 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Why Things Go Where They Go: Interpretable Constructs of Human Organizational Preferences
Dec 31, 2025Robotic systems for household object rearrangement often rely on latent preference models inferred from human demonstrations. While effective at prediction, these models offer limited insight into the interpretable factors that guide human decisions. We introduce an explicit formulation of object arrangement preferences along four interpretable constructs: spatial practicality (putting items where they naturally fit best in the space), habitual convenience (making frequently used items easy to reach), semantic coherence (placing items together if they are used for the same task or are contextually related), and commonsense appropriateness (putting things where people would usually expect to find them). To capture these constructs, we designed and validated a self-report questionnaire through a 63-participant online study. Results confirm the psychological distinctiveness of these constructs and their explanatory power across two scenarios (kitchen and living room). We demonstrate the utility of these constructs by integrating them into a Monte Carlo Tree Search (MCTS) planner and show that when guided by participant-derived preferences, our planner can generate reasonable arrangements that closely align with those generated by participants. This work contributes a compact, interpretable formulation of object arrangement preferences and a demonstration of how it can be operationalized for robot planning.
A Benchmark for Cycling Close Pass Near Miss Event Detection from Video Streams
Apr 24, 2023



Cycling is a healthy and sustainable mode of transport. However, interactions with motor vehicles remain a key barrier to increased cycling participation. The ability to detect potentially dangerous interactions from on-bike sensing could provide important information to riders and policy makers. Thus, automated detection of conflict between cyclists and drivers has attracted researchers from both computer vision and road safety communities. In this paper, we introduce a novel benchmark, called Cyc-CP, towards cycling close pass near miss event detection from video streams. We first divide this task into scene-level and instance-level problems. Scene-level detection asks an algorithm to predict whether there is a close pass near miss event in the input video clip. Instance-level detection aims to detect which vehicle in the scene gives rise to a close pass near miss. We propose two benchmark models based on deep learning techniques for these two problems. For training and testing those models, we construct a synthetic dataset and also collect a real-world dataset. Our models can achieve 88.13% and 84.60% accuracy on the real-world dataset, respectively. We envision this benchmark as a test-bed to accelerate cycling close pass near miss detection and facilitate interaction between the fields of road safety, intelligent transportation systems and artificial intelligence. Both the benchmark datasets and detection models will be available at https://github.com/SustainableMobility/cyc-cp to facilitate experimental reproducibility and encourage more in-depth research in the field.
Partial Observability during DRL for Robot Control
Sep 12, 2022
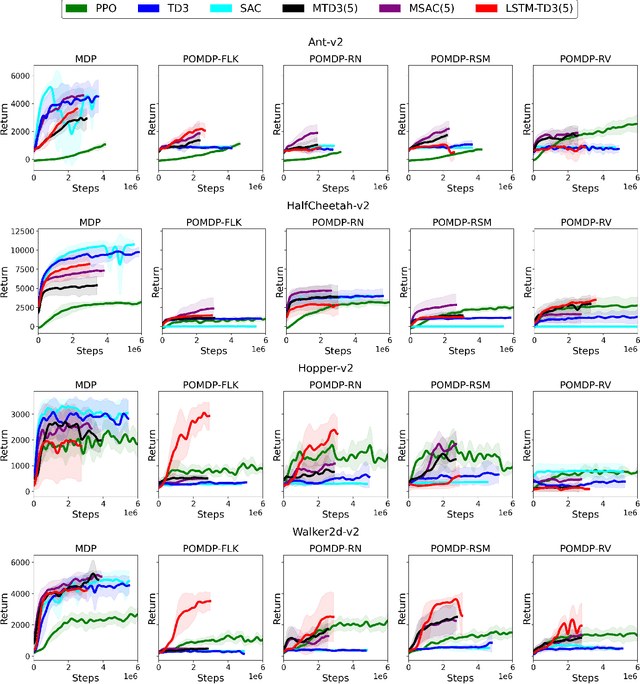
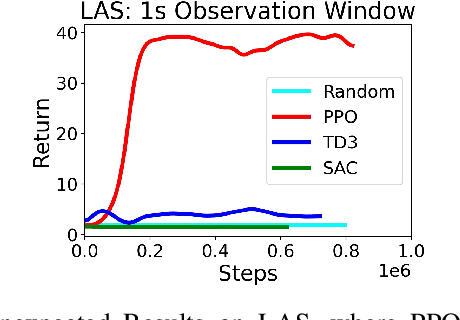
Deep Reinforcement Learning (DRL) has made tremendous advances in both simulated and real-world robot control tasks in recent years. Nevertheless, applying DRL to novel robot control tasks is still challenging, especially when researchers have to design the action and observation space and the reward function. In this paper, we investigate partial observability as a potential failure source of applying DRL to robot control tasks, which can occur when researchers are not confident whether the observation space fully represents the underlying state. We compare the performance of three common DRL algorithms, TD3, SAC and PPO under various partial observability conditions. We find that TD3 and SAC become easily stuck in local optima and underperform PPO. We propose multi-step versions of the vanilla TD3 and SAC to improve robustness to partial observability based on one-step bootstrapping.
