 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Meritocratic Fairness in Linear Contextual Bandits
Jun 07, 2022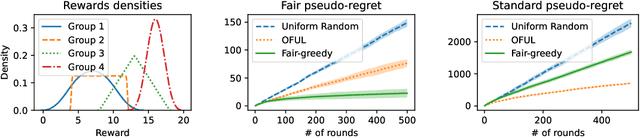
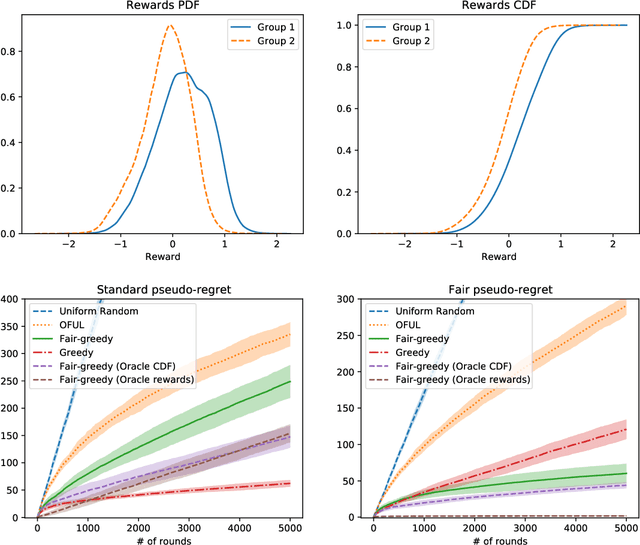
We study the linear contextual bandit problem where an agent has to select one candidate from a pool and each candidate belongs to a sensitive group. In this setting, candidates' rewards may not be directly comparable between groups, for example when the agent is an employer hiring candidates from different ethnic groups and some groups have a lower reward due to discriminatory bias and/or social injustice. We propose a notion of fairness that states that the agent's policy is fair when it selects a candidate with highest relative rank, which measures how good the reward is when compared to candidates from the same group. This is a very strong notion of fairness, since the relative rank is not directly observed by the agent and depends on the underlying reward model and on the distribution of rewards. Thus we study the problem of learning a policy which approximates a fair policy under the condition that the contexts are independent between groups and the distribution of rewards of each group is absolutely continuous. In particular, we design a greedy policy which at each round constructs a ridge regression estimator from the observed context-reward pairs, and then computes an estimate of the relative rank of each candidate using the empirical cumulative distribution function. We prove that the greedy policy achieves, after $T$ rounds, up to log factors and with high probability, a fair pseudo-regret of order $\sqrt{dT}$, where $d$ is the dimension of the context vectors. The policy also satisfies demographic parity at each round when averaged over all possible information available before the selection. We finally show with a proof of concept simulation that our policy achieves sub-linear fair pseudo-regret also in practice.
Meta Representation Learning with Contextual Linear Bandits
May 30, 2022Meta-learning seeks to build algorithms that rapidly learn how to solve new learning problems based on previous experience. In this paper we investigate meta-learning in the setting of stochastic linear bandit tasks. We assume that the tasks share a low dimensional representation, which has been partially acquired from previous learning tasks. We aim to leverage this information in order to learn a new downstream bandit task, which shares the same representation. Our principal contribution is to show that if the learned representation estimates well the unknown one, then the downstream task can be efficiently learned by a greedy policy that we propose in this work. We derive an upper bound on the regret of this policy, which is, up to logarithmic factors, of order $r\sqrt{N}(1\vee \sqrt{d/T})$, where $N$ is the horizon of the downstream task, $T$ is the number of training tasks, $d$ the ambient dimension and $r \ll d$ the dimension of the representation. We highlight that our strategy does not need to know $r$. We note that if $T> d$ our bound achieves the same rate of optimal minimax bandit algorithms using the true underlying representation. Our analysis is inspired and builds in part upon previous work on meta-learning in the i.i.d. full information setting \citep{tripuraneni2021provable,boursier2022trace}. As a separate contribution we show how to relax certain assumptions in those works, thereby improving their representation learning and risk analysis.
