 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-step Inference over Unstructured Data
Jul 08, 2024



The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
Multi-step Knowledge Retrieval and Inference over Unstructured Data
Jun 26, 2024The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
SKATE: A Natural Language Interface for Encoding Structured Knowledge
Oct 20, 2020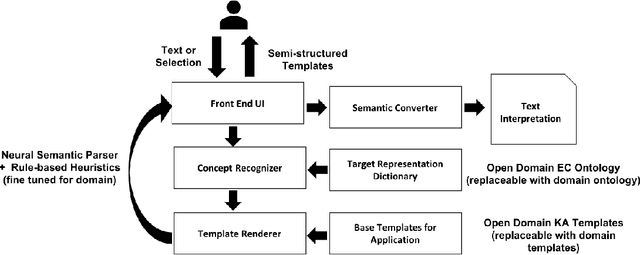


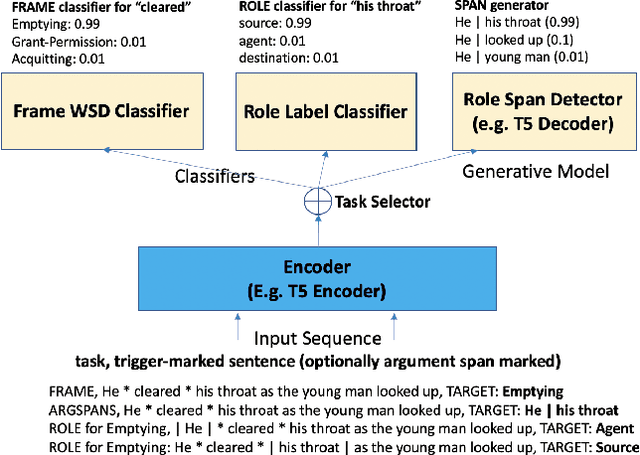
In Natural Language (NL) applications, there is often a mismatch between what the NL interface is capable of interpreting and what a lay user knows how to express. This work describes a novel natural language interface that reduces this mismatch by refining natural language input through successive, automatically generated semi-structured templates. In this paper we describe how our approach, called SKATE, uses a neural semantic parser to parse NL input and suggest semi-structured templates, which are recursively filled to produce fully structured interpretations. We also show how SKATE integrates with a neural rule-generation model to interactively suggest and acquire commonsense knowledge. We provide a preliminary coverage analysis of SKATE for the task of story understanding, and then describe a current business use-case of the tool in a specific domain: COVID-19 policy design.
GLUCOSE: GeneraLized and COntextualized Story Explanations
Sep 16, 2020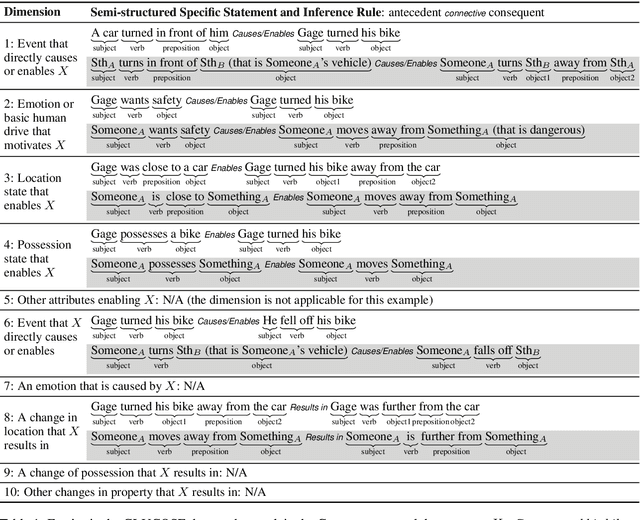



When humans read or listen, they make implicit commonsense inferences that frame their understanding of what happened and why. As a step toward AI systems that can build similar mental models, we introduce GLUCOSE, a large-scale dataset of implicit commonsense causal knowledge, encoded as causal mini-theories about the world, each grounded in a narrative context. To construct GLUCOSE, we drew on cognitive psychology to identify ten dimensions of causal explanation, focusing on events, states, motivations, and emotions. Each GLUCOSE entry includes a story-specific causal statement paired with an inference rule generalized from the statement. This paper details two concrete contributions: First, we present our platform for effectively crowdsourcing GLUCOSE data at scale, which uses semi-structured templates to elicit causal explanations. Using this platform, we collected 440K specific statements and general rules that capture implicit commonsense knowledge about everyday situations. Second, we show that existing knowledge resources and pretrained language models do not include or readily predict GLUCOSE's rich inferential content. However, when state-of-the-art neural models are trained on this knowledge, they can start to make commonsense inferences on unseen stories that match humans' mental models.