Memory-based Deep Reinforcement Learning for POMDP
Feb 25, 2021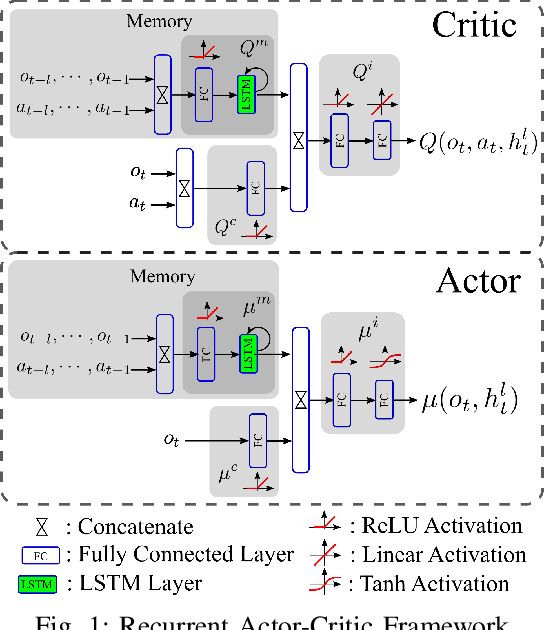
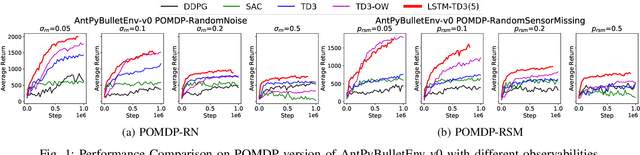
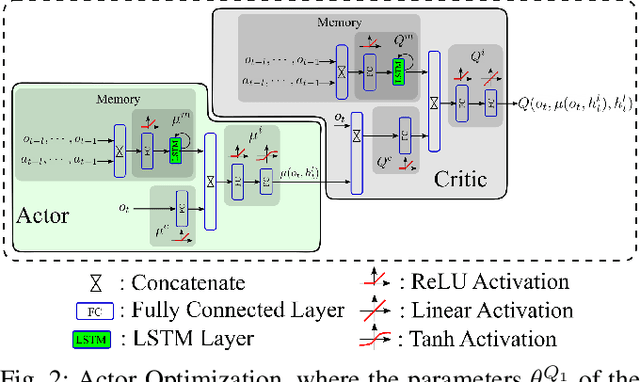
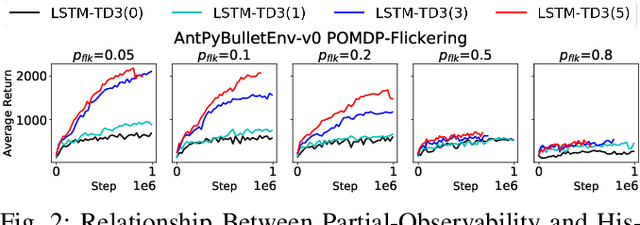
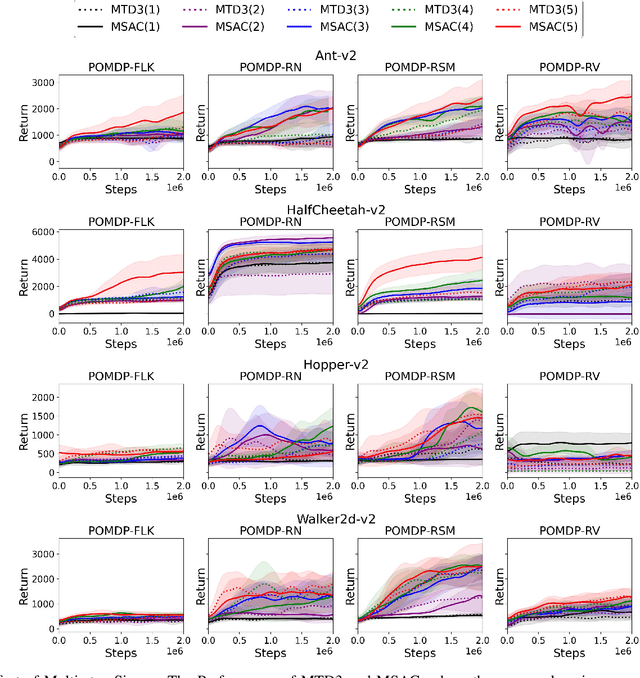
A promising characteristic of Deep Reinforcement Learning (DRL) is its capability to learn optimal policy in an end-to-end manner without relying on feature engineering. However, most approaches assume a fully observable state space, i.e. fully observable Markov Decision Process (MDP). In real-world robotics, this assumption is unpractical, because of the sensor issues such as sensors' capacity limitation and sensor noise, and the lack of knowledge about if the observation design is complete or not. These scenarios lead to Partially Observable MDP (POMDP) and need special treatment. In this paper, we propose Long-Short-Term-Memory-based Twin Delayed Deep Deterministic Policy Gradient (LSTM-TD3) by introducing a memory component to TD3, and compare its performance with other DRL algorithms in both MDPs and POMDPs. Our results demonstrate the significant advantages of the memory component in addressing POMDPs, including the ability to handle missing and noisy observation data.
The Effect of Multi-step Methods on Overestimation in Deep Reinforcement Learning
Jun 23, 2020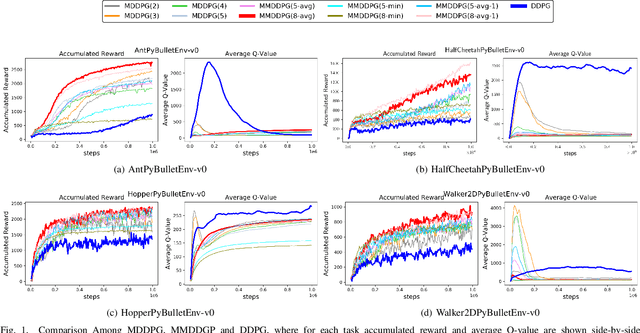
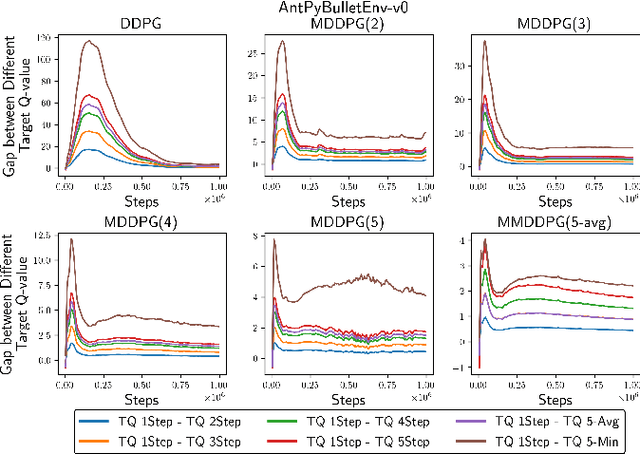
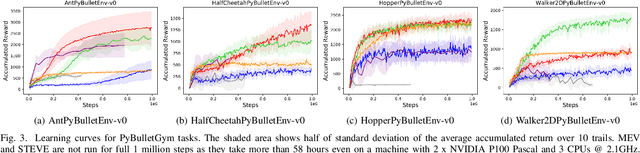
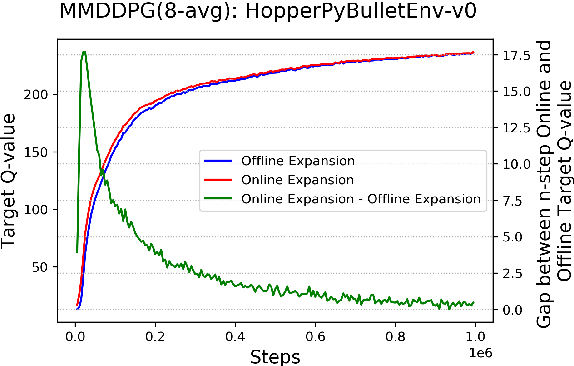
