 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Spectro-temporal Artifacts for Detecting Synthesized Speech
Oct 11, 2022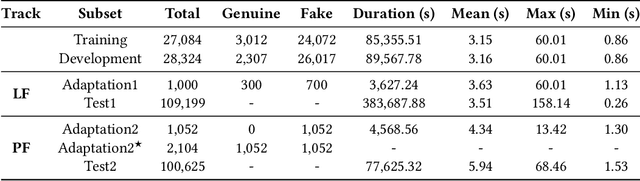
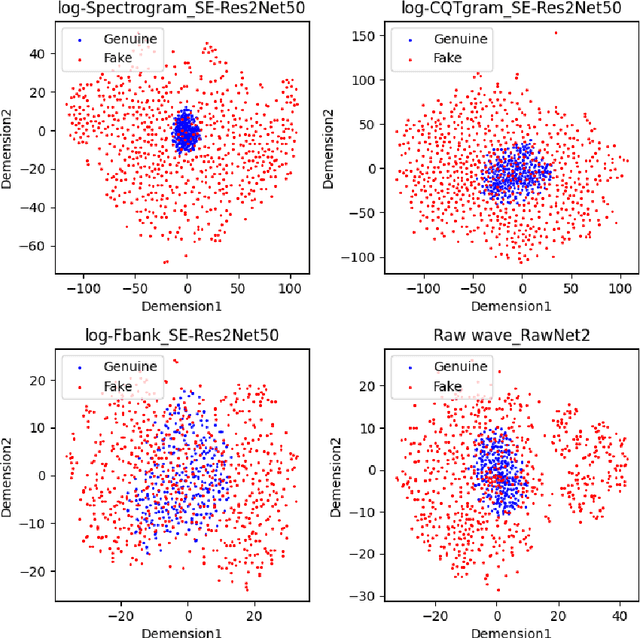
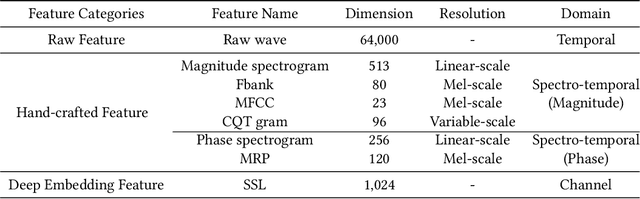

The Audio Deep Synthesis Detection (ADD) Challenge has been held to detect generated human-like speech. With our submitted system, this paper provides an overall assessment of track 1 (Low-quality Fake Audio Detection) and track 2 (Partially Fake Audio Detection). In this paper, spectro-temporal artifacts were detected using raw temporal signals, spectral features, as well as deep embedding features. To address track 1, low-quality data augmentation, domain adaptation via finetuning, and various complementary feature information fusion were aggregated in our system. Furthermore, we analyzed the clustering characteristics of subsystems with different features by visualization method and explained the effectiveness of our proposed greedy fusion strategy. As for track 2, frame transition and smoothing were detected using self-supervised learning structure to capture the manipulation of PF attacks in the time domain. We ranked 4th and 5th in track 1 and track 2, respectively.