 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of the nnU-Net for automatic segmentation of lung lesion on CT images, and implication on radiomic models
Sep 24, 2022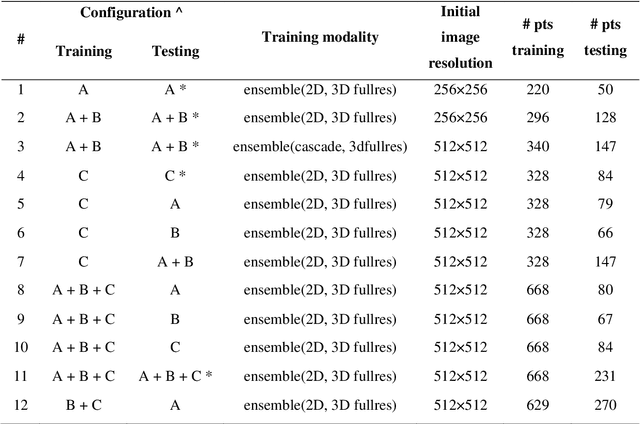
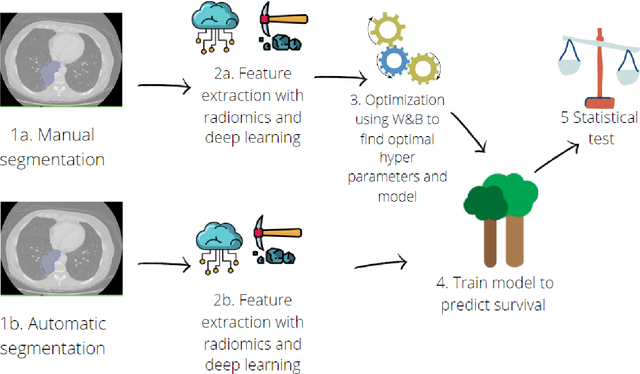
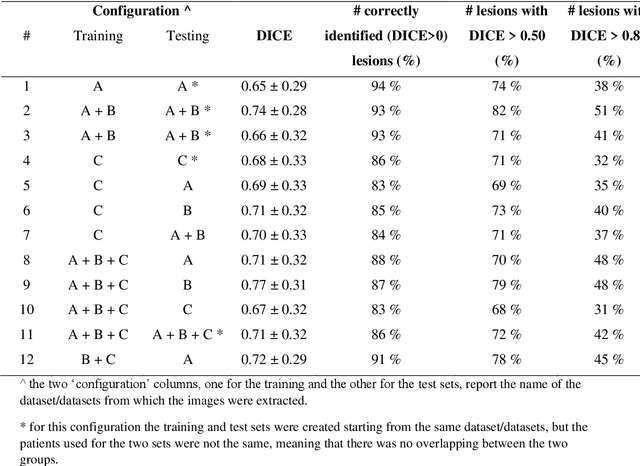
Lesion segmentation is a crucial step of the radiomic workflow. Manual segmentation requires long execution time and is prone to variability, impairing the realisation of radiomic studies and their robustness. In this study, a deep-learning automatic segmentation method was applied on computed tomography images of non-small-cell lung cancer patients. The use of manual vs automatic segmentation in the performance of survival radiomic models was assessed, as well. METHODS A total of 899 NSCLC patients were included (2 proprietary: A and B, 1 public datasets: C). Automatic segmentation of lung lesions was performed by training a previously developed architecture, the nnU-Net, including 2D, 3D and cascade approaches. The quality of automatic segmentation was evaluated with DICE coefficient, considering manual contours as reference. The impact of automatic segmentation on the performance of a radiomic model for patient survival was explored by extracting radiomic hand-crafted and deep-learning features from manual and automatic contours of dataset A, and feeding different machine learning algorithms to classify survival above/below median. Models' accuracies were assessed and compared. RESULTS The best agreement between automatic and manual contours with DICE=0.78 +(0.12) was achieved by averaging predictions from 2D and 3D models, and applying a post-processing technique to extract the maximum connected component. No statistical differences were observed in the performances of survival models when using manual or automatic contours, hand-crafted, or deep features. The best classifier showed an accuracy between 0.65 and 0.78. CONCLUSION The promising role of nnU-Net for automatic segmentation of lung lesions was confirmed, dramatically reducing the time-consuming physicians' workload without impairing the accuracy of survival predictive models based on radiomics.
