 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring global diverse attention via pairwise temporal relation for video summarization
Sep 23, 2020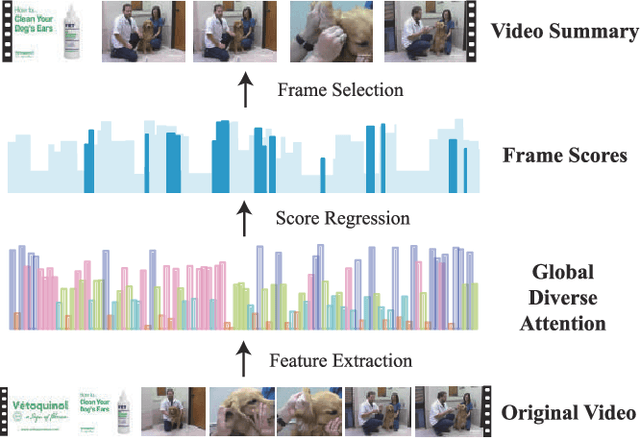
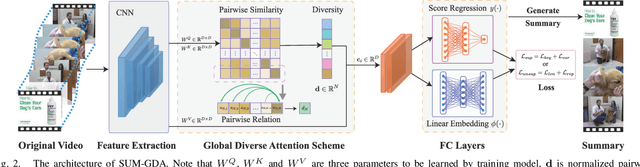
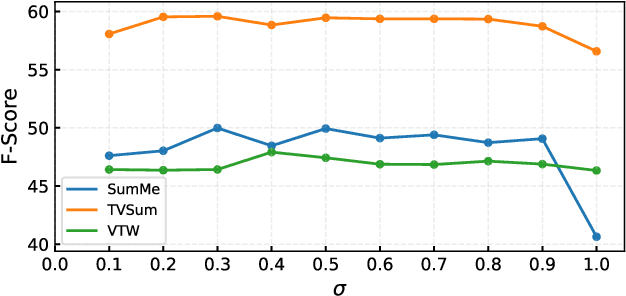
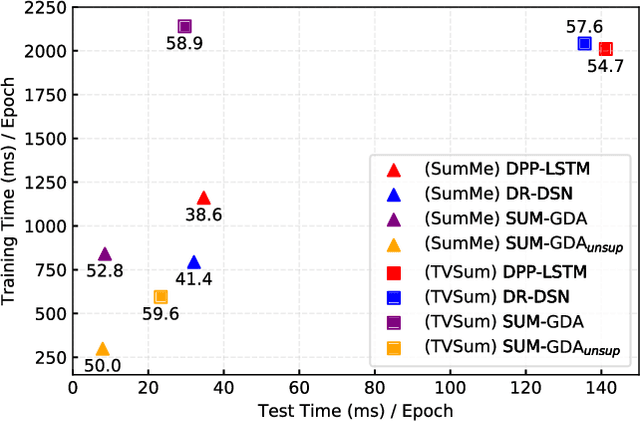
Video summarization is an effective way to facilitate video searching and browsing. Most of existing systems employ encoder-decoder based recurrent neural networks, which fail to explicitly diversify the system-generated summary frames while requiring intensive computations. In this paper, we propose an efficient convolutional neural network architecture for video SUMmarization via Global Diverse Attention called SUM-GDA, which adapts attention mechanism in a global perspective to consider pairwise temporal relations of video frames. Particularly, the GDA module has two advantages: 1) it models the relations within paired frames as well as the relations among all pairs, thus capturing the global attention across all frames of one video; 2) it reflects the importance of each frame to the whole video, leading to diverse attention on these frames. Thus, SUM-GDA is beneficial for generating diverse frames to form satisfactory video summary. Extensive experiments on three data sets, i.e., SumMe, TVSum, and VTW, have demonstrated that SUM-GDA and its extension outperform other competing state-of-the-art methods with remarkable improvements. In addition, the proposed models can be run in parallel with significantly less computational costs, which helps the deployment in highly demanding applications.
