 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Magic Mirror: Automatic Video to 3D Caricature Translation
Jun 03, 2019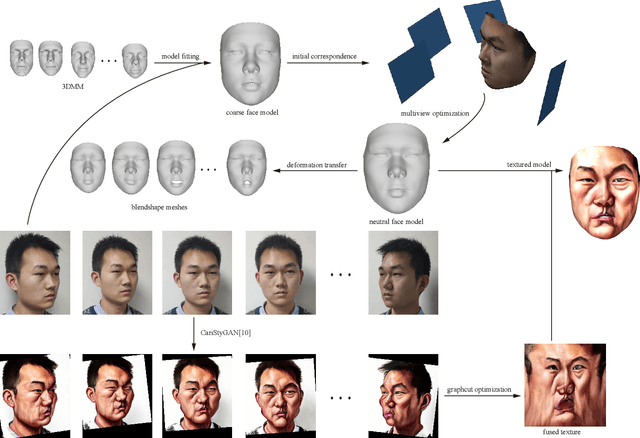
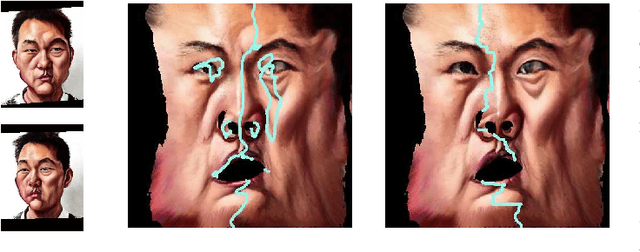
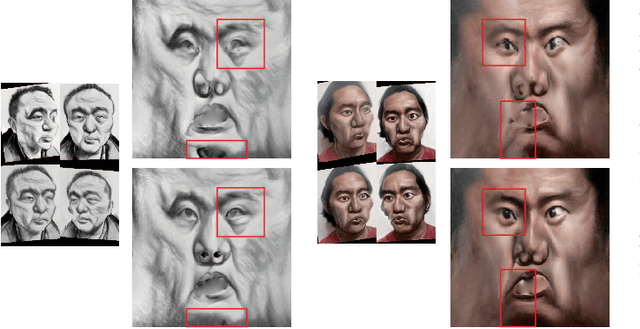
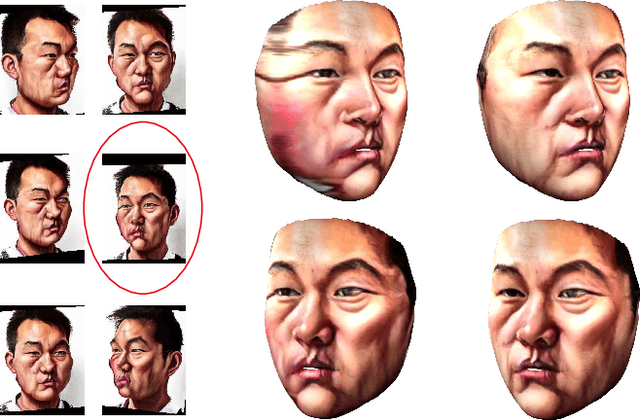
Caricature is an abstraction of a real person which distorts or exaggerates certain features, but still retains a likeness. While most existing works focus on 3D caricature reconstruction from 2D caricatures or translating 2D photos to 2D caricatures, this paper presents a real-time and automatic algorithm for creating expressive 3D caricatures with caricature style texture map from 2D photos or videos. To solve this challenging ill-posed reconstruction problem and cross-domain translation problem, we first reconstruct the 3D face shape for each frame, and then translate 3D face shape from normal style to caricature style by a novel identity and expression preserving VAE-CycleGAN. Based on a labeling formulation, the caricature texture map is constructed from a set of multi-view caricature images generated by CariGANs. The effectiveness and efficiency of our method are demonstrated by comparison with baseline implementations. The perceptual study shows that the 3D caricatures generated by our method meet people's expectations of 3D caricature style.
Robust RGB-D Face Recognition Using Attribute-Aware Loss
Nov 24, 2018
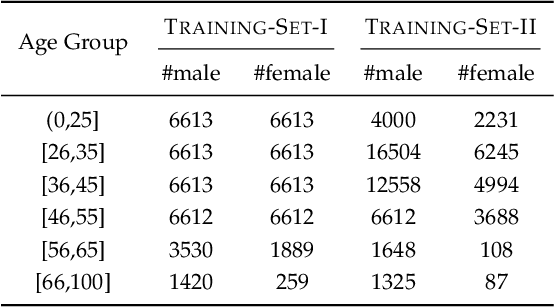
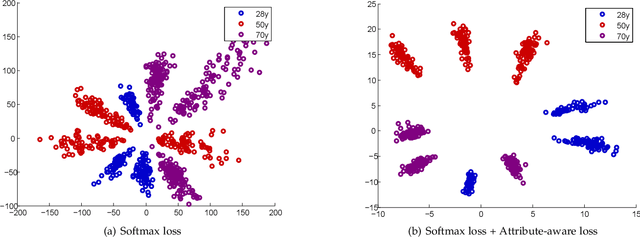

