 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Diffusion Models Can Obey Formal Syntax
Feb 12, 2026Diffusion language models offer a promising alternative to autoregressive models due to their global, non-causal generation process, but their continuous latent dynamics make discrete constraints -- e.g., the output should be a JSON file that matches a given schema -- difficult to impose. We introduce a training-free guidance method for steering continuous diffusion language models to satisfy formal syntactic constraints expressed using regular expressions. Our approach constructs an analytic score estimating the probability that a latent state decodes to a valid string accepted by a given regular expression, and uses its gradient to guide sampling, without training auxiliary classifiers. The denoising process targets the base model conditioned on syntactic validity. We implement our method in Diffinity on top of the PLAID diffusion model and evaluate it on 180 regular-expression constraints over JSON and natural-language benchmarks. Diffinity achieves 68-96\% constraint satisfaction while incurring only a small perplexity cost relative to unconstrained sampling, outperforming autoregressive constrained decoding in both constraint satisfaction and output quality.
Constrained Adaptive Rejection Sampling
Oct 02, 2025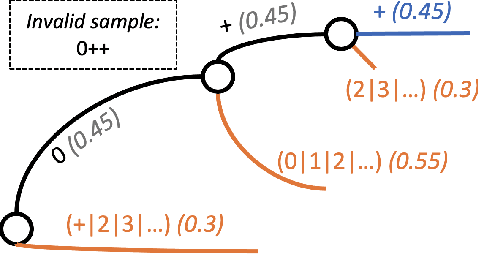
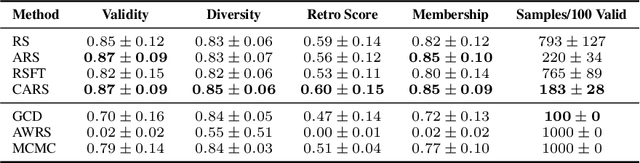
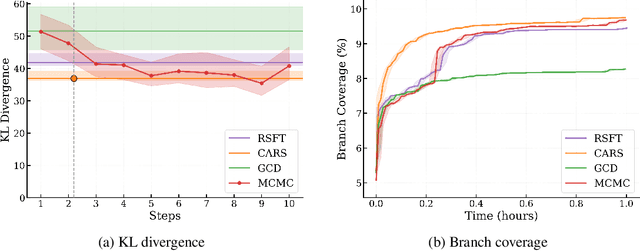
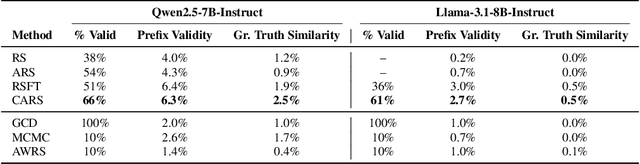
Language Models (LMs) are increasingly used in applications where generated outputs must satisfy strict semantic or syntactic constraints. Existing approaches to constrained generation fall along a spectrum: greedy constrained decoding methods enforce validity during decoding but distort the LM's distribution, while rejection sampling (RS) preserves fidelity but wastes computation by discarding invalid outputs. Both extremes are problematic in domains such as program fuzzing, where both validity and diversity of samples are essential. We present Constrained Adaptive Rejection Sampling (CARS), an approach that strictly improves the sample-efficiency of RS without distributional distortion. CARS begins with unconstrained LM sampling and adaptively rules out constraint-violating continuations by recording them in a trie and subtracting their probability mass from future draws. This adaptive pruning ensures that prefixes proven invalid are never revisited, acceptance rates improve monotonically, and the resulting samples exactly follow the constrained distribution. In experiments on a variety of domains -- e.g., program fuzzing and molecular generation -- CARS consistently achieves higher efficiency -- measured in the number of LM forward passes per valid sample -- while also producing stronger sample diversity than both GCD and methods that approximate the LM's distribution.
Constrained Sampling for Language Models Should Be Easy: An MCMC Perspective
Jun 06, 2025Constrained decoding enables Language Models (LMs) to produce samples that provably satisfy hard constraints. However, existing constrained-decoding approaches often distort the underlying model distribution, a limitation that is especially problematic in applications like program fuzzing, where one wants to generate diverse and valid program inputs for testing purposes. We propose a new constrained sampling framework based on Markov Chain Monte Carlo (MCMC) that simultaneously satisfies three core desiderata: constraint satisfying (every sample satisfies the constraint), monotonically converging (the sampling process converges to the true conditional distribution), and efficient (high-quality samples emerge in few steps). Our method constructs a proposal distribution over valid outputs and applies a Metropolis-Hastings acceptance criterion based on the LM's likelihood, ensuring principled and efficient exploration of the constrained space. Empirically, our sampler outperforms existing methods on both synthetic benchmarks and real-world program fuzzing tasks.
