 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Observability during DRL for Robot Control
Sep 12, 2022
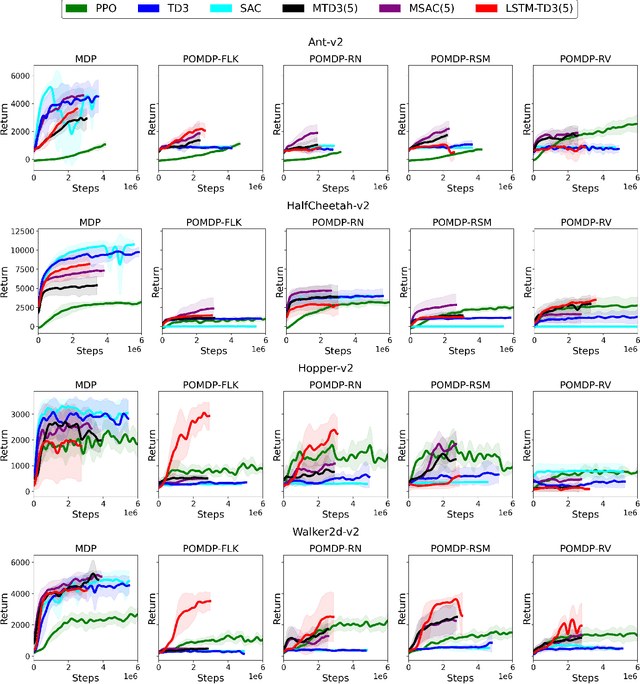
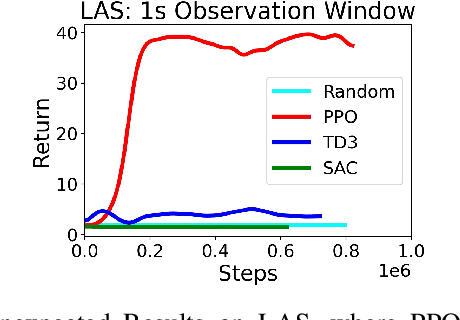
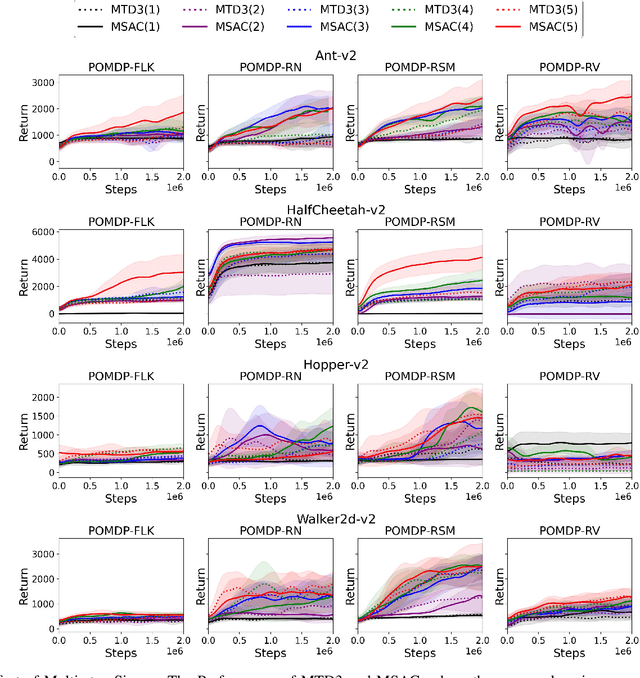
Deep Reinforcement Learning (DRL) has made tremendous advances in both simulated and real-world robot control tasks in recent years. Nevertheless, applying DRL to novel robot control tasks is still challenging, especially when researchers have to design the action and observation space and the reward function. In this paper, we investigate partial observability as a potential failure source of applying DRL to robot control tasks, which can occur when researchers are not confident whether the observation space fully represents the underlying state. We compare the performance of three common DRL algorithms, TD3, SAC and PPO under various partial observability conditions. We find that TD3 and SAC become easily stuck in local optima and underperform PPO. We propose multi-step versions of the vanilla TD3 and SAC to improve robustness to partial observability based on one-step bootstrapping.
