 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable cluster analysis: a bagging approach
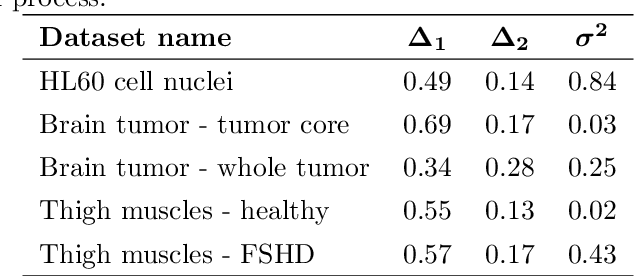
Mar 20, 2026A major limitation of clustering approaches is their lack of explainability: methods rarely provide insight into which features drive the grouping of similar observations. To address this limitation, we propose an ensemble-based clustering framework that integrates bagging and feature dropout to generate feature importance scores, in analogy with feature importance mechanisms in supervised random forests. By leveraging multiple bootstrap resampling schemes and aggregating the resulting partitions, the method improves stability and robustness of the cluster definition, particularly in small-sample or noisy settings. Feature importance is assessed through an information-theoretic approach: at each step, the mutual information between each feature and the estimated cluster labels is computed and weighted by a measure of clustering validity to emphasize well-formed partitions, before being aggregated into a final score. The method outputs both a consensus partition and a corresponding measure of feature importance, enabling a unified interpretation of clustering structure and variable relevance. Its effectiveness is demonstrated on multiple simulated and real-world datasets.
Generalized Bayesian Ensemble Survival Tree (GBEST) model
