 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen is Clustering Perturbation Robust?
Paper and Code
Jan 22, 2016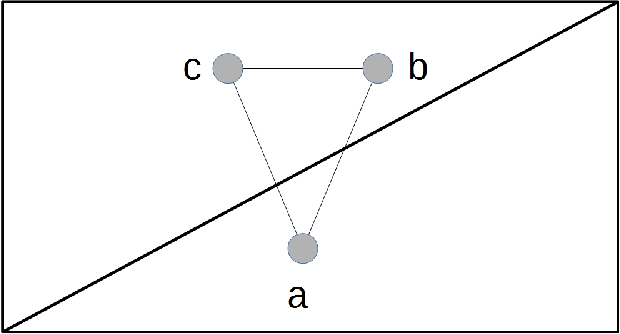
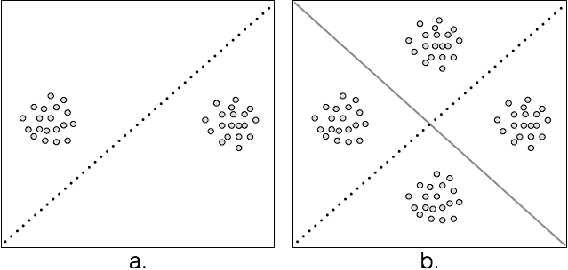
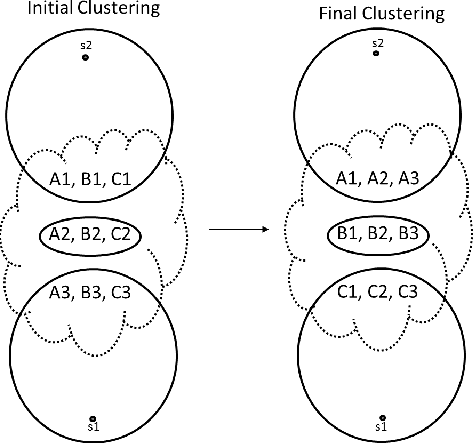
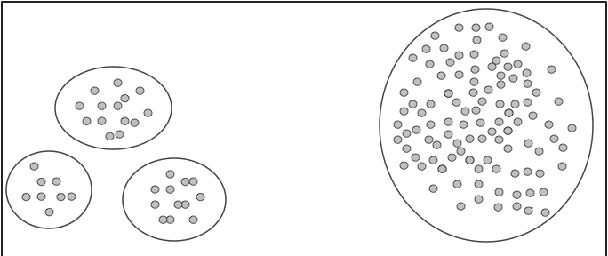
Clustering is a fundamental data mining tool that aims to divide data into groups of similar items. Generally, intuition about clustering reflects the ideal case -- exact data sets endowed with flawless dissimilarity between individual instances. In practice however, these cases are in the minority, and clustering applications are typically characterized by noisy data sets with approximate pairwise dissimilarities. As such, the efficacy of clustering methods in practical applications necessitates robustness to perturbations. In this paper, we perform a formal analysis of perturbation robustness, revealing that the extent to which algorithms can exhibit this desirable characteristic is inherently limited, and identifying the types of structures that allow popular clustering paradigms to discover meaningful clusters in spite of faulty data.