 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-based Deep Reinforcement Learning for POMDP
Paper and Code
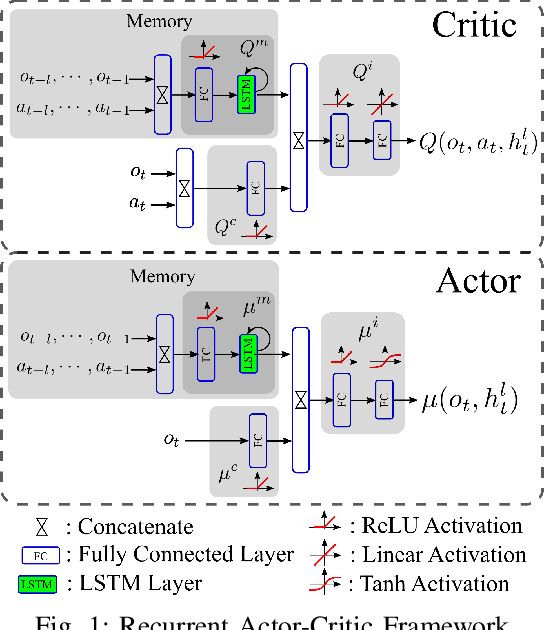
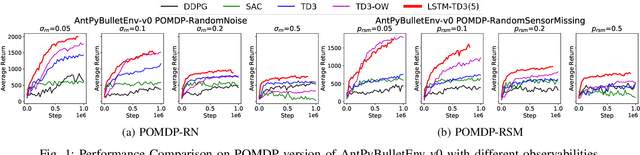
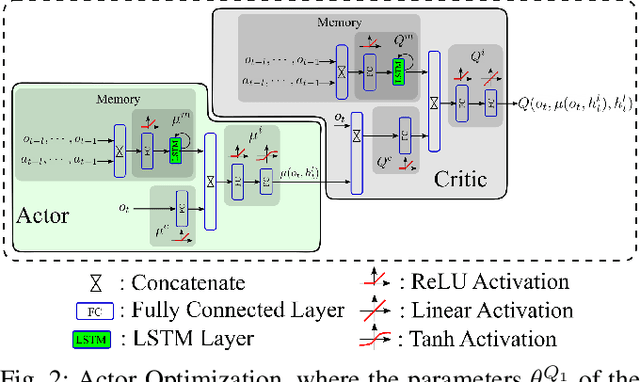
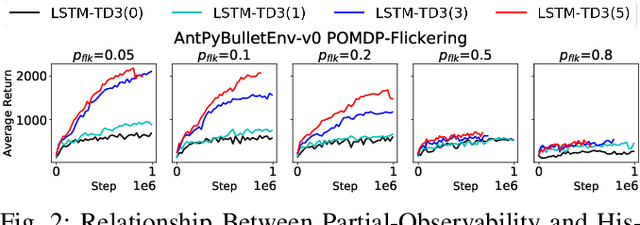
A promising characteristic of Deep Reinforcement Learning (DRL) is its capability to learn optimal policy in an end-to-end manner without relying on feature engineering. However, most approaches assume a fully observable state space, i.e. fully observable Markov Decision Process (MDP). In real-world robotics, this assumption is unpractical, because of the sensor issues such as sensors' capacity limitation and sensor noise, and the lack of knowledge about if the observation design is complete or not. These scenarios lead to Partially Observable MDP (POMDP) and need special treatment. In this paper, we propose Long-Short-Term-Memory-based Twin Delayed Deep Deterministic Policy Gradient (LSTM-TD3) by introducing a memory component to TD3, and compare its performance with other DRL algorithms in both MDPs and POMDPs. Our results demonstrate the significant advantages of the memory component in addressing POMDPs, including the ability to handle missing and noisy observation data.