Mar 14, 2025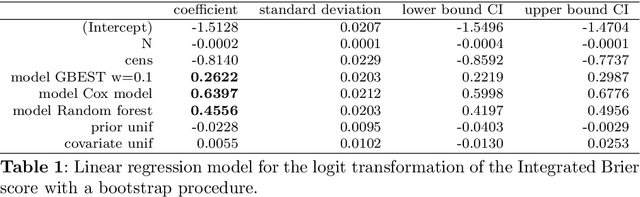
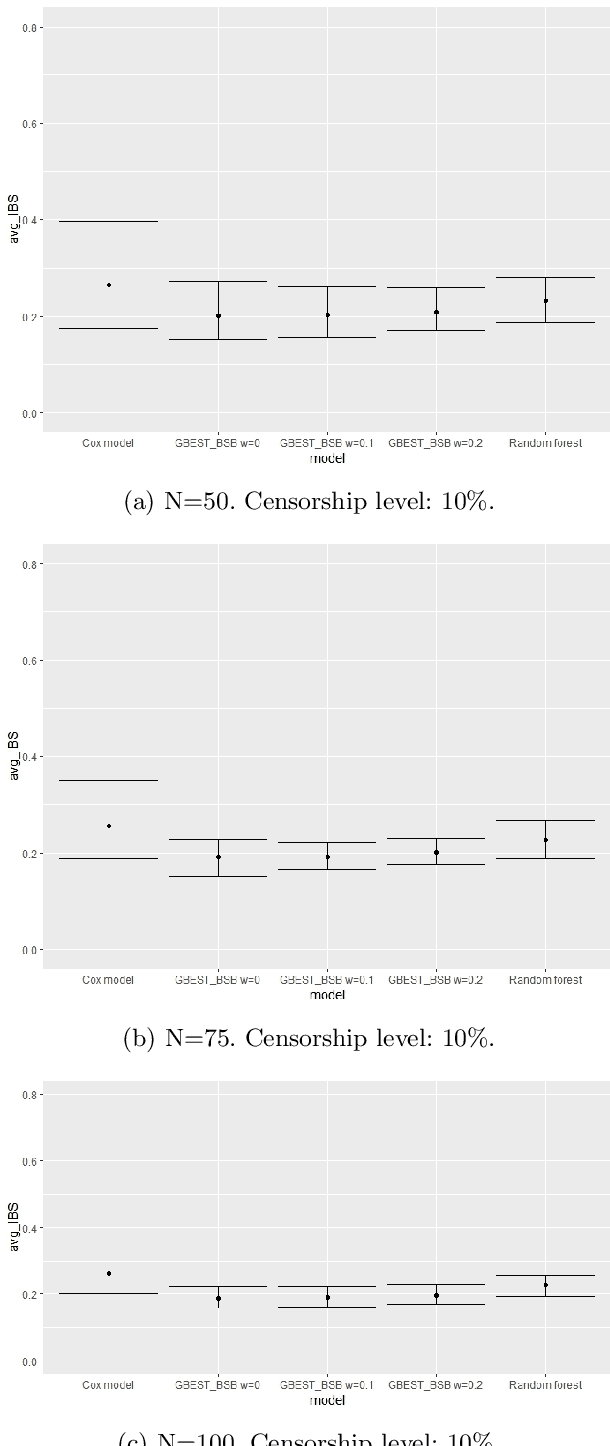
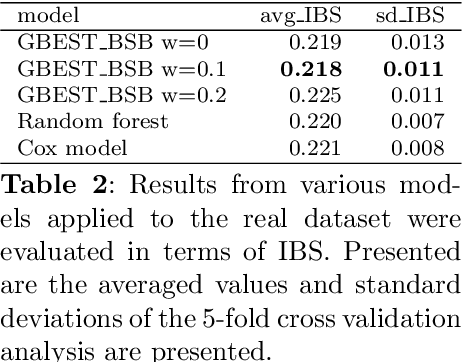
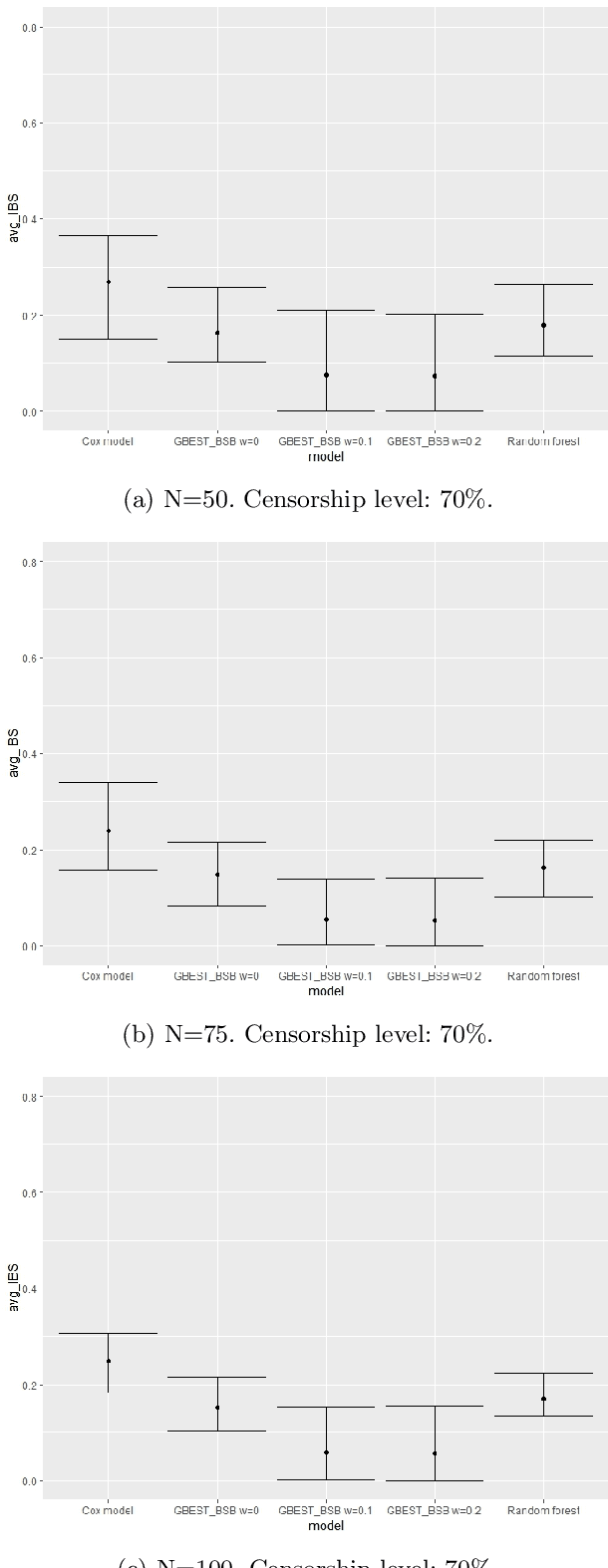
This paper proposes a new class of predictive models for survival analysis called Generalized Bayesian Ensemble Survival Tree (GBEST). It is well known that survival analysis poses many different challenges, in particular when applied to small data or censorship mechanism. Our contribution is the proposal of an ensemble approach that uses Bayesian bootstrap and beta Stacy bootstrap methods to improve the outcome in survival application with a special focus on small datasets. More precisely, a novel approach to integrate Beta Stacy Bayesian bootstrap in bagging tree models for censored data is proposed in this paper. Empirical evidence achieved on simulated and real data underlines that our approach performs better in terms of predictive performances and stability of the results compared with classical survival models available in the literature. In terms of methodology our novel contribution considers the adaptation of recent Bayesian ensemble approaches to survival data, providing a new model called Generalized Bayesian Ensemble Survival Tree (GBEST). A further result in terms of computational novelty is the implementation in R of GBEST, available in a public GitHub repository.