* 12 pages, 8 figures
Constrained Low-Rank Learning Using Least Squares-Based Regularization
Nov 15, 2016
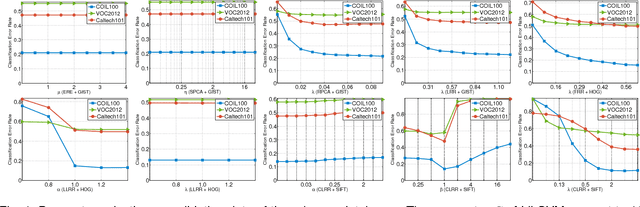
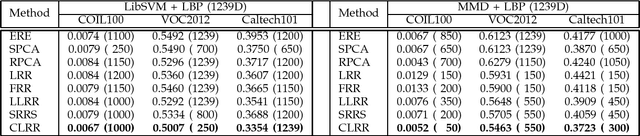

Low-rank learning has attracted much attention recently due to its efficacy in a rich variety of real-world tasks, e.g., subspace segmentation and image categorization. Most low-rank methods are incapable of capturing low-dimensional subspace for supervised learning tasks, e.g., classification and regression. This paper aims to learn both the discriminant low-rank representation (LRR) and the robust projecting subspace in a supervised manner. To achieve this goal, we cast the problem into a constrained rank minimization framework by adopting the least squares regularization. Naturally, the data label structure tends to resemble that of the corresponding low-dimensional representation, which is derived from the robust subspace projection of clean data by low-rank learning. Moreover, the low-dimensional representation of original data can be paired with some informative structure by imposing an appropriate constraint, e.g., Laplacian regularizer. Therefore, we propose a novel constrained LRR method. The objective function is formulated as a constrained nuclear norm minimization problem, which can be solved by the inexact augmented Lagrange multiplier algorithm. Extensive experiments on image classification, human pose estimation, and robust face recovery have confirmed the superiority of our method.
* 14 pages, 7 figures, accepted to appear in IEEE Transactions on Cybernetics
Action2Activity: Recognizing Complex Activities from Sensor Data
Nov 07, 2016
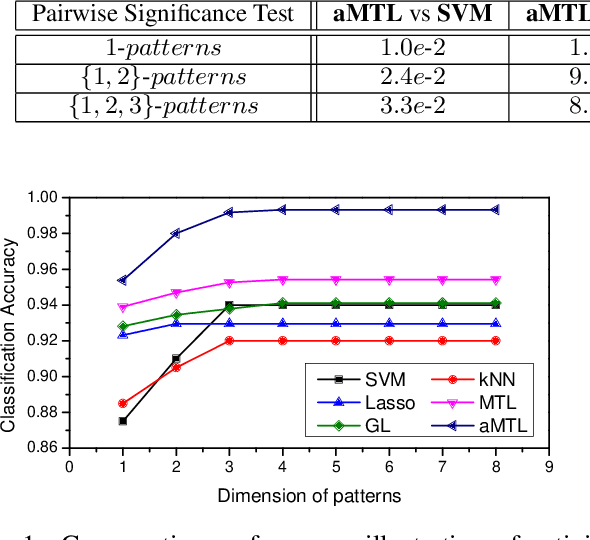

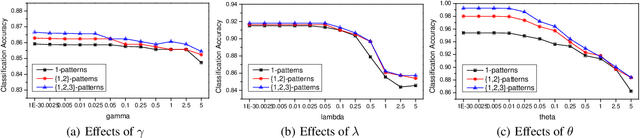
As compared to simple actions, activities are much more complex, but semantically consistent with a human's real life. Techniques for action recognition from sensor generated data are mature. However, there has been relatively little work on bridging the gap between actions and activities. To this end, this paper presents a novel approach for complex activity recognition comprising of two components. The first component is temporal pattern mining, which provides a mid-level feature representation for activities, encodes temporal relatedness among actions, and captures the intrinsic properties of activities. The second component is adaptive Multi-Task Learning, which captures relatedness among activities and selects discriminant features. Extensive experiments on a real-world dataset demonstrate the effectiveness of our work.