Multi-step (also called n-step) methods in reinforcement learning (RL) have been shown to be more efficient than the 1-step method due to faster propagation of the reward signal, both theoretically and empirically, in tasks exploiting tabular representation of the value-function. Recently, research in Deep Reinforcement Learning (DRL) also shows that multi-step methods improve learning speed and final performance in applications where the value-function and policy are represented with deep neural networks. However, there is a lack of understanding about what is actually contributing to the boost of performance. In this work, we analyze the effect of multi-step methods on alleviating the overestimation problem in DRL, where multi-step experiences are sampled from a replay buffer. Specifically building on top of Deep Deterministic Policy Gradient (DDPG), we propose Multi-step DDPG (MDDPG), where different step sizes are manually set, and its variant called Mixed Multi-step DDPG (MMDDPG) where an average over different multi-step backups is used as update target of Q-value function. Empirically, we show that both MDDPG and MMDDPG are significantly less affected by the overestimation problem than DDPG with 1-step backup, which consequently results in better final performance and learning speed. We also discuss the advantages and disadvantages of different ways to do multi-step expansion in order to reduce approximation error, and expose the tradeoff between overestimation and underestimation that underlies offline multi-step methods. Finally, we compare the computational resource needs of Twin Delayed Deep Deterministic Policy Gradient (TD3), a state-of-art algorithm proposed to address overestimation in actor-critic methods, and our proposed methods, since they show comparable final performance and learning speed.
Learning to Engage with Interactive Systems: A field Study
Apr 14, 2019
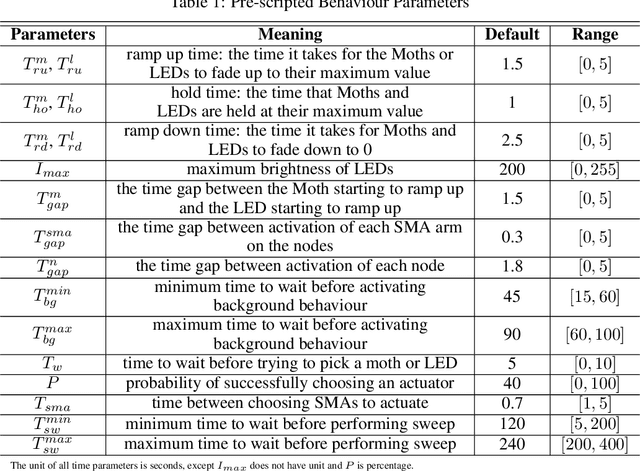
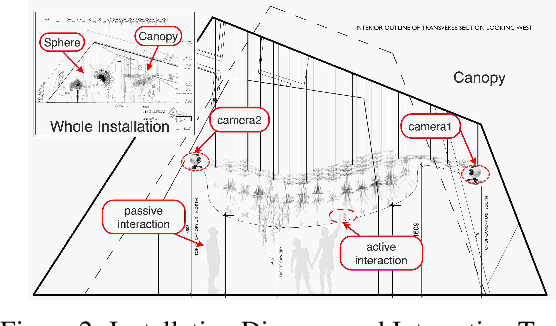
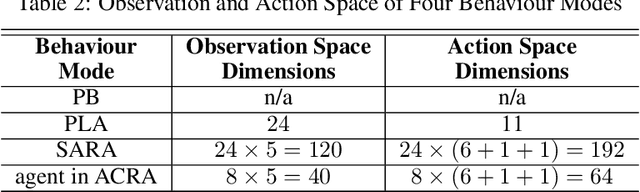
Physical agents that can autonomously generate engaging, life-like behaviour will lead to more responsive and interesting robots and other autonomous systems. Although many advances have been made for one-to-one interactions in well controlled settings, future physical agents should be capable of interacting with humans in natural settings, including group interaction. In order to generate engaging behaviours, the autonomous system must first be able to estimate its human partners' engagement level. In this paper, we propose an approach for estimating engagement from behaviour and use the measure within a reinforcement learning framework to learn engaging interactive behaviours. The proposed approach is implemented in an interactive sculptural system in a museum setting. We compare the learning system to a baseline using pre-scripted interactive behaviours. Analysis based on sensory data and survey data shows that adaptable behaviours within a perceivable and understandable range can achieve higher engagement and likeability.