A Bayesian Approach to Clustering via the Proper Bayesian Bootstrap: the Bayesian Bagged Clustering (BBC) algorithm
Sep 13, 2024The paper presents a novel approach for unsupervised techniques in the field of clustering. A new method is proposed to enhance existing literature models using the proper Bayesian bootstrap to improve results in terms of robustness and interpretability. Our approach is organized in two steps: k-means clustering is used for prior elicitation, then proper Bayesian bootstrap is applied as resampling method in an ensemble clustering approach. Results are analyzed introducing measures of uncertainty based on Shannon entropy. The proposal provides clear indication on the optimal number of clusters, as well as a better representation of the clustered data. Empirical results are provided on simulated data showing the methodological and empirical advances obtained.
A kinetic approach to consensus-based segmentation of biomedical images
Nov 08, 2022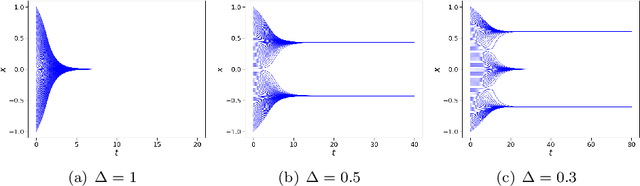
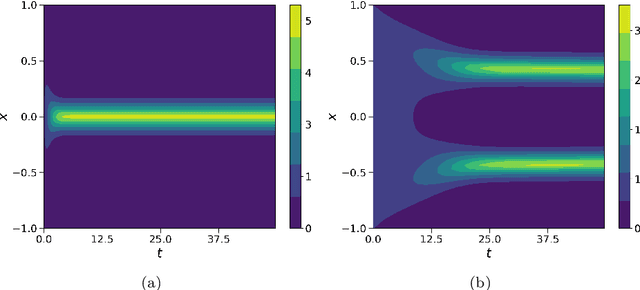
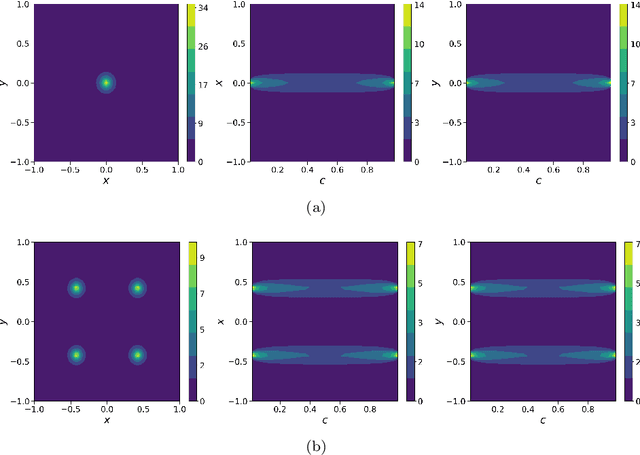
In this work, we apply a kinetic version of a bounded confidence consensus model to biomedical segmentation problems. In the presented approach, time-dependent information on the microscopic state of each particle/pixel includes its space position and a feature representing a static characteristic of the system, i.e. the gray level of each pixel. From the introduced microscopic model we derive a kinetic formulation of the model. The large time behavior of the system is then computed with the aid of a surrogate Fokker-Planck approach that can be obtained in the quasi-invariant scaling. We exploit the computational efficiency of direct simulation Monte Carlo methods for the obtained Boltzmann-type description of the problem for parameter identification tasks. Based on a suitable loss function measuring the distance between the ground truth segmentation mask and the evaluated mask, we minimize the introduced segmentation metric for a relevant set of 2D gray-scale images. Applications to biomedical segmentation concentrate on different imaging research contexts.