Flexible and Efficient Grammar-Constrained Decoding
Feb 07, 2025



Large Language Models (LLMs) are often asked to generate structured outputs that obey precise syntactic rules, such as code snippets or formatted data. Grammar-constrained decoding (GCD) can guarantee that LLM outputs matches such rules by masking out tokens that will provably lead to outputs that do not belong to a specified context-free grammar (CFG). To guarantee soundness, GCD algorithms have to compute how a given LLM subword tokenizer can align with the tokens used by a given context-free grammar and compute token masks based on this information. Doing so efficiently is challenging and existing GCD algorithms require tens of minutes to preprocess common grammars. We present a new GCD algorithm together with an implementation that offers 17.71x faster offline preprocessing than existing approaches while preserving state-of-the-art efficiency in online mask computation.
Grammar-Aligned Decoding
May 31, 2024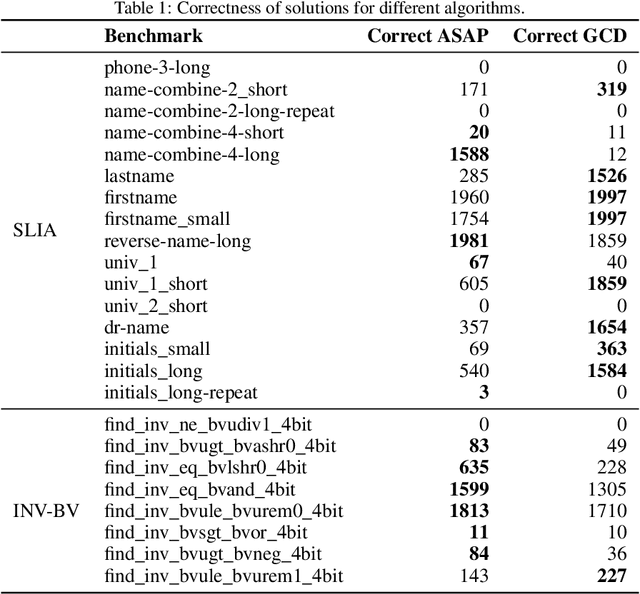

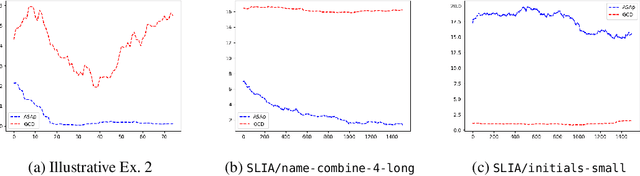
Large Language Models (LLMs) struggle with reliably generating highly structured outputs, such as program code, mathematical formulas, or well-formed markup. Constrained decoding approaches mitigate this problem by greedily restricting what tokens an LLM can output at each step to guarantee that the output matches a given constraint. Specifically, in grammar-constrained decoding (GCD), the LLM's output must follow a given grammar. In this paper we demonstrate that GCD techniques (and in general constrained decoding techniques) can distort the LLM's distribution, leading to outputs that are grammatical but appear with likelihoods that are not proportional to the ones given by the LLM, and so ultimately are low-quality. We call the problem of aligning sampling with a grammar constraint, grammar-aligned decoding (GAD), and propose adaptive sampling with approximate expected futures (ASAp), a decoding algorithm that guarantees the output to be grammatical while provably producing outputs that match the conditional probability of the LLM's distribution conditioned on the given grammar constraint. Our algorithm uses prior sample outputs to soundly overapproximate the future grammaticality of different output prefixes. Our evaluation on code generation and structured NLP tasks shows how ASAp often produces outputs with higher likelihood (according to the LLM's distribution) than existing GCD techniques, while still enforcing the desired grammatical constraints.
A One-Layer Decoder-Only Transformer is a Two-Layer RNN: With an Application to Certified Robustness
May 27, 2024This paper reveals a key insight that a one-layer decoder-only Transformer is equivalent to a two-layer Recurrent Neural Network (RNN). Building on this insight, we propose ARC-Tran, a novel approach for verifying the robustness of decoder-only Transformers against arbitrary perturbation spaces. Compared to ARC-Tran, current robustness verification techniques are limited either to specific and length-preserving perturbations like word substitutions or to recursive models like LSTMs. ARC-Tran addresses these limitations by meticulously managing position encoding to prevent mismatches and by utilizing our key insight to achieve precise and scalable verification. Our evaluation shows that ARC-Tran (1) trains models more robust to arbitrary perturbation spaces than those produced by existing techniques and (2) shows high certification accuracy of the resulting models.
