 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph Neural Network Approach to Nanosatellite Task Scheduling: Insights into Learning Mixed-Integer Models
Mar 24, 2023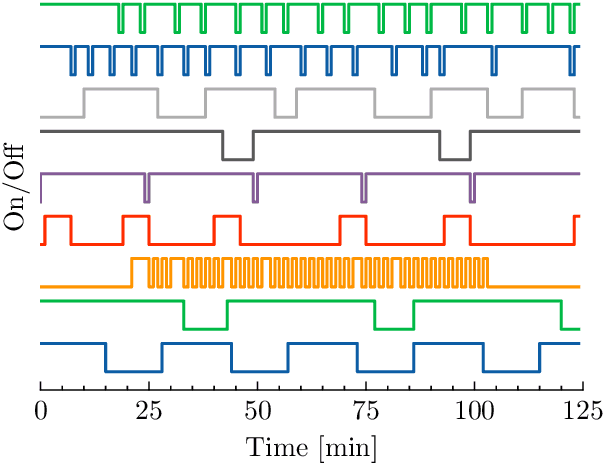

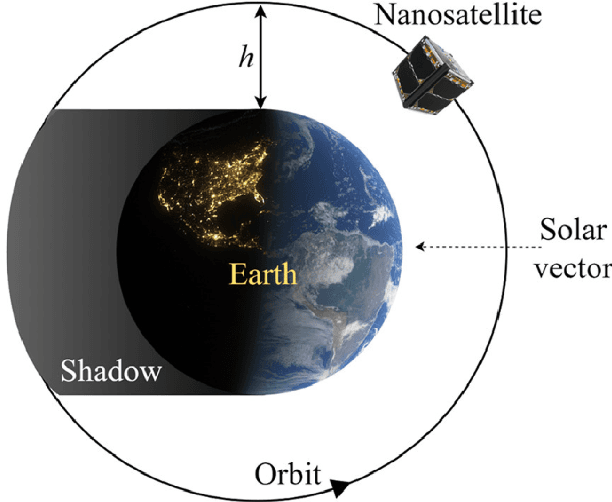
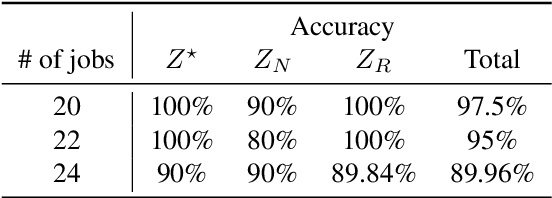
This study investigates how to schedule nanosatellite tasks more efficiently using Graph Neural Networks (GNN). In the Offline Nanosatellite Task Scheduling (ONTS) problem, the goal is to find the optimal schedule for tasks to be carried out in orbit while taking into account Quality-of-Service (QoS) considerations such as priority, minimum and maximum activation events, execution time-frames, periods, and execution windows, as well as constraints on the satellite's power resources and the complexity of energy harvesting and management. The ONTS problem has been approached using conventional mathematical formulations and precise methods, but their applicability to challenging cases of the problem is limited. This study examines the use of GNNs in this context, which has been effectively applied to many optimization problems, including traveling salesman problems, scheduling problems, and facility placement problems. Here, we fully represent MILP instances of the ONTS problem in bipartite graphs. We apply a feature aggregation and message-passing methodology allied to a ReLU activation function to learn using a classic deep learning model, obtaining an optimal set of parameters. Furthermore, we apply Explainable AI (XAI), another emerging field of research, to determine which features -- nodes, constraints -- had the most significant impact on learning performance, shedding light on the inner workings and decision process of such models. We also explored an early fixing approach by obtaining an accuracy above 80\% both in predicting the feasibility of a solution and the probability of a decision variable value being in the optimal solution. Our results point to GNNs as a potentially effective method for scheduling nanosatellite tasks and shed light on the advantages of explainable machine learning models for challenging combinatorial optimization problems.