Multi-task Representation Learning with Stochastic Linear Bandits
Feb 21, 2022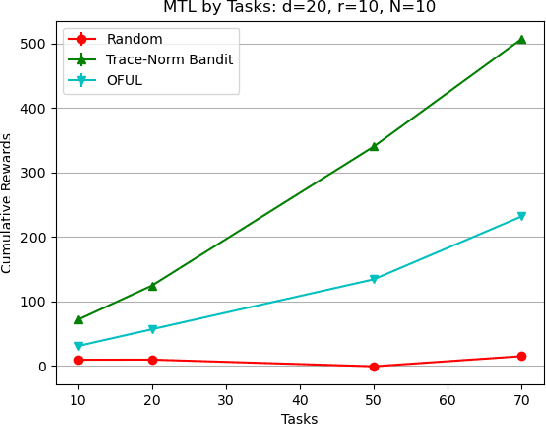

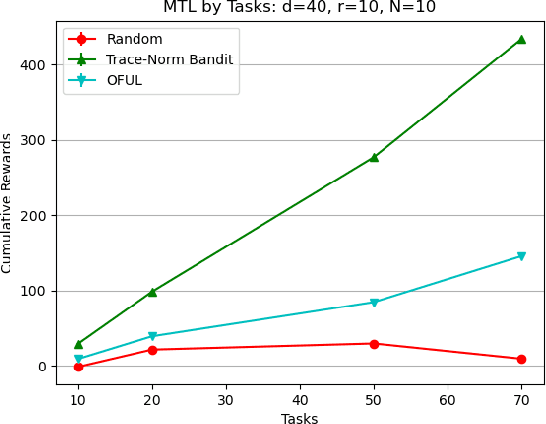
We study the problem of transfer-learning in the setting of stochastic linear bandit tasks. We consider that a low dimensional linear representation is shared across the tasks, and study the benefit of learning this representation in the multi-task learning setting. Following recent results to design stochastic bandit policies, we propose an efficient greedy policy based on trace norm regularization. It implicitly learns a low dimensional representation by encouraging the matrix formed by the task regression vectors to be of low rank. Unlike previous work in the literature, our policy does not need to know the rank of the underlying matrix. We derive an upper bound on the multi-task regret of our policy, which is, up to logarithmic factors, of order $\sqrt{NdT(T+d)r}$, where $T$ is the number of tasks, $r$ the rank, $d$ the number of variables and $N$ the number of rounds per task. We show the benefit of our strategy compared to the baseline $Td\sqrt{N}$ obtained by solving each task independently. We also provide a lower bound to the multi-task regret. Finally, we corroborate our theoretical findings with preliminary experiments on synthetic data.
Online Model Selection: a Rested Bandit Formulation
Dec 07, 2020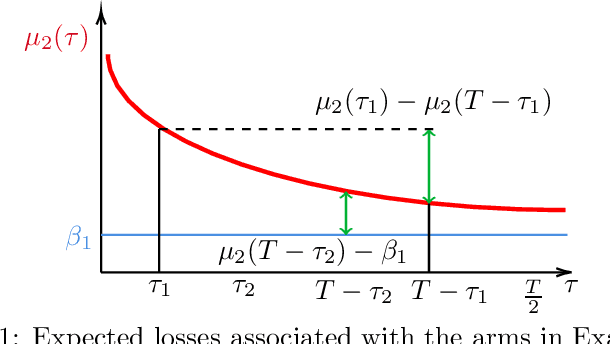
Motivated by a natural problem in online model selection with bandit information, we introduce and analyze a best arm identification problem in the rested bandit setting, wherein arm expected losses decrease with the number of times the arm has been played. The shape of the expected loss functions is similar across arms, and is assumed to be available up to unknown parameters that have to be learned on the fly. We define a novel notion of regret for this problem, where we compare to the policy that always plays the arm having the smallest expected loss at the end of the game. We analyze an arm elimination algorithm whose regret vanishes as the time horizon increases. The actual rate of convergence depends in a detailed way on the postulated functional form of the expected losses. Unlike known model selection efforts in the recent bandit literature, our algorithm exploits the specific structure of the problem to learn the unknown parameters of the expected loss function so as to identify the best arm as quickly as possible. We complement our analysis with a lower bound, indicating strengths and limitations of the proposed solution.
