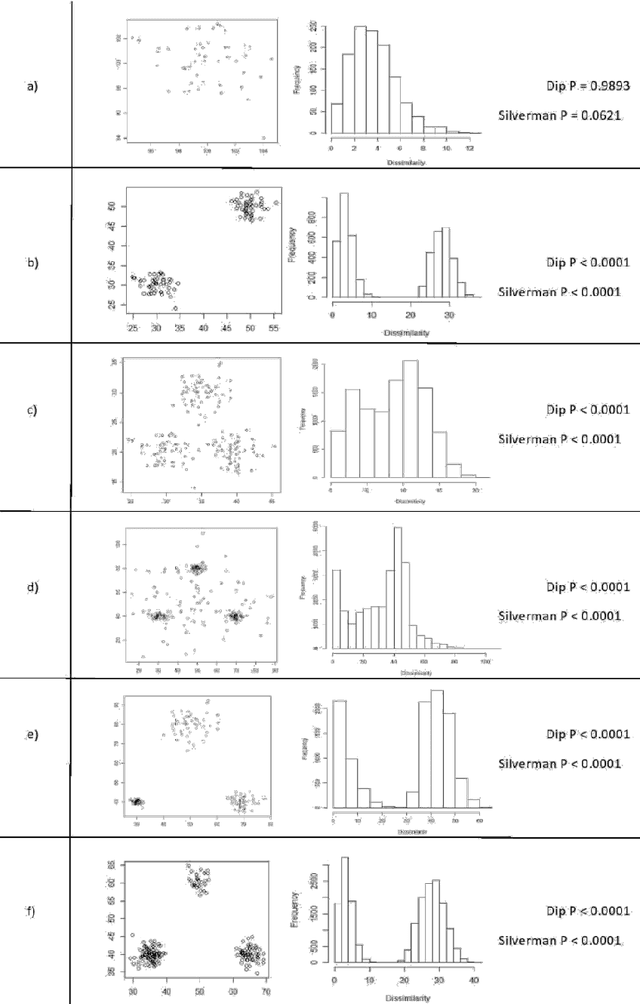
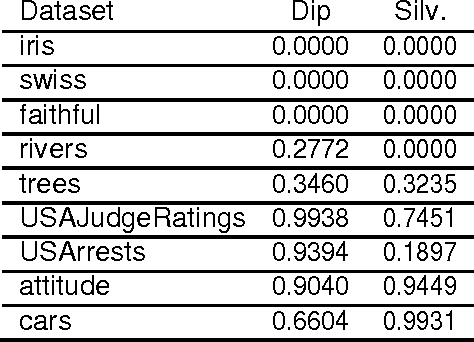
Clustering is an essential data mining tool that aims to discover inherent cluster structure in data. As such, the study of clusterability, which evaluates whether data possesses such structure, is an integral part of cluster analysis. Yet, despite their central role in the theory and application of clustering, current notions of clusterability fall short in two crucial aspects that render them impractical; most are computationally infeasible and others fail to classify the structure of real datasets. In this paper, we propose a novel approach to clusterability evaluation that is both computationally efficient and successfully captures the structure of real data. Our method applies multimodality tests to the (one-dimensional) set of pairwise distances based on the original, potentially high-dimensional data. We present extensive analyses of our approach for both the Dip and Silverman multimodality tests on real data as well as 17,000 simulations, demonstrating the success of our approach as the first practical notion of clusterability.