 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Protein Molecular Dynamics Simulation with DeepJump
Sep 16, 2025


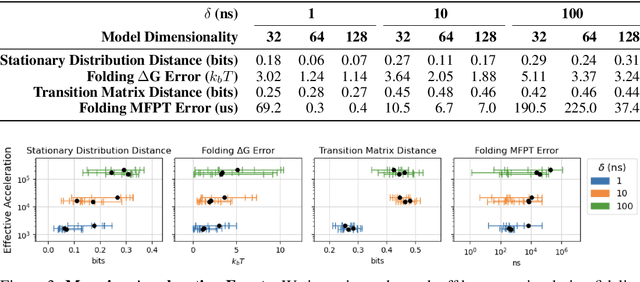
Unraveling the dynamical motions of biomolecules is essential for bridging their structure and function, yet it remains a major computational challenge. Molecular dynamics (MD) simulation provides a detailed depiction of biomolecular motion, but its high-resolution temporal evolution comes at significant computational cost, limiting its applicability to timescales of biological relevance. Deep learning approaches have emerged as promising solutions to overcome these computational limitations by learning to predict long-timescale dynamics. However, generalizable kinetics models for proteins remain largely unexplored, and the fundamental limits of achievable acceleration while preserving dynamical accuracy are poorly understood. In this work, we fill this gap with DeepJump, an Euclidean-Equivariant Flow Matching-based model for predicting protein conformational dynamics across multiple temporal scales. We train DeepJump on trajectories of the diverse proteins of mdCATH, systematically studying our model's performance in generalizing to long-term dynamics of fast-folding proteins and characterizing the trade-off between computational acceleration and prediction accuracy. We demonstrate the application of DeepJump to ab initio folding, showcasing prediction of folding pathways and native states. Our results demonstrate that DeepJump achieves significant $\approx$1000$\times$ computational acceleration while effectively recovering long-timescale dynamics, providing a stepping stone for enabling routine simulation of proteins.
RiboGen: RNA Sequence and Structure Co-Generation with Equivariant MultiFlow
Mar 03, 2025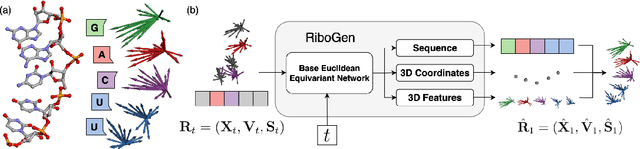
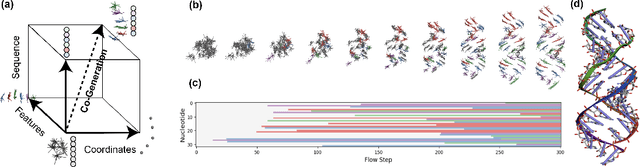
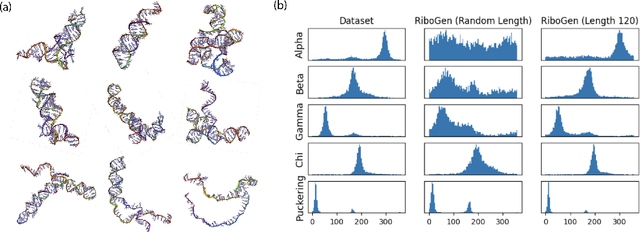
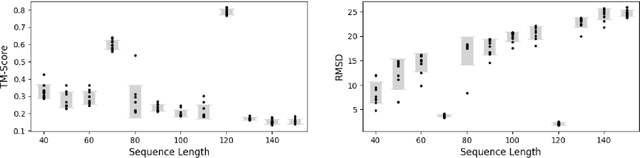
Ribonucleic acid (RNA) plays fundamental roles in biological systems, from carrying genetic information to performing enzymatic function. Understanding and designing RNA can enable novel therapeutic application and biotechnological innovation. To enhance RNA design, in this paper we introduce RiboGen, the first deep learning model to simultaneously generate RNA sequence and all-atom 3D structure. RiboGen leverages the standard Flow Matching with Discrete Flow Matching in a multimodal data representation. RiboGen is based on Euclidean Equivariant neural networks for efficiently processing and learning three-dimensional geometry. Our experiments show that RiboGen can efficiently generate chemically plausible and self-consistent RNA samples. Our results suggest that co-generation of sequence and structure is a competitive approach for modeling RNA.
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Jul 16, 2024There is widespread optimism that frontier Large Language Models (LLMs) and LLM-augmented systems have the potential to rapidly accelerate scientific discovery across disciplines. Today, many benchmarks exist to measure LLM knowledge and reasoning on textbook-style science questions, but few if any benchmarks are designed to evaluate language model performance on practical tasks required for scientific research, such as literature search, protocol planning, and data analysis. As a step toward building such benchmarks, we introduce the Language Agent Biology Benchmark (LAB-Bench), a broad dataset of over 2,400 multiple choice questions for evaluating AI systems on a range of practical biology research capabilities, including recall and reasoning over literature, interpretation of figures, access and navigation of databases, and comprehension and manipulation of DNA and protein sequences. Importantly, in contrast to previous scientific benchmarks, we expect that an AI system that can achieve consistently high scores on the more difficult LAB-Bench tasks would serve as a useful assistant for researchers in areas such as literature search and molecular cloning. As an initial assessment of the emergent scientific task capabilities of frontier language models, we measure performance of several against our benchmark and report results compared to human expert biology researchers. We will continue to update and expand LAB-Bench over time, and expect it to serve as a useful tool in the development of automated research systems going forward. A public subset of LAB-Bench is available for use at the following URL: https://huggingface.co/datasets/futurehouse/lab-bench
Ophiuchus: Scalable Modeling of Protein Structures through Hierarchical Coarse-graining SO(3)-Equivariant Autoencoders
Oct 04, 2023Three-dimensional native states of natural proteins display recurring and hierarchical patterns. Yet, traditional graph-based modeling of protein structures is often limited to operate within a single fine-grained resolution, and lacks hourglass neural architectures to learn those high-level building blocks. We narrow this gap by introducing Ophiuchus, an SO(3)-equivariant coarse-graining model that efficiently operates on all heavy atoms of standard protein residues, while respecting their relevant symmetries. Our model departs from current approaches that employ graph modeling, instead focusing on local convolutional coarsening to model sequence-motif interactions in log-linear length complexity. We train Ophiuchus on contiguous fragments of PDB monomers, investigating its reconstruction capabilities across different compression rates. We examine the learned latent space and demonstrate its prompt usage in conformational interpolation, comparing interpolated trajectories to structure snapshots from the PDBFlex dataset. Finally, we leverage denoising diffusion probabilistic models (DDPM) to efficiently sample readily-decodable latent embeddings of diverse miniproteins. Our experiments demonstrate Ophiuchus to be a scalable basis for efficient protein modeling and generation.