Meta-learning with Stochastic Linear Bandits
May 18, 2020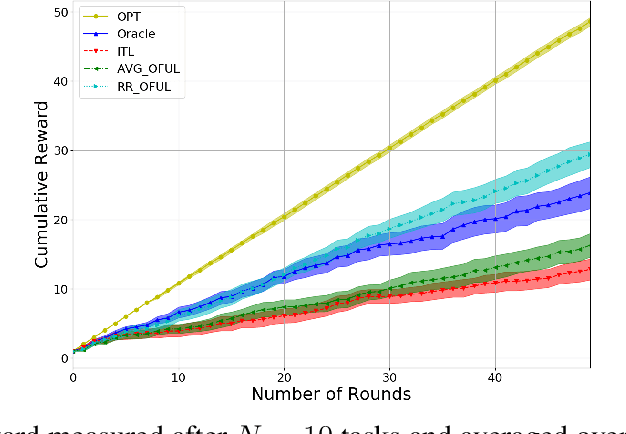
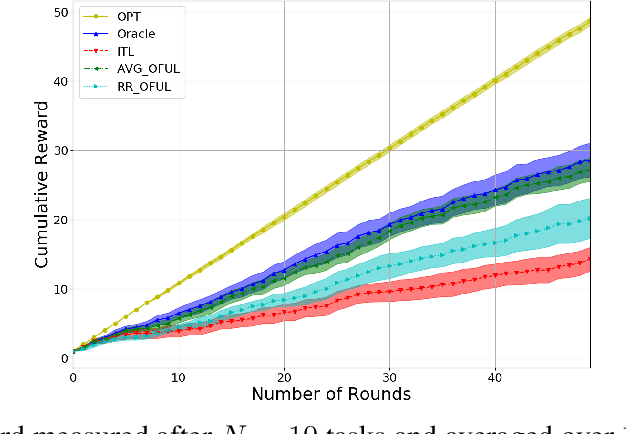
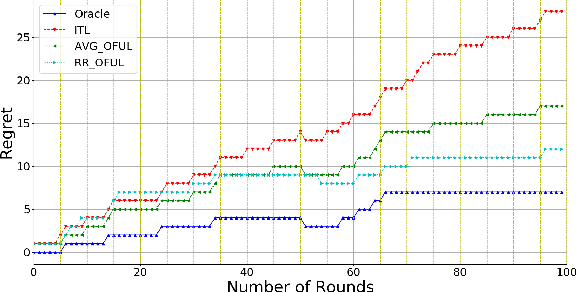
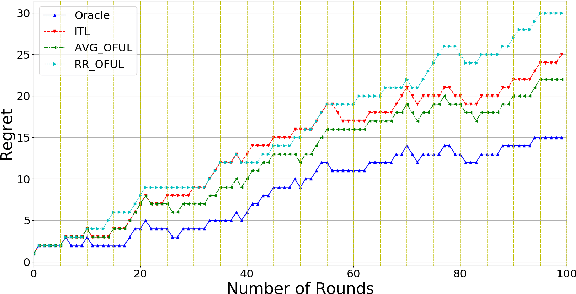
We investigate meta-learning procedures in the setting of stochastic linear bandits tasks. The goal is to select a learning algorithm which works well on average over a class of bandits tasks, that are sampled from a task-distribution. Inspired by recent work on learning-to-learn linear regression, we consider a class of bandit algorithms that implement a regularized version of the well-known OFUL algorithm, where the regularization is a square euclidean distance to a bias vector. We first study the benefit of the biased OFUL algorithm in terms of regret minimization. We then propose two strategies to estimate the bias within the learning-to-learn setting. We show both theoretically and experimentally, that when the number of tasks grows and the variance of the task-distribution is small, our strategies have a significant advantage over learning the tasks in isolation.
Valid distribution-free inferential models for prediction
Jan 24, 2020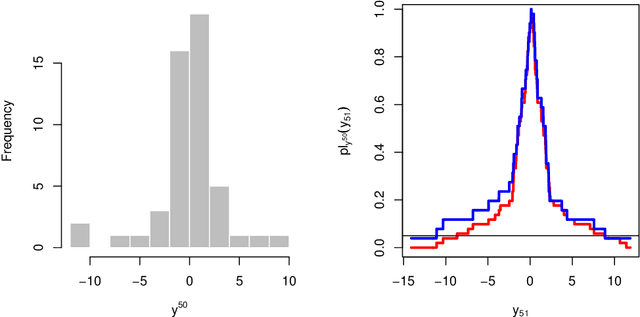
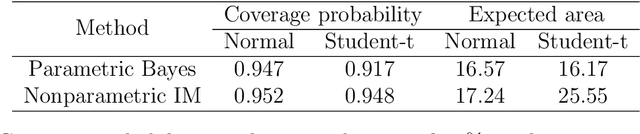
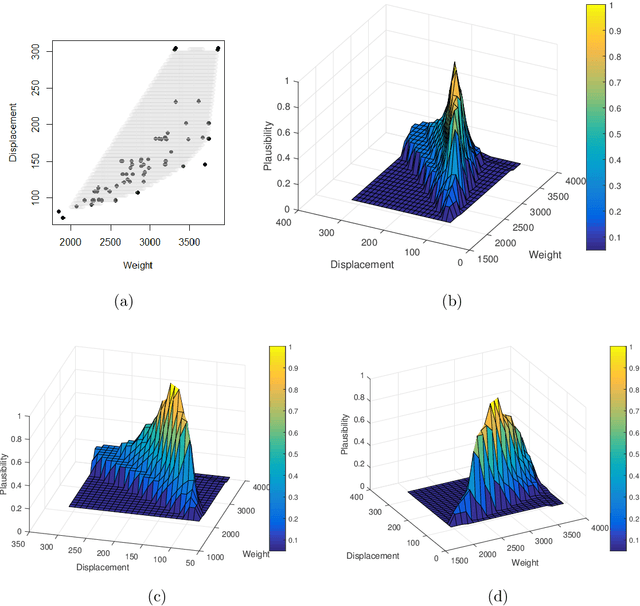
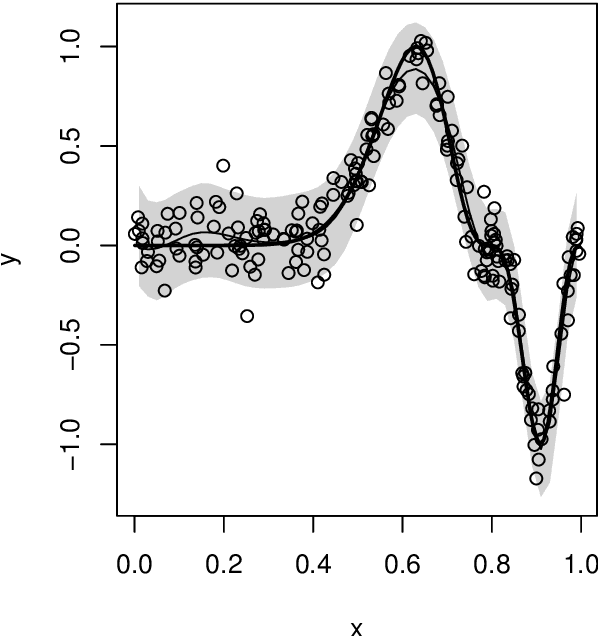
A fundamental problem in statistics and machine learning is that of using observed data to predict future observations. This is particularly challenging for model-based approaches because often the goal is to carry out this prediction with no or minimal model assumptions. For example, the inferential model (IM) approach is attractive because it has certain validity guarantees, but requires specification of a parametric model. Here we show that a new perspective on a recently developed generalized IM approach can be applied to construct an IM for prediction that satisfies the desirable validity guarantees without specification of a model. One important special case of this approach corresponds to the powerful conformal prediction framework and, consequently, the desirable properties of conformal prediction follow immediately from the general IM validity theory. Several numerical examples are presented to illustrate the theory and highlight the method's performance and flexibility.
