 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVDq: 1.25-bit and 410x Key Cache Compression for LLM Attention
Feb 21, 2025For the efficient inference of Large Language Models (LLMs), the effective compression of key-value (KV) cache is essential. Three main types of KV cache compression techniques, namely sparsity, channel compression, and quantization, have been identified. This study presents SVDq, a Singular Value Decomposition (SVD) - based mixed precision quantization method for K cache. Initially, K cache is transformed into latent channels using SVD basis representations. Since the values in latent channels decay rapidly and become negligible after only a few latent channels, our method then incorporates importance-aware quantization and compression for latent channels. This enables the effective allocation of higher precision to more significant channels. Theoretically, we prove that SVDq results in quantization errors (x0.1 or even lower) that are much lower than those of per-channel key quantization in the original space. Our findings based on RULER and LongBench benchmarks demonstrate that SVDq can achieve an equivalent key cache precision as low as 1.25-bit. When combined with key sparsity, it can reach a key compression ratio of up to 410x for attention computation, all while maintaining comparable model performance. Notably, our method is nearly lossless for LongBench datasets. This indicates that SVDq enables high-precision low-bit quantization, providing a more efficient solution for KV cache compression in LLMs.
Differentiable Logic Machines
Feb 24, 2021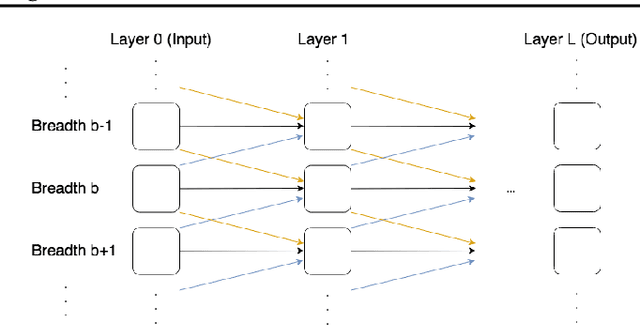
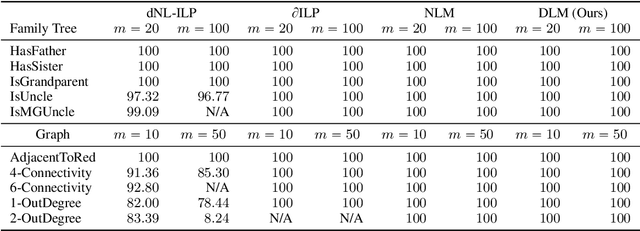
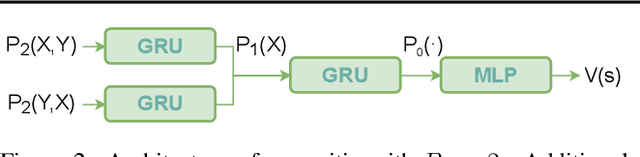
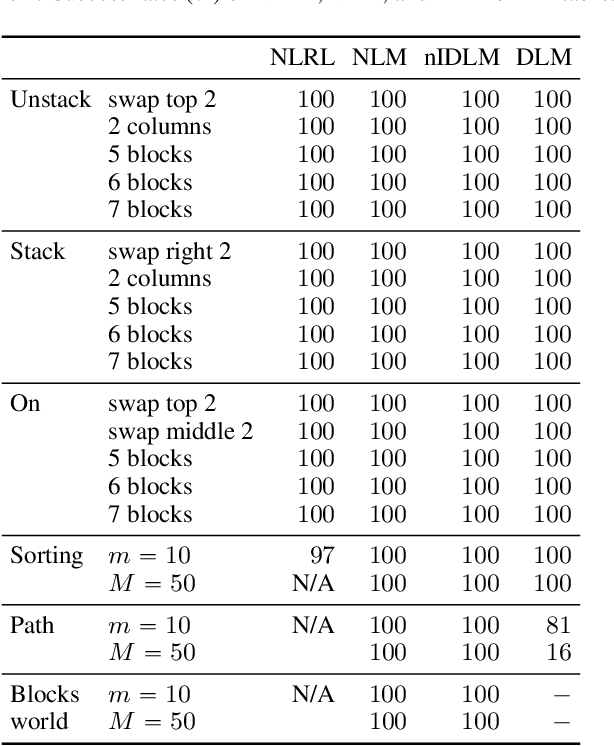
The integration of reasoning, learning, and decision-making is key to build more general AI systems. As a step in this direction, we propose a novel neural-logic architecture that can solve both inductive logic programming (ILP) and deep reinforcement learning (RL) problems. Our architecture defines a restricted but expressive continuous space of first-order logic programs by assigning weights to predicates instead of rules. Therefore, it is fully differentiable and can be efficiently trained with gradient descent. Besides, in the deep RL setting with actor-critic algorithms, we propose a novel efficient critic architecture. Compared to state-of-the-art methods on both ILP and RL problems, our proposition achieves excellent performance, while being able to provide a fully interpretable solution and scaling much better, especially during the testing phase.