 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Communication Gain and Delay Cost Under Cross-Timestep Delays in Cooperative Multi-Agent Reinforcement Learning
Apr 04, 2026Communication is essential for coordination in \emph{cooperative} multi-agent reinforcement learning under partial observability, yet \emph{cross-timestep} delays cause messages to arrive multiple timesteps after generation, inducing temporal misalignment and making information stale when consumed. We formalize this setting as a delayed-communication partially observable Markov game (DeComm-POMG) and decompose a message's effect into \emph{communication gain} and \emph{delay cost}, yielding the Communication Gain and Delay Cost (CGDC) metric. We further establish a value-loss bound showing that the degradation induced by delayed messages is upper-bounded by a discounted accumulation of an information gap between the action distributions induced by timely versus delayed messages. Guided by CGDC, we propose \textbf{CDCMA}, an actor--critic framework that requests messages only when predicted CGDC is positive, predicts future observations to reduce misalignment at consumption, and fuses delayed messages via CGDC-guided attention. Experiments on no-teammate-vision variants of Cooperative Navigation and Predator Prey, and on SMAC maps across multiple delay levels show consistent improvements in performance, robustness, and generalization, with ablations validating each component.
InjectRBP: Steering Large Language Model Reasoning Behavior via Pattern Injection
Feb 12, 2026Reasoning can significantly enhance the performance of Large Language Models. While recent studies have exploited behavior-related prompts adjustment to enhance reasoning, these designs remain largely intuitive and lack a systematic analysis of the underlying behavioral patterns. Motivated by this, we investigate how models' reasoning behaviors shape reasoning from the perspective of behavioral patterns. We observe that models exhibit adaptive distributions of reasoning behaviors when responding to specific types of questions, and that structurally injecting these patterns can substantially influence the quality of the models' reasoning processes and outcomes. Building on these findings, we propose two optimization methods that require no parameter updates: InjectCorrect and InjectRLOpt. InjectCorrect guides the model by imitating behavioral patterns derived from its own past correct answers. InjectRLOpt learns a value function from historical behavior-pattern data and, via our proposed Reliability-Aware Softmax Policy, generates behavioral injectant during inference to steer the reasoning process. Our experiments demonstrate that both methods can improve model performance across various reasoning tasks without requiring any modifications to model parameters, achieving gains of up to 5.34% and 8.67%, respectively.
Test-driven Reinforcement Learning
Nov 15, 2025



Reinforcement learning (RL) has been recognized as a powerful tool for robot control tasks. RL typically employs reward functions to define task objectives and guide agent learning. However, since the reward function serves the dual purpose of defining the optimal goal and guiding learning, it is challenging to design the reward function manually, which often results in a suboptimal task representation. To tackle the reward design challenge in RL, inspired by the satisficing theory, we propose a Test-driven Reinforcement Learning (TdRL) framework. In the TdRL framework, multiple test functions are used to represent the task objective rather than a single reward function. Test functions can be categorized as pass-fail tests and indicative tests, each dedicated to defining the optimal objective and guiding the learning process, respectively, thereby making defining tasks easier. Building upon such a task definition, we first prove that if a trajectory return function assigns higher returns to trajectories closer to the optimal trajectory set, maximum entropy policy optimization based on this return function will yield a policy that is closer to the optimal policy set. Then, we introduce a lexicographic heuristic approach to compare the relative distance relationship between trajectories and the optimal trajectory set for learning the trajectory return function. Furthermore, we develop an algorithm implementation of TdRL. Experimental results on the DeepMind Control Suite benchmark demonstrate that TdRL matches or outperforms handcrafted reward methods in policy training, with greater design simplicity and inherent support for multi-objective optimization. We argue that TdRL offers a novel perspective for representing task objectives, which could be helpful in addressing the reward design challenges in RL applications.
