 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-ARC: Enhancing LLMs with an Automated Reasoning Critic
Paper and Code
Jun 25, 2024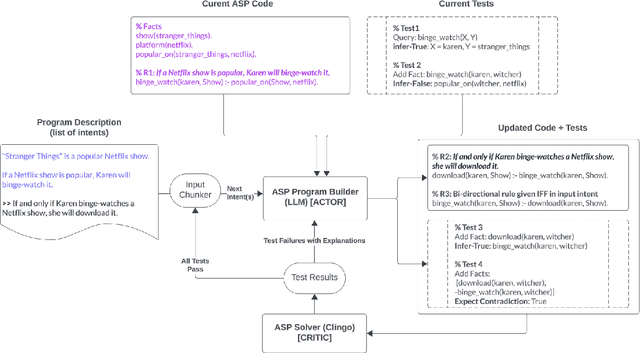
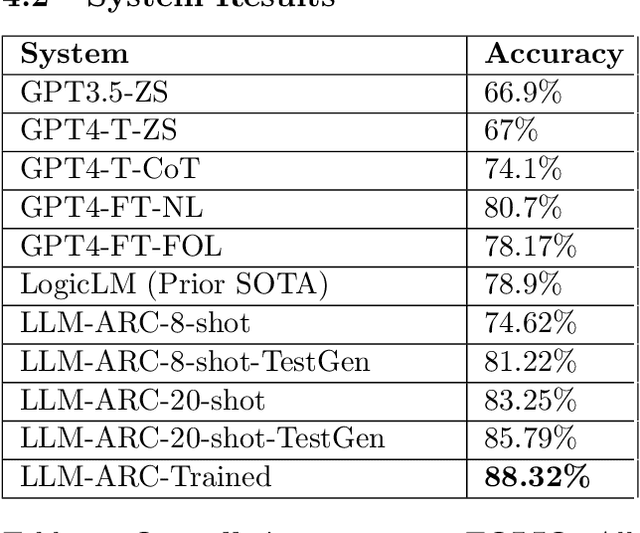
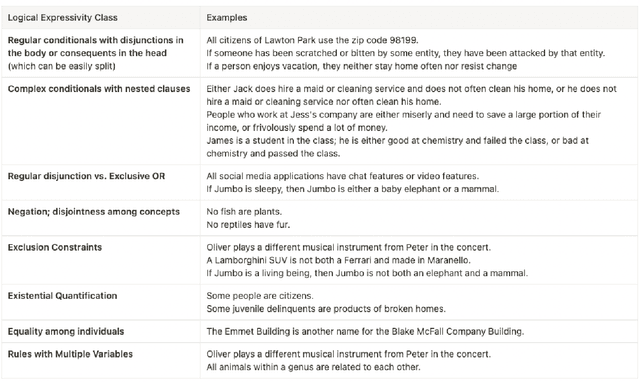

We introduce LLM-ARC, a neuro-symbolic framework designed to enhance the logical reasoning capabilities of Large Language Models (LLMs), by combining them with an Automated Reasoning Critic (ARC). LLM-ARC employs an Actor-Critic method where the LLM Actor generates declarative logic programs along with tests for semantic correctness, while the Automated Reasoning Critic evaluates the code, runs the tests and provides feedback on test failures for iterative refinement. Implemented using Answer Set Programming (ASP), LLM-ARC achieves a new state-of-the-art accuracy of 88.32% on the FOLIO benchmark which tests complex logical reasoning capabilities. Our experiments demonstrate significant improvements over LLM-only baselines, highlighting the importance of logic test generation and iterative self-refinement. We achieve our best result using a fully automated self-supervised training loop where the Actor is trained on end-to-end dialog traces with Critic feedback. We discuss potential enhancements and provide a detailed error analysis, showcasing the robustness and efficacy of LLM-ARC for complex natural language reasoning tasks.