 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-step Inference over Unstructured Data
Jul 08, 2024



The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
Multi-step Knowledge Retrieval and Inference over Unstructured Data
Jun 26, 2024The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
Injecting knowledge into language generation: a case study in auto-charting after-visit care instructions from medical dialogue
Jun 06, 2023



Factual correctness is often the limiting factor in practical applications of natural language generation in high-stakes domains such as healthcare. An essential requirement for maintaining factuality is the ability to deal with rare tokens. This paper focuses on rare tokens that appear in both the source and the reference sequences, and which, when missed during generation, decrease the factual correctness of the output text. For high-stake domains that are also knowledge-rich, we show how to use knowledge to (a) identify which rare tokens that appear in both source and reference are important and (b) uplift their conditional probability. We introduce the ``utilization rate'' that encodes knowledge and serves as a regularizer by maximizing the marginal probability of selected tokens. We present a study in a knowledge-rich domain of healthcare, where we tackle the problem of generating after-visit care instructions based on patient-doctor dialogues. We verify that, in our dataset, specific medical concepts with high utilization rates are underestimated by conventionally trained sequence-to-sequence models. We observe that correcting this with our approach to knowledge injection reduces the uncertainty of the model as well as improves factuality and coherence without negatively impacting fluency.
Characterizing and addressing the issue of oversmoothing in neural autoregressive sequence modeling
Dec 22, 2021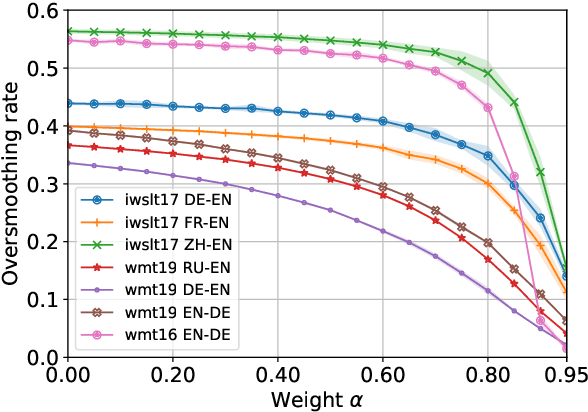
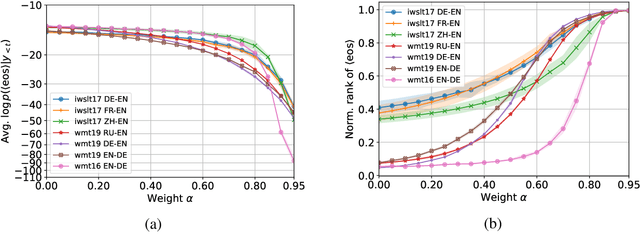
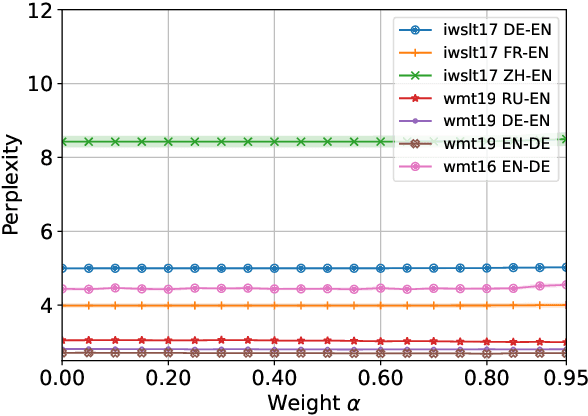
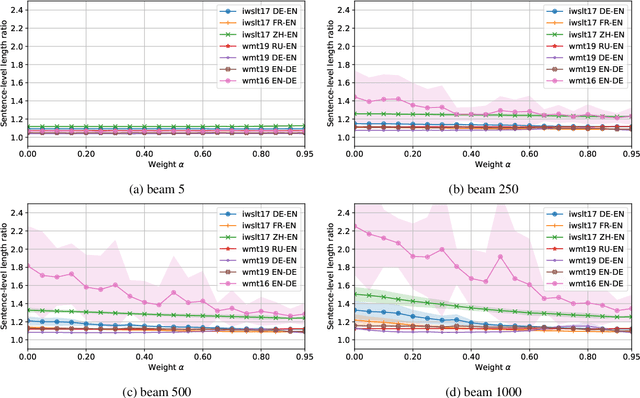
Neural autoregressive sequence models smear the probability among many possible sequences including degenerate ones, such as empty or repetitive sequences. In this work, we tackle one specific case where the model assigns a high probability to unreasonably short sequences. We define the oversmoothing rate to quantify this issue. After confirming the high degree of oversmoothing in neural machine translation, we propose to explicitly minimize the oversmoothing rate during training. We conduct a set of experiments to study the effect of the proposed regularization on both model distribution and decoding performance. We use a neural machine translation task as the testbed and consider three different datasets of varying size. Our experiments reveal three major findings. First, we can control the oversmoothing rate of the model by tuning the strength of the regularization. Second, by enhancing the oversmoothing loss contribution, the probability and the rank of <eos> token decrease heavily at positions where it is not supposed to be. Third, the proposed regularization impacts the outcome of beam search especially when a large beam is used. The degradation of translation quality (measured in BLEU) with a large beam significantly lessens with lower oversmoothing rate, but the degradation compared to smaller beam sizes remains to exist. From these observations, we conclude that the high degree of oversmoothing is the main reason behind the degenerate case of overly probable short sequences in a neural autoregressive model.