 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-step Inference over Unstructured Data
Jul 08, 2024



The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
Multi-step Knowledge Retrieval and Inference over Unstructured Data
Jun 26, 2024The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
LLM-ARC: Enhancing LLMs with an Automated Reasoning Critic
Jun 25, 2024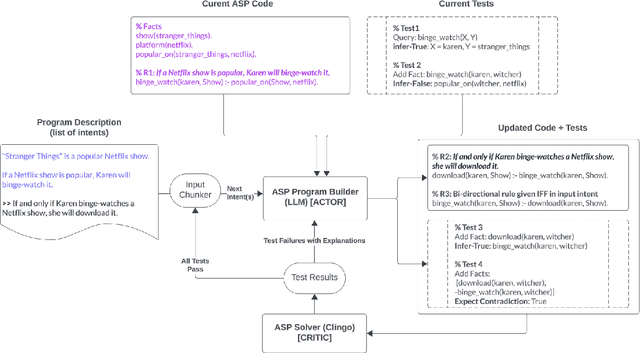
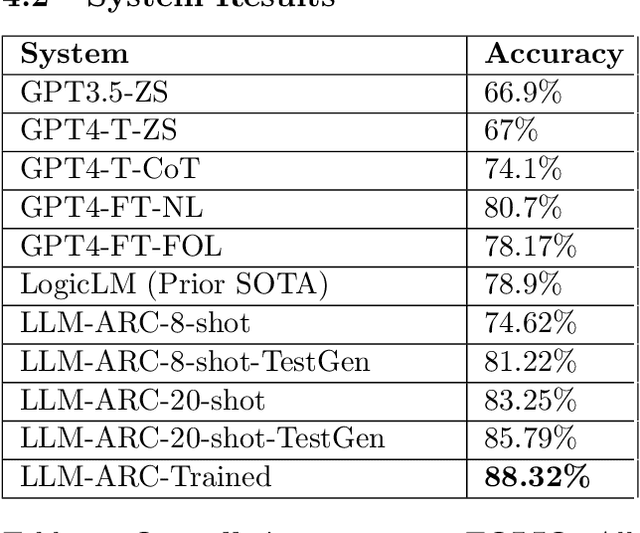
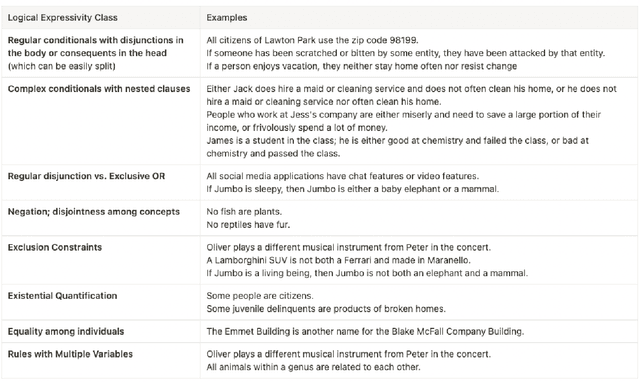

We introduce LLM-ARC, a neuro-symbolic framework designed to enhance the logical reasoning capabilities of Large Language Models (LLMs), by combining them with an Automated Reasoning Critic (ARC). LLM-ARC employs an Actor-Critic method where the LLM Actor generates declarative logic programs along with tests for semantic correctness, while the Automated Reasoning Critic evaluates the code, runs the tests and provides feedback on test failures for iterative refinement. Implemented using Answer Set Programming (ASP), LLM-ARC achieves a new state-of-the-art accuracy of 88.32% on the FOLIO benchmark which tests complex logical reasoning capabilities. Our experiments demonstrate significant improvements over LLM-only baselines, highlighting the importance of logic test generation and iterative self-refinement. We achieve our best result using a fully automated self-supervised training loop where the Actor is trained on end-to-end dialog traces with Critic feedback. We discuss potential enhancements and provide a detailed error analysis, showcasing the robustness and efficacy of LLM-ARC for complex natural language reasoning tasks.
Beyond LLMs: Advancing the Landscape of Complex Reasoning
Feb 12, 2024
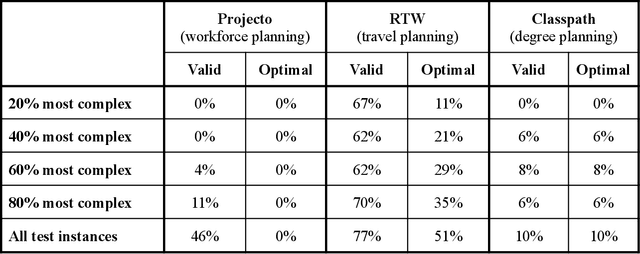


Since the advent of Large Language Models a few years ago, they have often been considered the de facto solution for many AI problems. However, in addition to the many deficiencies of LLMs that prevent them from broad industry adoption, such as reliability, cost, and speed, there is a whole class of common real world problems that Large Language Models perform poorly on, namely, constraint satisfaction and optimization problems. These problems are ubiquitous and current solutions are highly specialized and expensive to implement. At Elemental Cognition, we developed our EC AI platform which takes a neuro-symbolic approach to solving constraint satisfaction and optimization problems. The platform employs, at its core, a precise and high performance logical reasoning engine, and leverages LLMs for knowledge acquisition and user interaction. This platform supports developers in specifying application logic in natural and concise language while generating application user interfaces to interact with users effectively. We evaluated LLMs against systems built on the EC AI platform in three domains and found the EC AI systems to significantly outperform LLMs on constructing valid and optimal solutions, on validating proposed solutions, and on repairing invalid solutions.
Braid: Weaving Symbolic and Neural Knowledge into Coherent Logical Explanations
Dec 11, 2020

