 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Traffic Signal Control Using a Novel Multi-Agent Reinforcement Learning
Aug 10, 2019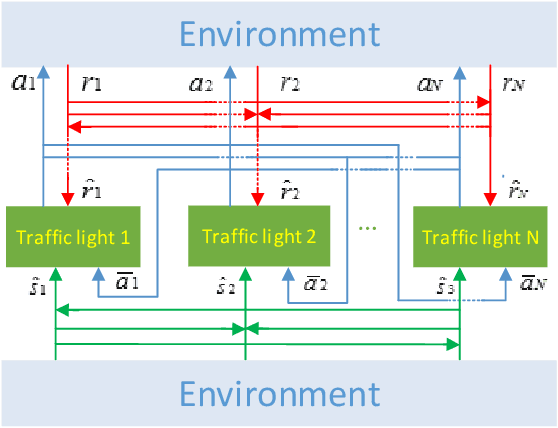
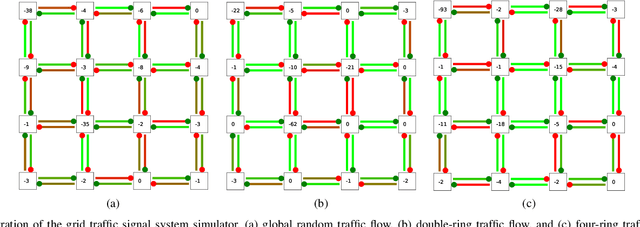
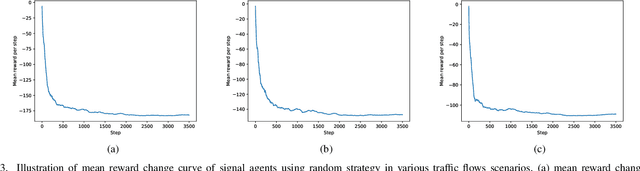
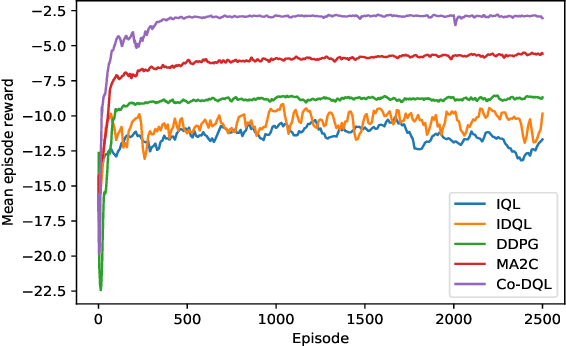
Finding the optimal signal timing strategy is a difficult task for the problem of large-scale traffic signal control (TSC). Multi-Agent Reinforcement Learning (MARL) is a promising method to solve this problem. However, there is still room for improvement in extending to large-scale problems and modeling the behaviors of other agents for each individual agent. In this paper, a new MARL, called Cooperative double Q-learning (Co-DQL), is proposed, which has several prominent features. It uses a highly scalable independent double Q-learning method based on double estimators and the UCB policy, which can eliminate the over-estimation problem existing in traditional independent Q-learning while ensuring exploration. It uses mean field approximation to model the interaction among agents, thereby making agents learn a better cooperative strategy. In order to improve the stability and robustness of the learning process, we introduce a new reward allocation mechanism and a local state sharing method. In addition, we analyze the convergence properties of the proposed algorithm. Co-DQL is applied on TSC and tested on a multi-traffic signal simulator. According to the results obtained on several traffic scenarios, Co- DQL outperforms several state-of-the-art decentralized MARL algorithms. It can effectively shorten the average waiting time of the vehicles in the whole road system.