 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Modal Prompting for Sketch-Based Image Retrieval
Apr 29, 2024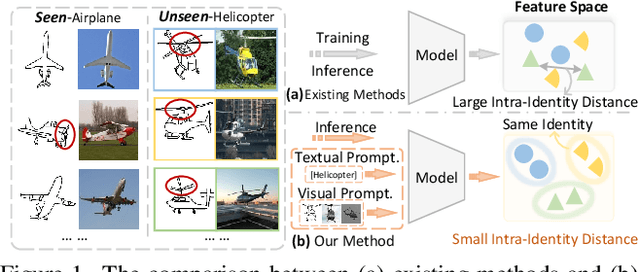
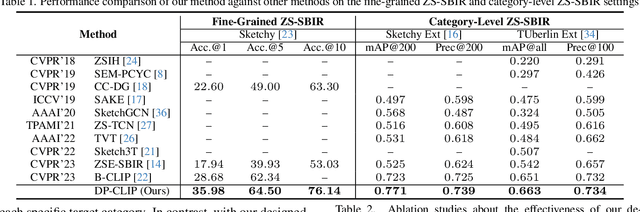
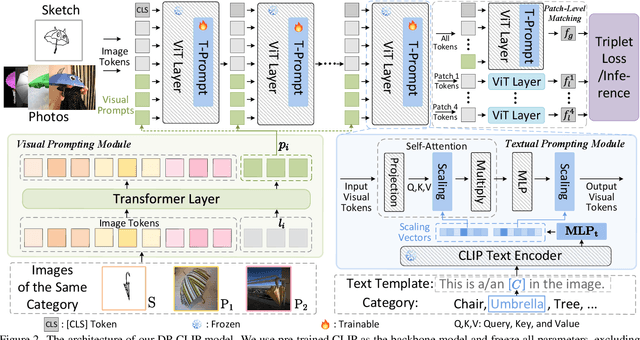
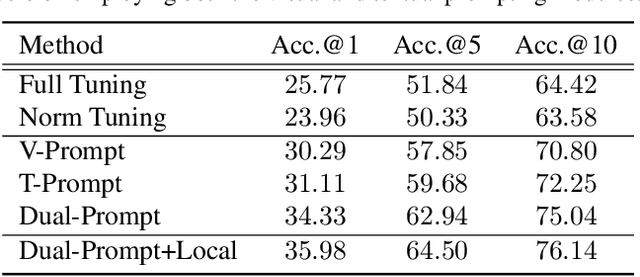
Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
Generalizable Person Re-Identification via Viewpoint Alignment and Fusion
Dec 05, 2022



In the current person Re-identification (ReID) methods, most domain generalization works focus on dealing with style differences between domains while largely ignoring unpredictable camera view change, which we identify as another major factor leading to a poor generalization of ReID methods. To tackle the viewpoint change, this work proposes to use a 3D dense pose estimation model and a texture mapping module to map the pedestrian images to canonical view images. Due to the imperfection of the texture mapping module, the canonical view images may lose the discriminative detail clues from the original images, and thus directly using them for ReID will inevitably result in poor performance. To handle this issue, we propose to fuse the original image and canonical view image via a transformer-based module. The key insight of this design is that the cross-attention mechanism in the transformer could be an ideal solution to align the discriminative texture clues from the original image with the canonical view image, which could compensate for the low-quality texture information of the canonical view image. Through extensive experiments, we show that our method can lead to superior performance over the existing approaches in various evaluation settings.
Text-based Person Search in Full Images via Semantic-Driven Proposal Generation
Sep 27, 2021



Finding target persons in full scene images with a query of text description has important practical applications in intelligent video surveillance.However, different from the real-world scenarios where the bounding boxes are not available, existing text-based person retrieval methods mainly focus on the cross modal matching between the query text descriptions and the gallery of cropped pedestrian images. To close the gap, we study the problem of text-based person search in full images by proposing a new end-to-end learning framework which jointly optimize the pedestrian detection, identification and visual-semantic feature embedding tasks. To take full advantage of the query text, the semantic features are leveraged to instruct the Region Proposal Network to pay more attention to the text-described proposals. Besides, a cross-scale visual-semantic embedding mechanism is utilized to improve the performance. To validate the proposed method, we collect and annotate two large-scale benchmark datasets based on the widely adopted image-based person search datasets CUHK-SYSU and PRW. Comprehensive experiments are conducted on the two datasets and compared with the baseline methods, our method achieves the state-of-the-art performance.