Existing convolutional neural network (CNN) based face recognition algorithms typically learn a discriminative feature mapping, using a loss function that enforces separation of features from different classes and/or aggregation of features within the same class. However, they may suffer from bias in the training data such as uneven sampling density, because they optimize the adjacency relationship of the learned features without considering the proximity of the underlying faces. Moreover, since they only use facial images for training, the learned feature mapping may not correctly indicate the relationship of other attributes such as gender and ethnicity, which can be important for some face recognition applications. In this paper, we propose a new CNN-based face recognition approach that incorporates such attributes into the training process. Using an attribute-aware loss function that regularizes the feature mapping using attribute proximity, our approach learns more discriminative features that are correlated with the attributes. We train our face recognition model on a large-scale RGB-D data set with over 100K identities captured under real application conditions. By comparing our approach with other methods on a variety of experiments, we demonstrate that depth channel and attribute-aware loss greatly improve the accuracy and robustness of face recognition.
3D Face Reconstruction with Geometry Details from a Single Image
Jun 11, 2018



3D face reconstruction from a single image is a classical and challenging problem, with wide applications in many areas. Inspired by recent works in face animation from RGB-D or monocular video inputs, we develop a novel method for reconstructing 3D faces from unconstrained 2D images, using a coarse-to-fine optimization strategy. First, a smooth coarse 3D face is generated from an example-based bilinear face model, by aligning the projection of 3D face landmarks with 2D landmarks detected from the input image. Afterwards, using local corrective deformation fields, the coarse 3D face is refined using photometric consistency constraints, resulting in a medium face shape. Finally, a shape-from-shading method is applied on the medium face to recover fine geometric details. Our method outperforms state-of-the-art approaches in terms of accuracy and detail recovery, which is demonstrated in extensive experiments using real world models and publicly available datasets.
Fast color transfer from multiple images
Dec 28, 2016


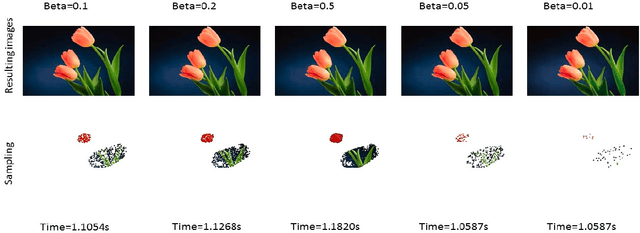
Color transfer between images uses the statistics information of image effectively. We present a novel approach of local color transfer between images based on the simple statistics and locally linear embedding. A sketching interface is proposed for quickly and easily specifying the color correspondences between target and source image. The user can specify the correspondences of local region using scribes, which more accurately transfers the target color to the source image while smoothly preserving the boundaries, and exhibits more natural output results. Our algorithm is not restricted to one-to-one image color transfer and can make use of more than one target images to transfer the color in different regions in the source image. Moreover, our algorithm does not require to choose the same color style and image size between source and target images. We propose the sub-sampling to reduce the computational load. Comparing with other approaches, our algorithm is much better in color blending in the input data. Our approach preserves the other color details in the source image. Various experimental results show that our approach specifies the correspondences of local color region in source and target images. And it expresses the intention of users and generates more actual and natural results of visual effect.