Memory-based Deep Reinforcement Learning for POMDP
Feb 25, 2021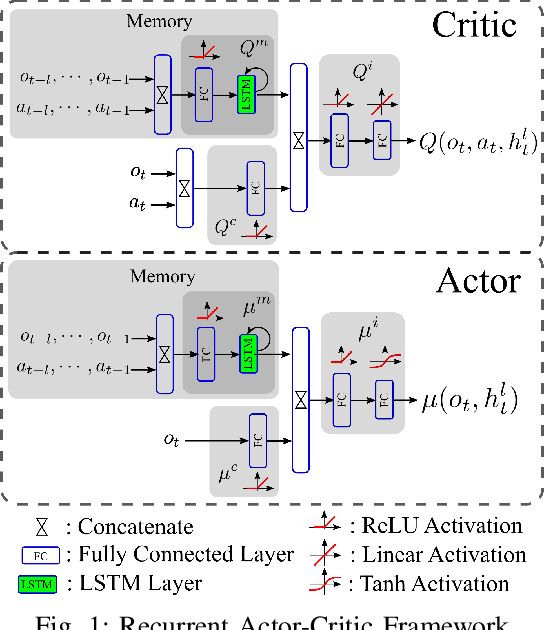
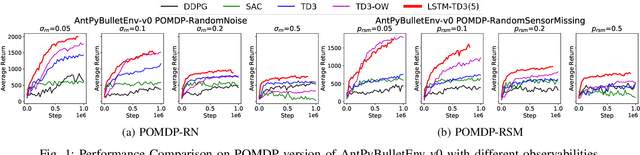
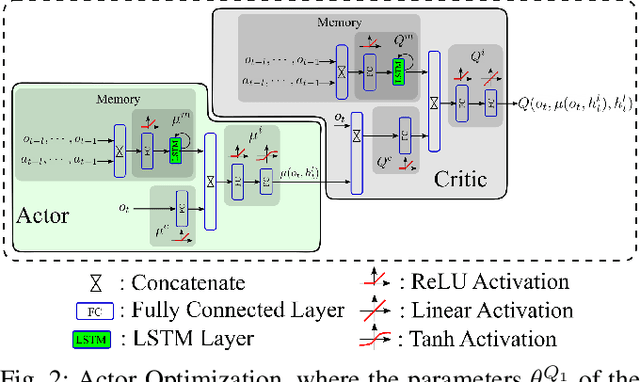
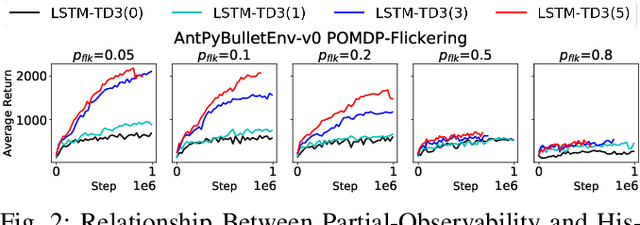
A promising characteristic of Deep Reinforcement Learning (DRL) is its capability to learn optimal policy in an end-to-end manner without relying on feature engineering. However, most approaches assume a fully observable state space, i.e. fully observable Markov Decision Process (MDP). In real-world robotics, this assumption is unpractical, because of the sensor issues such as sensors' capacity limitation and sensor noise, and the lack of knowledge about if the observation design is complete or not. These scenarios lead to Partially Observable MDP (POMDP) and need special treatment. In this paper, we propose Long-Short-Term-Memory-based Twin Delayed Deep Deterministic Policy Gradient (LSTM-TD3) by introducing a memory component to TD3, and compare its performance with other DRL algorithms in both MDPs and POMDPs. Our results demonstrate the significant advantages of the memory component in addressing POMDPs, including the ability to handle missing and noisy observation data.
