 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and addressing the issue of oversmoothing in neural autoregressive sequence modeling
Paper and Code
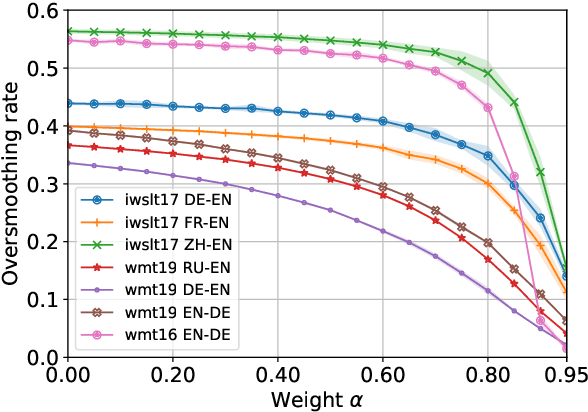
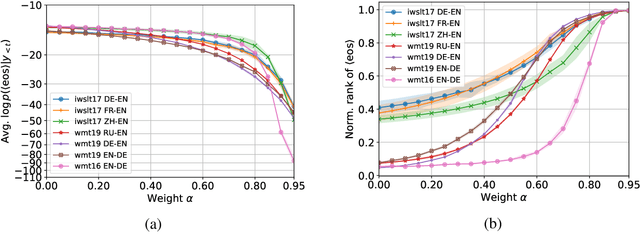
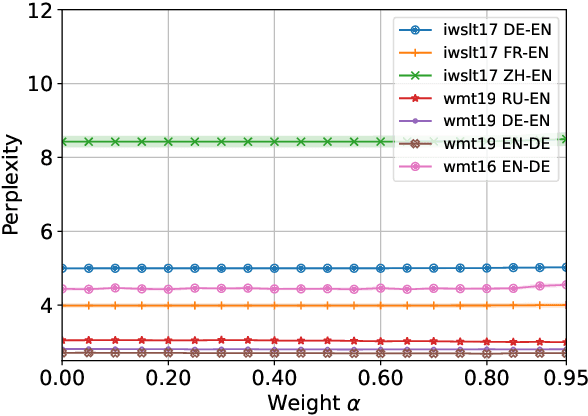
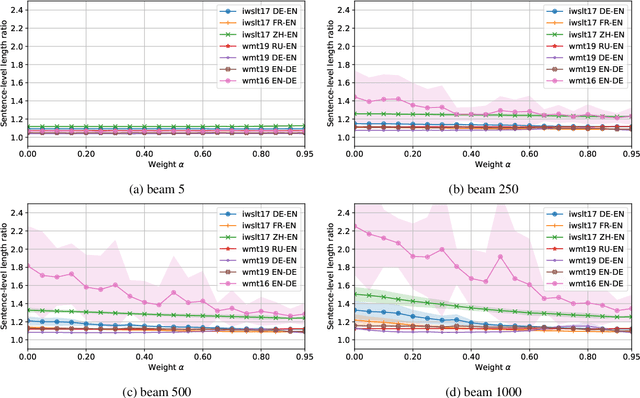
Neural autoregressive sequence models smear the probability among many possible sequences including degenerate ones, such as empty or repetitive sequences. In this work, we tackle one specific case where the model assigns a high probability to unreasonably short sequences. We define the oversmoothing rate to quantify this issue. After confirming the high degree of oversmoothing in neural machine translation, we propose to explicitly minimize the oversmoothing rate during training. We conduct a set of experiments to study the effect of the proposed regularization on both model distribution and decoding performance. We use a neural machine translation task as the testbed and consider three different datasets of varying size. Our experiments reveal three major findings. First, we can control the oversmoothing rate of the model by tuning the strength of the regularization. Second, by enhancing the oversmoothing loss contribution, the probability and the rank of <eos> token decrease heavily at positions where it is not supposed to be. Third, the proposed regularization impacts the outcome of beam search especially when a large beam is used. The degradation of translation quality (measured in BLEU) with a large beam significantly lessens with lower oversmoothing rate, but the degradation compared to smaller beam sizes remains to exist. From these observations, we conclude that the high degree of oversmoothing is the main reason behind the degenerate case of overly probable short sequences in a neural autoregressive model.