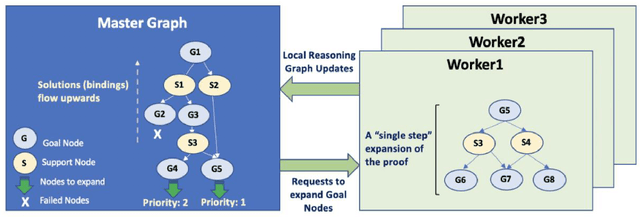

Traditional symbolic reasoning engines, while attractive for their precision and explicability, have a few major drawbacks: the use of brittle inference procedures that rely on exact matching (unification) of logical terms, an inability to deal with uncertainty, and the need for a precompiled rule-base of knowledge (the "knowledge acquisition" problem). These issues are particularly severe for the Natural Language Understanding (NLU) task, where we often use implicit background knowledge to understand and reason about text, resort to fuzzy alignment of concepts and relations during reasoning, and constantly deal with ambiguity in representations. To address these issues, we devise a novel FOL-based reasoner, called Braid, that supports probabilistic rules, and uses the notion of custom unification functions and dynamic rule generation to overcome the brittle matching and knowledge-gap problem prevalent in traditional reasoners. In this paper, we describe the reasoning algorithms used in Braid-BC (the backchaining component of Braid), and their implementation in a distributed task-based framework that builds proof/explanation graphs for an input query in a scalable manner. We use a simple QA example from a children's story to motivate Braid-BC's design and explain how the various components work together to produce a coherent logical explanation.
To Test Machine Comprehension, Start by Defining Comprehension
May 11, 2020
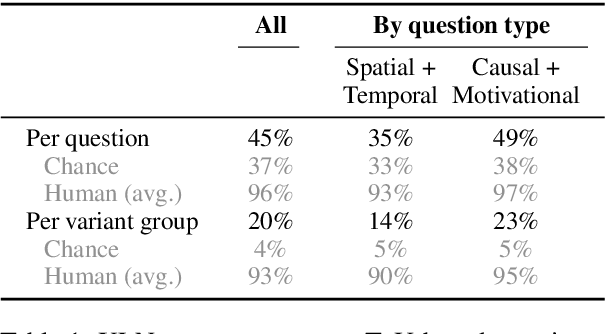

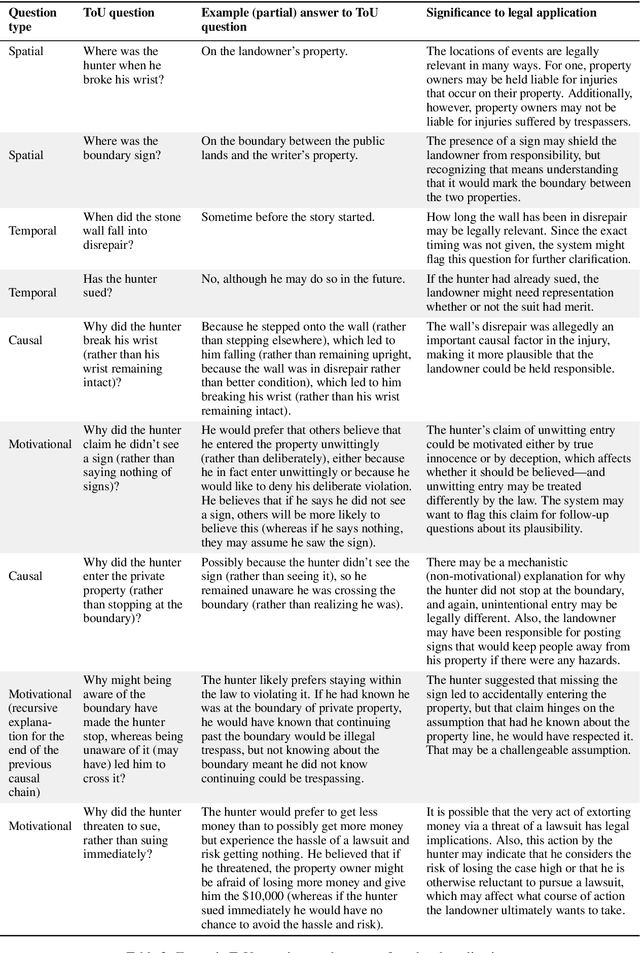
Many tasks aim to measure machine reading comprehension (MRC), often focusing on question types presumed to be difficult. Rarely, however, do task designers start by considering what systems should in fact comprehend. In this paper we make two key contributions. First, we argue that existing approaches do not adequately define comprehension; they are too unsystematic about what content is tested. Second, we present a detailed definition of comprehension -- a "Template of Understanding" -- for a widely useful class of texts, namely short narratives. We then conduct an experiment that strongly suggests existing systems are not up to the task of narrative understanding as we define it.