Quantification of pulmonary involvement in COVID-19 pneumonia by means of a cascade oftwo U-nets: training and assessment on multipledatasets using different annotation criteria
May 06, 2021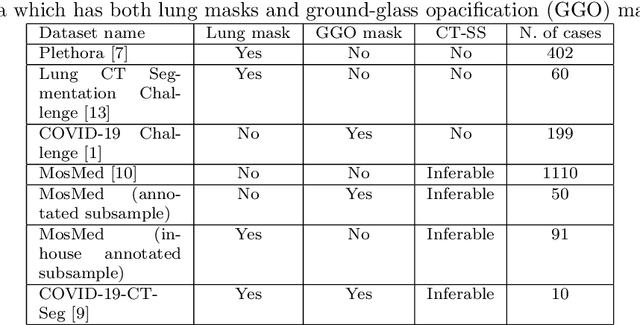
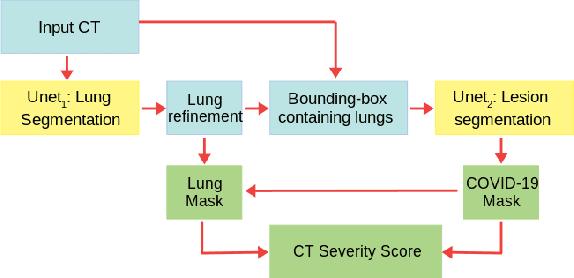
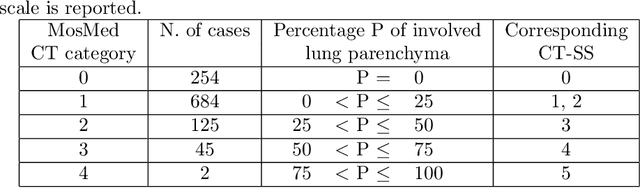
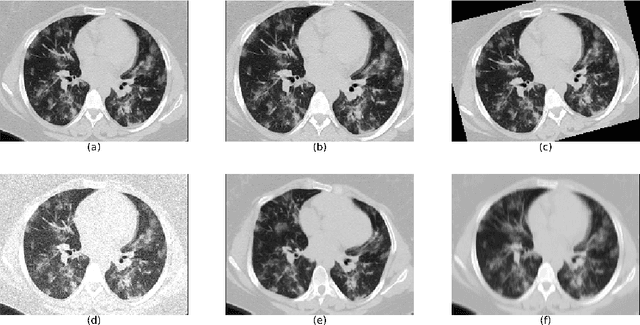
The automatic assignment of a severity score to the CT scans of patients affected by COVID-19 pneumonia could reduce the workload in radiology departments. This study aims at exploiting Artificial intelligence (AI) for the identification, segmentation and quantification of COVID-19 pulmonary lesions. We investigated the effects of using multiple datasets, heterogeneously populated and annotated according to different criteria. We developed an automated analysis pipeline, the LungQuant system, based on a cascade of two U-nets. The first one (U-net_1) is devoted to the identification of the lung parenchyma, the second one (U-net_2) acts on a bounding box enclosing the segmented lungs to identify the areas affected by COVID-19 lesions. Different public datasets were used to train the U-nets and to evaluate their segmentation performances, which have been quantified in terms of the Dice index. The accuracy in predicting the CT-Severity Score (CT-SS) of the LungQuant system has been also evaluated. Both Dice and accuracy showed a dependency on the quality of annotations of the available data samples. On an independent and publicly available benchmark dataset, the Dice values measured between the masks predicted by LungQuant system and the reference ones were 0.95$\pm$0.01 and 0.66$\pm$0.13 for the segmentation of lungs and COVID-19 lesions, respectively. The accuracy of 90% in the identification of the CT-SS on this benchmark dataset was achieved. We analysed the impact of using data samples with different annotation criteria in training an AI-based quantification system for pulmonary involvement in COVID-19 pneumonia. In terms of the Dice index, the U-net segmentation quality strongly depends on the quality of the lesion annotations. Nevertheless, the CT-SS can be accurately predicted on independent validation sets, demonstrating the satisfactory generalization ability of the LungQuant.