Quantification of pulmonary involvement in COVID-19 pneumonia by means of a cascade oftwo U-nets: training and assessment on multipledatasets using different annotation criteria
May 06, 2021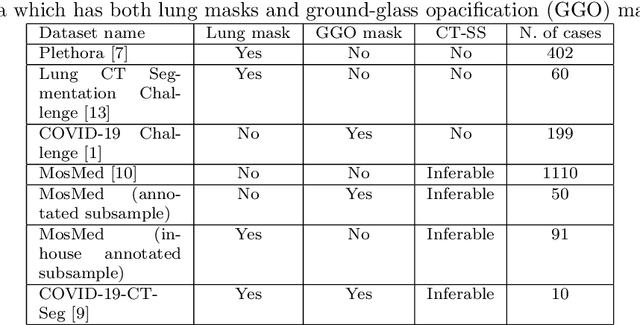
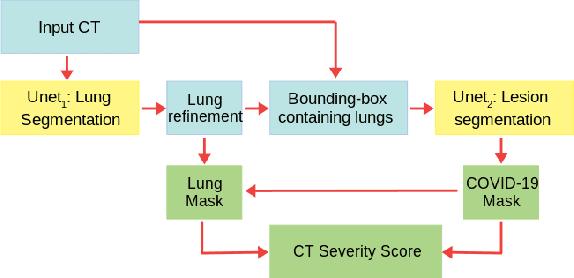
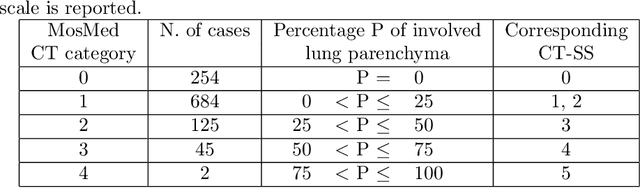
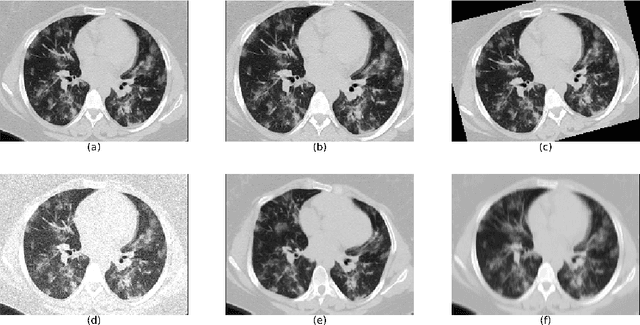
The automatic assignment of a severity score to the CT scans of patients affected by COVID-19 pneumonia could reduce the workload in radiology departments. This study aims at exploiting Artificial intelligence (AI) for the identification, segmentation and quantification of COVID-19 pulmonary lesions. We investigated the effects of using multiple datasets, heterogeneously populated and annotated according to different criteria. We developed an automated analysis pipeline, the LungQuant system, based on a cascade of two U-nets. The first one (U-net_1) is devoted to the identification of the lung parenchyma, the second one (U-net_2) acts on a bounding box enclosing the segmented lungs to identify the areas affected by COVID-19 lesions. Different public datasets were used to train the U-nets and to evaluate their segmentation performances, which have been quantified in terms of the Dice index. The accuracy in predicting the CT-Severity Score (CT-SS) of the LungQuant system has been also evaluated. Both Dice and accuracy showed a dependency on the quality of annotations of the available data samples. On an independent and publicly available benchmark dataset, the Dice values measured between the masks predicted by LungQuant system and the reference ones were 0.95$\pm$0.01 and 0.66$\pm$0.13 for the segmentation of lungs and COVID-19 lesions, respectively. The accuracy of 90% in the identification of the CT-SS on this benchmark dataset was achieved. We analysed the impact of using data samples with different annotation criteria in training an AI-based quantification system for pulmonary involvement in COVID-19 pneumonia. In terms of the Dice index, the U-net segmentation quality strongly depends on the quality of the lesion annotations. Nevertheless, the CT-SS can be accurately predicted on independent validation sets, demonstrating the satisfactory generalization ability of the LungQuant.