Verified Training for Counterfactual Explanation Robustness under Data Shift
Mar 06, 2024Counterfactual explanations (CEs) enhance the interpretability of machine learning models by describing what changes to an input are necessary to change its prediction to a desired class. These explanations are commonly used to guide users' actions, e.g., by describing how a user whose loan application was denied can be approved for a loan in the future. Existing approaches generate CEs by focusing on a single, fixed model, and do not provide any formal guarantees on the CEs' future validity. When models are updated periodically to account for data shift, if the generated CEs are not robust to the shifts, users' actions may no longer have the desired impacts on their predictions. This paper introduces VeriTraCER, an approach that jointly trains a classifier and an explainer to explicitly consider the robustness of the generated CEs to small model shifts. VeriTraCER optimizes over a carefully designed loss function that ensures the verifiable robustness of CEs to local model updates, thus providing deterministic guarantees to CE validity. Our empirical evaluation demonstrates that VeriTraCER generates CEs that (1) are verifiably robust to small model updates and (2) display competitive robustness to state-of-the-art approaches in handling empirical model updates including random initialization, leave-one-out, and distribution shifts.
The Dataset Multiplicity Problem: How Unreliable Data Impacts Predictions
Apr 20, 2023We introduce dataset multiplicity, a way to study how inaccuracies, uncertainty, and social bias in training datasets impact test-time predictions. The dataset multiplicity framework asks a counterfactual question of what the set of resultant models (and associated test-time predictions) would be if we could somehow access all hypothetical, unbiased versions of the dataset. We discuss how to use this framework to encapsulate various sources of uncertainty in datasets' factualness, including systemic social bias, data collection practices, and noisy labels or features. We show how to exactly analyze the impacts of dataset multiplicity for a specific model architecture and type of uncertainty: linear models with label errors. Our empirical analysis shows that real-world datasets, under reasonable assumptions, contain many test samples whose predictions are affected by dataset multiplicity. Furthermore, the choice of domain-specific dataset multiplicity definition determines what samples are affected, and whether different demographic groups are disparately impacted. Finally, we discuss implications of dataset multiplicity for machine learning practice and research, including considerations for when model outcomes should not be trusted.
PECAN: A Deterministic Certified Defense Against Backdoor Attacks
Jan 27, 2023Neural networks are vulnerable to backdoor poisoning attacks, where the attackers maliciously poison the training set and insert triggers into the test input to change the prediction of the victim model. Existing defenses for backdoor attacks either provide no formal guarantees or come with expensive-to-compute and ineffective probabilistic guarantees. We present PECAN, an efficient and certified approach for defending against backdoor attacks. The key insight powering PECAN is to apply off-the-shelf test-time evasion certification techniques on a set of neural networks trained on disjoint partitions of the data. We evaluate PECAN on image classification and malware detection datasets. Our results demonstrate that PECAN can (1) significantly outperform the state-of-the-art certified backdoor defense, both in defense strength and efficiency, and (2) on real back-door attacks, PECAN can reduce attack success rate by order of magnitude when compared to a range of baselines from the literature.
Certifying Data-Bias Robustness in Linear Regression
Jun 07, 2022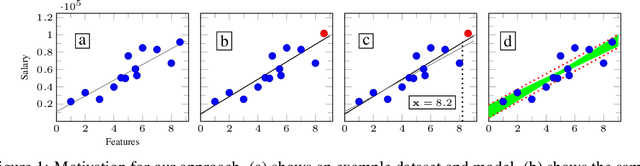

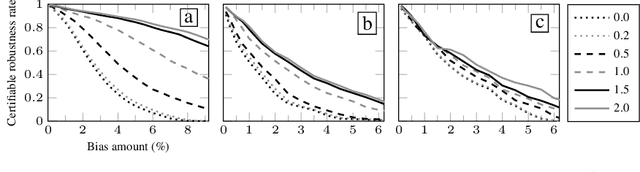
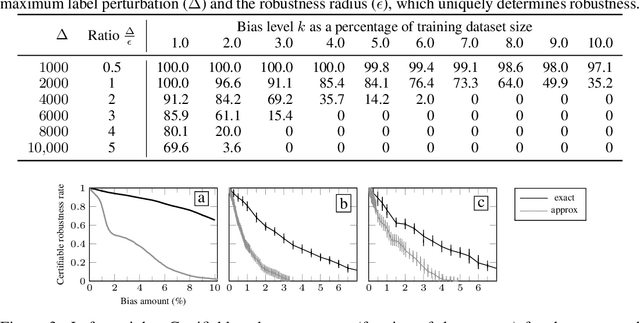
Datasets typically contain inaccuracies due to human error and societal biases, and these inaccuracies can affect the outcomes of models trained on such datasets. We present a technique for certifying whether linear regression models are pointwise-robust to label bias in the training dataset, i.e., whether bounded perturbations to the labels of a training dataset result in models that change the prediction of test points. We show how to solve this problem exactly for individual test points, and provide an approximate but more scalable method that does not require advance knowledge of the test point. We extensively evaluate both techniques and find that linear models -- both regression- and classification-based -- often display high levels of bias-robustness. However, we also unearth gaps in bias-robustness, such as high levels of non-robustness for certain bias assumptions on some datasets. Overall, our approach can serve as a guide for when to trust, or question, a model's output.