Ordering-Based Causal Discovery with Reinforcement Learning
May 17, 2021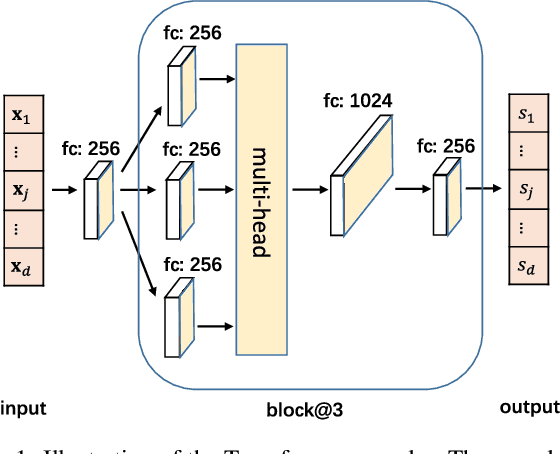

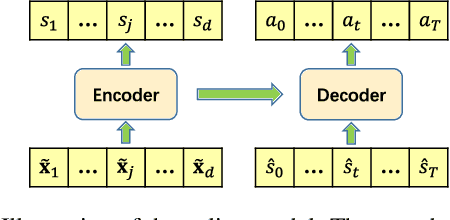
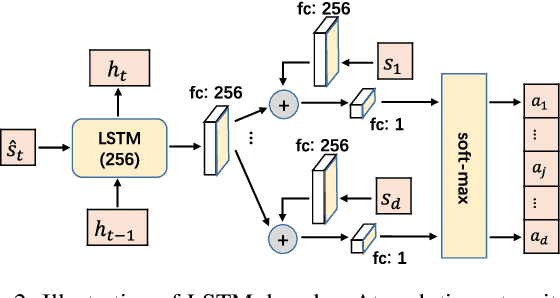
It is a long-standing question to discover causal relations among a set of variables in many empirical sciences. Recently, Reinforcement Learning (RL) has achieved promising results in causal discovery from observational data. However, searching the space of directed graphs and enforcing acyclicity by implicit penalties tend to be inefficient and restrict the existing RL-based method to small scale problems. In this work, we propose a novel RL-based approach for causal discovery, by incorporating RL into the ordering-based paradigm. Specifically, we formulate the ordering search problem as a multi-step Markov decision process, implement the ordering generating process with an encoder-decoder architecture, and finally use RL to optimize the proposed model based on the reward mechanisms designed for~each ordering. A generated ordering would then be processed using variable selection to obtain the final causal graph. We analyze the consistency and computational complexity of the proposed method, and empirically show that a pretrained model can be exploited to accelerate training. Experimental results on both synthetic and real data sets shows that the proposed method achieves a much improved performance over existing RL-based method.
Large-scale Traffic Signal Control Using a Novel Multi-Agent Reinforcement Learning
Aug 10, 2019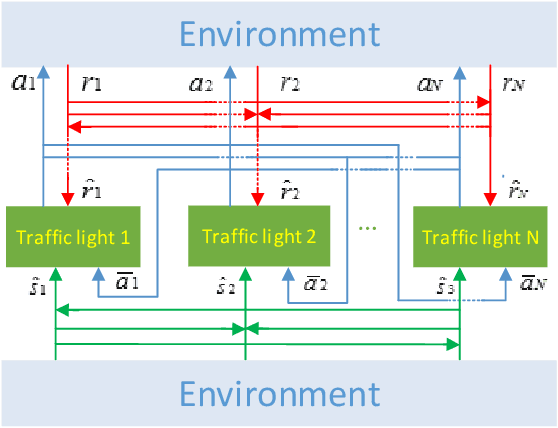
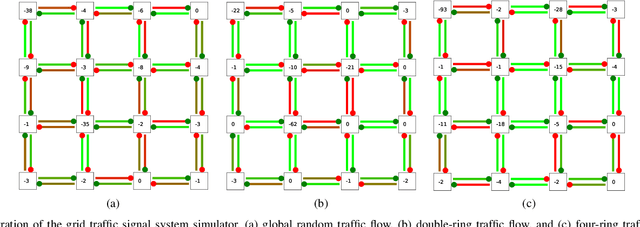
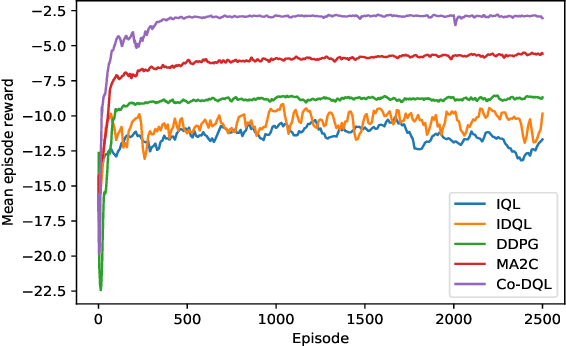
Finding the optimal signal timing strategy is a difficult task for the problem of large-scale traffic signal control (TSC). Multi-Agent Reinforcement Learning (MARL) is a promising method to solve this problem. However, there is still room for improvement in extending to large-scale problems and modeling the behaviors of other agents for each individual agent. In this paper, a new MARL, called Cooperative double Q-learning (Co-DQL), is proposed, which has several prominent features. It uses a highly scalable independent double Q-learning method based on double estimators and the UCB policy, which can eliminate the over-estimation problem existing in traditional independent Q-learning while ensuring exploration. It uses mean field approximation to model the interaction among agents, thereby making agents learn a better cooperative strategy. In order to improve the stability and robustness of the learning process, we introduce a new reward allocation mechanism and a local state sharing method. In addition, we analyze the convergence properties of the proposed algorithm. Co-DQL is applied on TSC and tested on a multi-traffic signal simulator. According to the results obtained on several traffic scenarios, Co- DQL outperforms several state-of-the-art decentralized MARL algorithms. It can effectively shorten the average waiting time of the vehicles in the whole road system.