 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring global diverse attention via pairwise temporal relation for video summarization
Paper and Code
Sep 23, 2020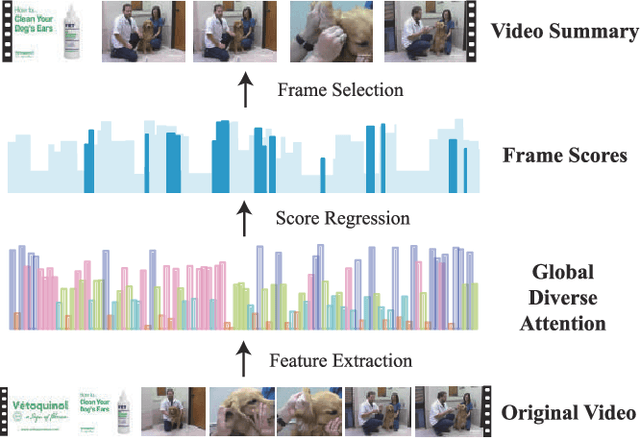
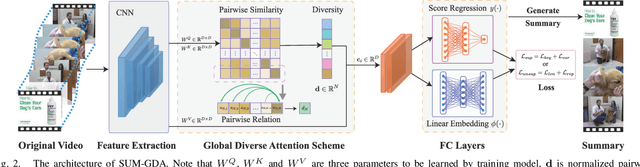
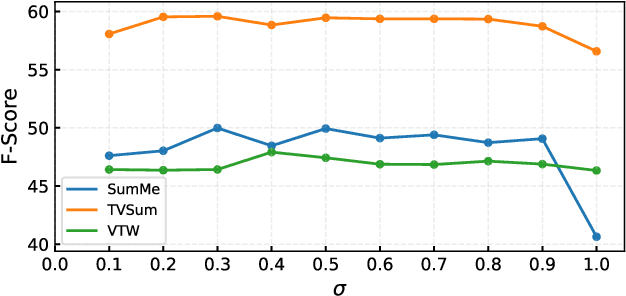
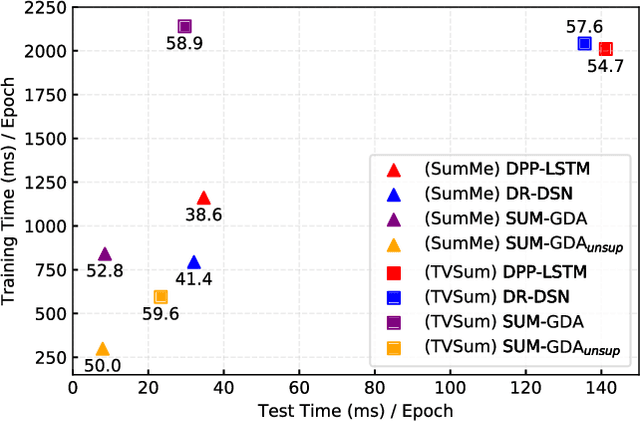
Video summarization is an effective way to facilitate video searching and browsing. Most of existing systems employ encoder-decoder based recurrent neural networks, which fail to explicitly diversify the system-generated summary frames while requiring intensive computations. In this paper, we propose an efficient convolutional neural network architecture for video SUMmarization via Global Diverse Attention called SUM-GDA, which adapts attention mechanism in a global perspective to consider pairwise temporal relations of video frames. Particularly, the GDA module has two advantages: 1) it models the relations within paired frames as well as the relations among all pairs, thus capturing the global attention across all frames of one video; 2) it reflects the importance of each frame to the whole video, leading to diverse attention on these frames. Thus, SUM-GDA is beneficial for generating diverse frames to form satisfactory video summary. Extensive experiments on three data sets, i.e., SumMe, TVSum, and VTW, have demonstrated that SUM-GDA and its extension outperform other competing state-of-the-art methods with remarkable improvements. In addition, the proposed models can be run in parallel with significantly less computational costs, which helps the deployment in highly demanding applications.