The Effect of Multi-step Methods on Overestimation in Deep Reinforcement Learning
Jun 23, 2020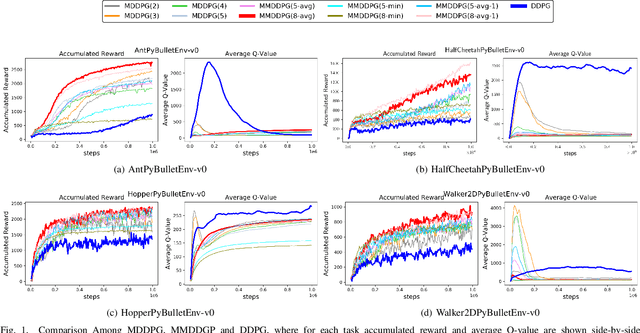
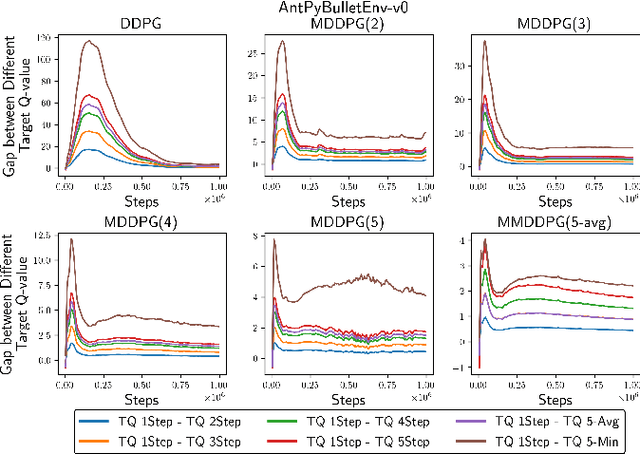
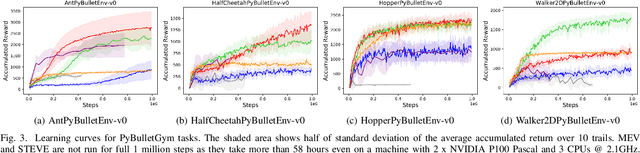
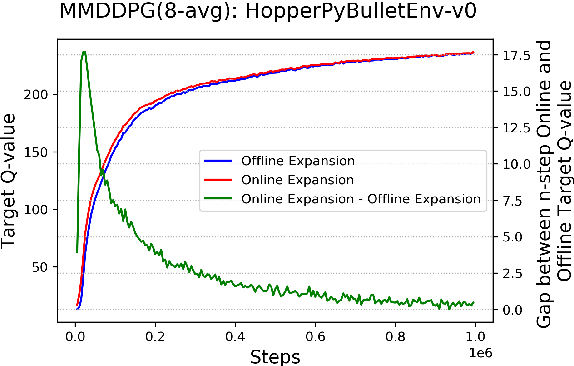
Multi-step (also called n-step) methods in reinforcement learning (RL) have been shown to be more efficient than the 1-step method due to faster propagation of the reward signal, both theoretically and empirically, in tasks exploiting tabular representation of the value-function. Recently, research in Deep Reinforcement Learning (DRL) also shows that multi-step methods improve learning speed and final performance in applications where the value-function and policy are represented with deep neural networks. However, there is a lack of understanding about what is actually contributing to the boost of performance. In this work, we analyze the effect of multi-step methods on alleviating the overestimation problem in DRL, where multi-step experiences are sampled from a replay buffer. Specifically building on top of Deep Deterministic Policy Gradient (DDPG), we propose Multi-step DDPG (MDDPG), where different step sizes are manually set, and its variant called Mixed Multi-step DDPG (MMDDPG) where an average over different multi-step backups is used as update target of Q-value function. Empirically, we show that both MDDPG and MMDDPG are significantly less affected by the overestimation problem than DDPG with 1-step backup, which consequently results in better final performance and learning speed. We also discuss the advantages and disadvantages of different ways to do multi-step expansion in order to reduce approximation error, and expose the tradeoff between overestimation and underestimation that underlies offline multi-step methods. Finally, we compare the computational resource needs of Twin Delayed Deep Deterministic Policy Gradient (TD3), a state-of-art algorithm proposed to address overestimation in actor-critic methods, and our proposed methods, since they show comparable final performance and learning speed.