A new approach in model selection for ordinal target variables
Mar 05, 2020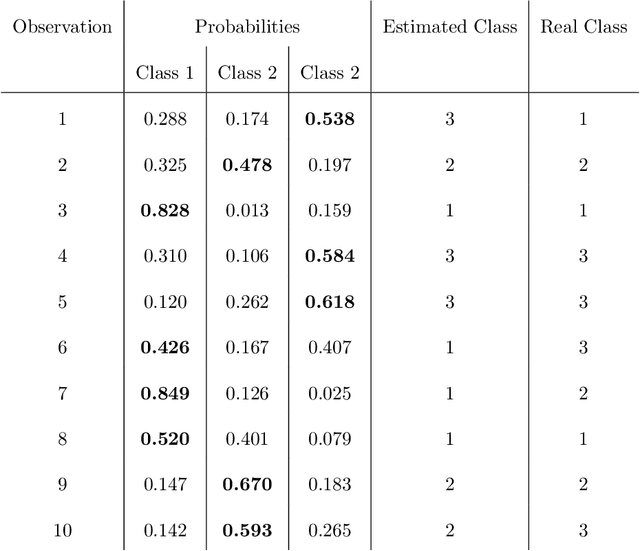
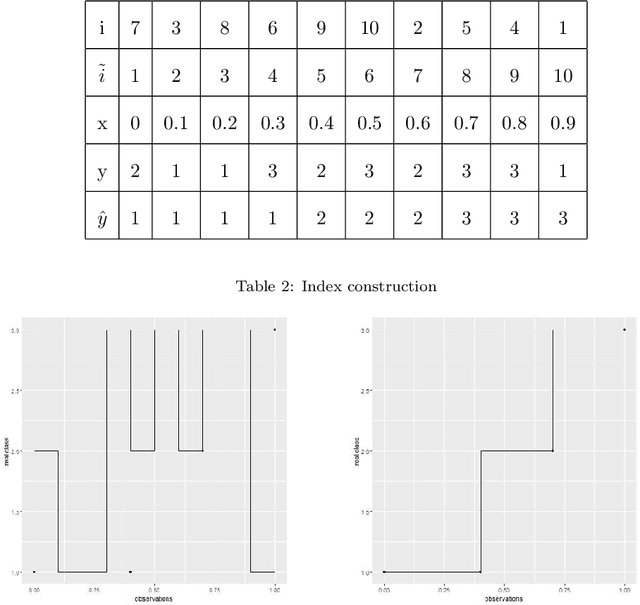
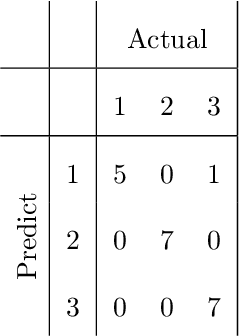
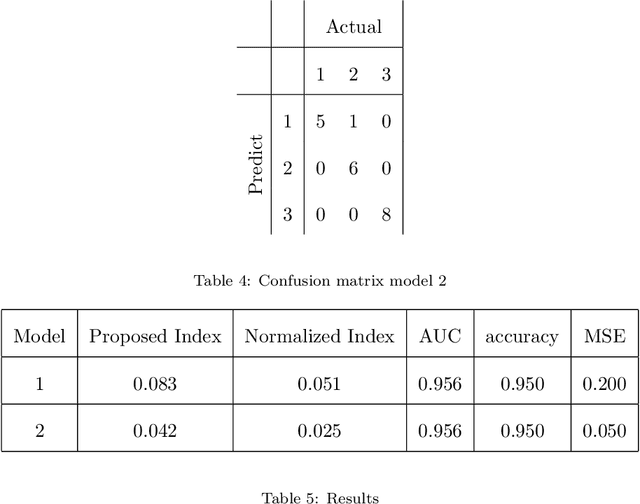
This paper introduces a novel approach to assess model performance for predictive models characterized by an ordinal target variable in order to satisfy the lack of suitable tools in this framework. Our methodological proposal is a new index for model assessment which satisfies mathematical properties and can be easily computed. In order to show how our performance indicator works, empirical evidence achieved on a toy examples and simulated data are provided. On the basis of results at hand, we underline that our approach discriminates better for model selection with respect to performance indexes proposed in the literature.