Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Test Machine Comprehension, Start by Defining Comprehension
Paper and Code
May 11, 2020
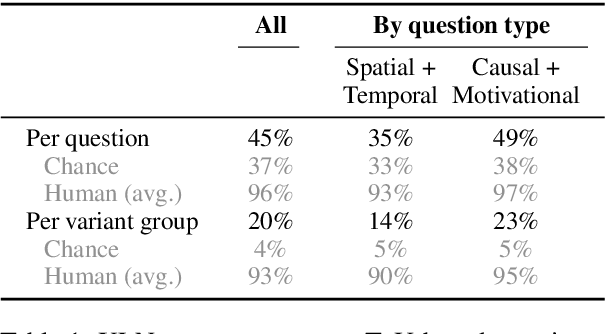

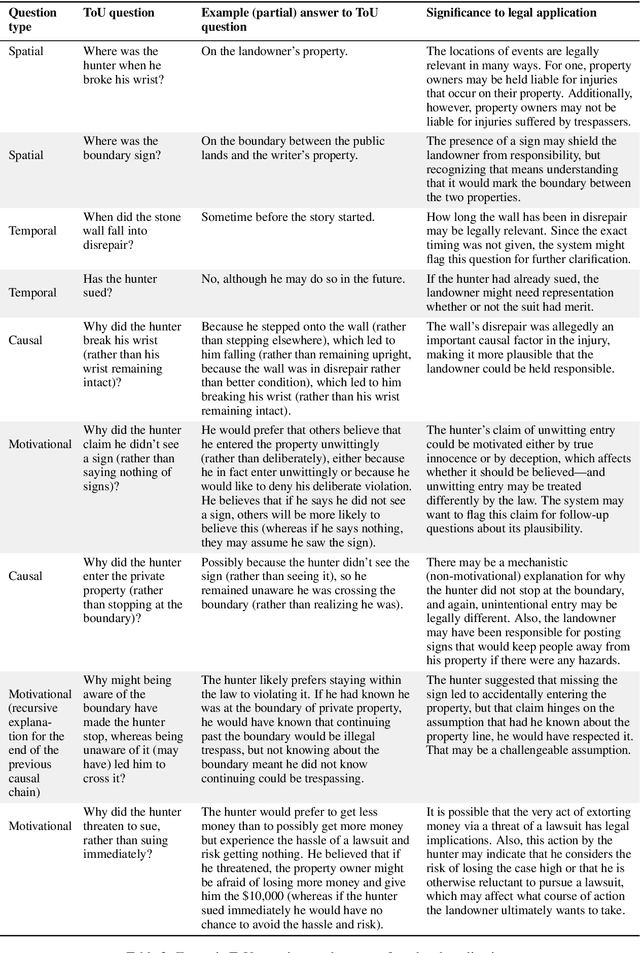
Many tasks aim to measure machine reading comprehension (MRC), often focusing on question types presumed to be difficult. Rarely, however, do task designers start by considering what systems should in fact comprehend. In this paper we make two key contributions. First, we argue that existing approaches do not adequately define comprehension; they are too unsystematic about what content is tested. Second, we present a detailed definition of comprehension -- a "Template of Understanding" -- for a widely useful class of texts, namely short narratives. We then conduct an experiment that strongly suggests existing systems are not up to the task of narrative understanding as we define it.
* Camera-ready ACL 2020 paper (Theme track). 9 pages; 3 figures; 1
table
View paper on