Affective Movement Generation using Laban Effort and Shape and Hidden Markov Models
Jun 10, 2020



Body movements are an important communication medium through which affective states can be discerned. Movements that convey affect can also give machines life-like attributes and help to create a more engaging human-machine interaction. This paper presents an approach for automatic affective movement generation that makes use of two movement abstractions: 1) Laban movement analysis (LMA), and 2) hidden Markov modeling. The LMA provides a systematic tool for an abstract representation of the kinematic and expressive characteristics of movements. Given a desired motion path on which a target emotion is to be overlaid, the proposed approach searches a labeled dataset in the LMA Effort and Shape space for similar movements to the desired motion path that convey the target emotion. An HMM abstraction of the identified movements is obtained and used with the desired motion path to generate a novel movement that is a modulated version of the desired motion path that conveys the target emotion. The extent of modulation can be varied, trading-off between kinematic and affective constraints in the generated movement. The proposed approach is tested using a full-body movement dataset. The efficacy of the proposed approach in generating movements with recognizable target emotions is assessed using a validated automatic recognition model and a user study. The target emotions were correctly recognized from the generated movements at a rate of 72% using the recognition model. Furthermore, participants in the user study were able to correctly perceive the target emotions from a sample of generated movements, although some cases of confusion were also observed.
Learning to Engage with Interactive Systems: A field Study
Apr 14, 2019
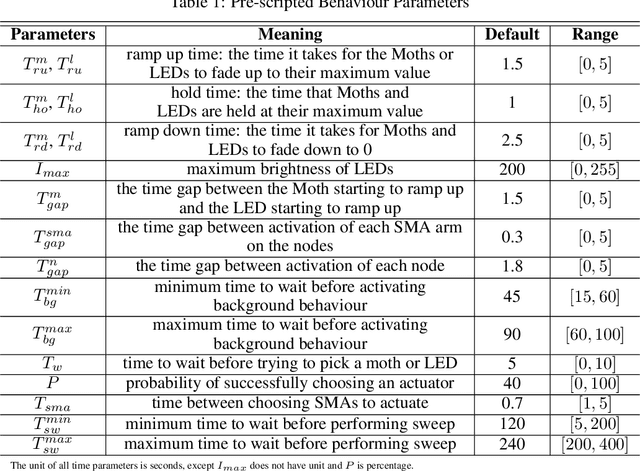
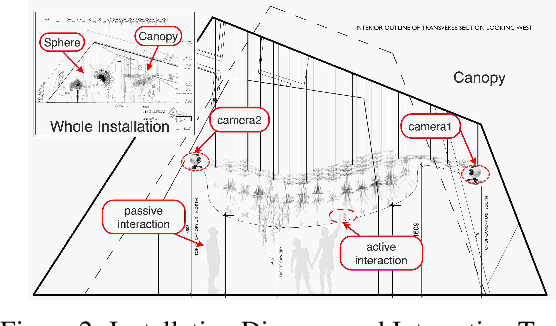
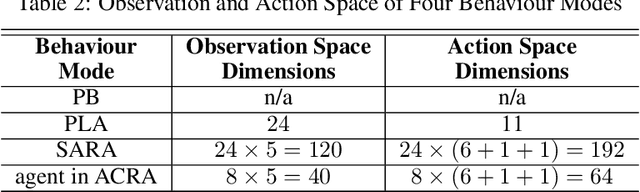
Physical agents that can autonomously generate engaging, life-like behaviour will lead to more responsive and interesting robots and other autonomous systems. Although many advances have been made for one-to-one interactions in well controlled settings, future physical agents should be capable of interacting with humans in natural settings, including group interaction. In order to generate engaging behaviours, the autonomous system must first be able to estimate its human partners' engagement level. In this paper, we propose an approach for estimating engagement from behaviour and use the measure within a reinforcement learning framework to learn engaging interactive behaviours. The proposed approach is implemented in an interactive sculptural system in a museum setting. We compare the learning system to a baseline using pre-scripted interactive behaviours. Analysis based on sensory data and survey data shows that adaptable behaviours within a perceivable and understandable range can achieve higher engagement and likeability.