An Aerial Image Recognition Framework using Discrimination and Redundancy Quality Measure
Oct 06, 2014
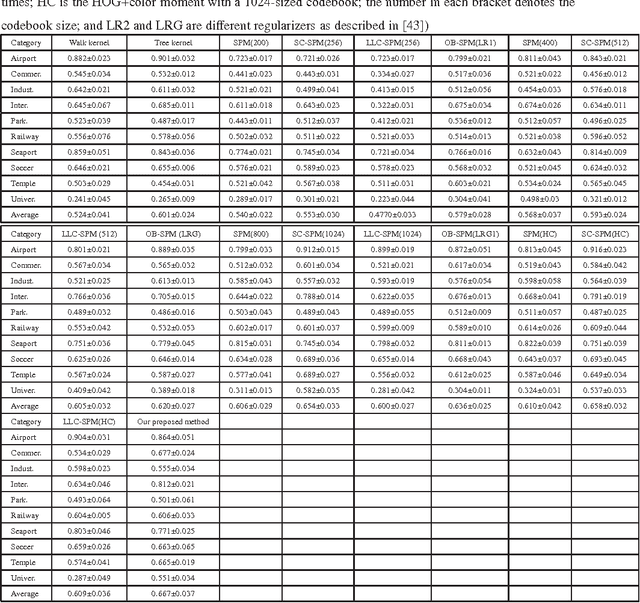
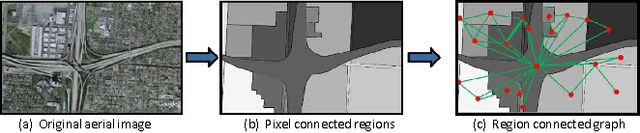
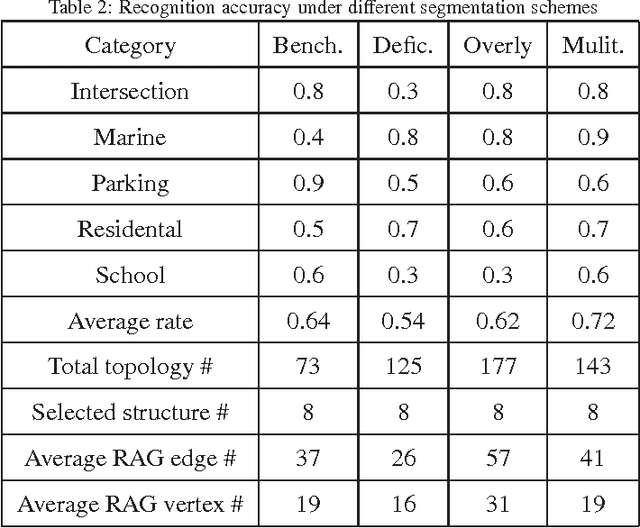
Aerial image categorization plays an indispensable role in remote sensing and artificial intelligence. In this paper, we propose a new aerial image categorization framework, focusing on organizing the local patches of each aerial image into multiple discriminative subgraphs. The subgraphs reflect both the geometric property and the color distribution of an aerial image. First, each aerial image is decomposed into a collection of regions in terms of their color intensities. Thereby region connected graph (RCG), which models the connection between the spatial neighboring regions, is constructed to encode the spatial context of an aerial image. Second, a subgraph mining technique is adopted to discover the frequent structures in the RCGs constructed from the training aerial images. Thereafter, a set of refined structures are selected among the frequent ones toward being highly discriminative and low redundant. Lastly, given a new aerial image, its sub-RCGs corresponding to the refined structures are extracted. They are further quantized into a discriminative vector for SVM classification. Thorough experimental results validate the effectiveness of the proposed method. In addition, the visualized mined subgraphs show that the discriminative topologies of each aerial image are discovered.