Stochastic Bandits with Delay-Dependent Payoffs
Oct 11, 2019


Motivated by recommendation problems in music streaming platforms, we propose a nonstationary stochastic bandit model in which the expected reward of an arm depends on the number of rounds that have passed since the arm was last pulled. After proving that finding an optimal policy is NP-hard even when all model parameters are known, we introduce a class of ranking policies provably approximating, to within a constant factor, the expected reward of the optimal policy. We show an algorithm whose regret with respect to the best ranking policy is bounded by $\widetilde{\mathcal{O}}\big(\!\sqrt{kT}\big)$, where $k$ is the number of arms and $T$ is time. Our algorithm uses only $\mathcal{O}\big(k\ln\ln T\big)$ switches, which helps when switching between policies is costly. As constructing the class of learning policies requires ordering the arms according to their expectations, we also bound the number of pulls required to do so. Finally, we run experiments to compare our algorithm against UCB on different problem instances.
Efficient Linear Bandits through Matrix Sketching
Sep 28, 2018

We prove that two popular linear contextual bandit algorithms, OFUL and Thompson Sampling, can be made efficient using Frequent Directions, a deterministic online sketching technique. More precisely, we show that a sketch of size $m$ allows a $\mathcal{O}(md)$ update time for both algorithms, as opposed to $\Omega(d^2)$ required by their non-sketched versions (where $d$ is the dimension of context vectors). When the selected contexts span a subspace of dimension at most $m$, we show that this computational speedup is accompanied by an improved regret of order $m\sqrt{T}$ for sketched OFUL and of order $m\sqrt{dT}$ for sketched Thompson Sampling (ignoring log factors in both cases). Vice versa, when the dimension of the span exceeds $m$, the regret bounds become of order $(1+\varepsilon_m)^{3/2}d\sqrt{T}$ for OFUL and of order $\big((1+\varepsilon_m)d\big)^{3/2}\sqrt{T}$ for Thompson Sampling, where $\varepsilon_m$ is bounded by the sum of the tail eigenvalues not covered by the sketch. Experiments on real-world datasets corroborate our theoretical results.