Short-term forecasting of Amazon rainforest fires based on ensemble decomposition model
Jul 23, 2020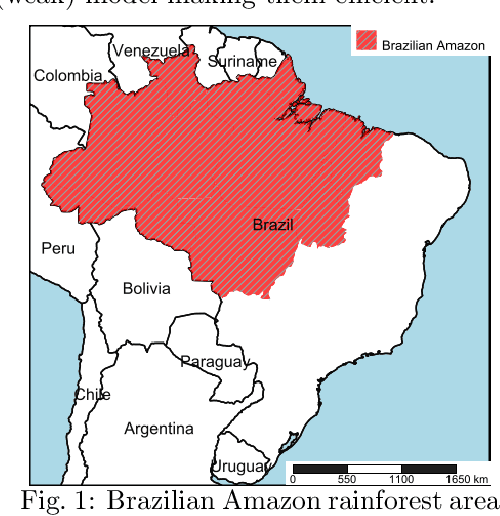
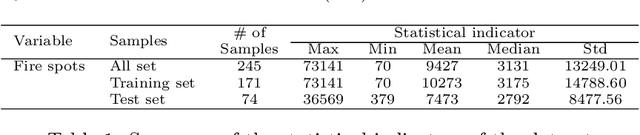
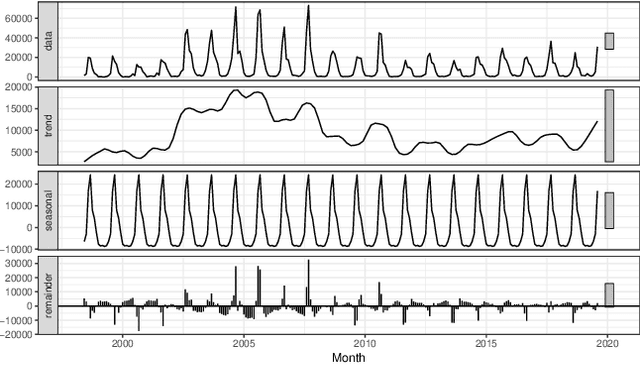
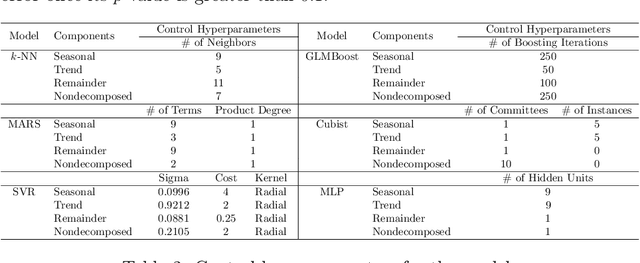
Accurate forecasting is important for decision-makers. Recently, the Amazon rainforest is reaching record levels of the number of fires, a situation that concerns both climate and public health problems. Obtaining the desired forecasting accuracy becomes difficult and challenging. In this paper were developed a novel heterogeneous decomposition-ensemble model by using Seasonal and Trend decomposition based on Loess in combination with algorithms for short-term load forecasting multi-month-ahead, to explore temporal patterns of Amazon rainforest fires in Brazil. The results demonstrate the proposed decomposition-ensemble models can provide more accurate forecasting evaluated by performance measures. Diebold-Mariano statistical test showed the proposed models are better than other compared models, but it is statistically equal to one of them.
Short-term forecasting COVID-19 cumulative confirmed cases: Perspectives for Brazil
Jul 21, 2020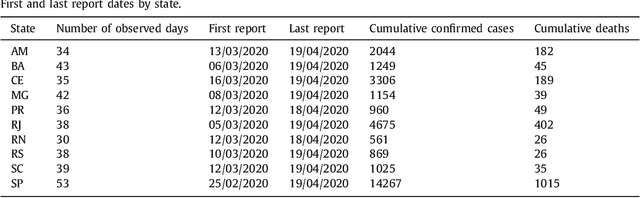
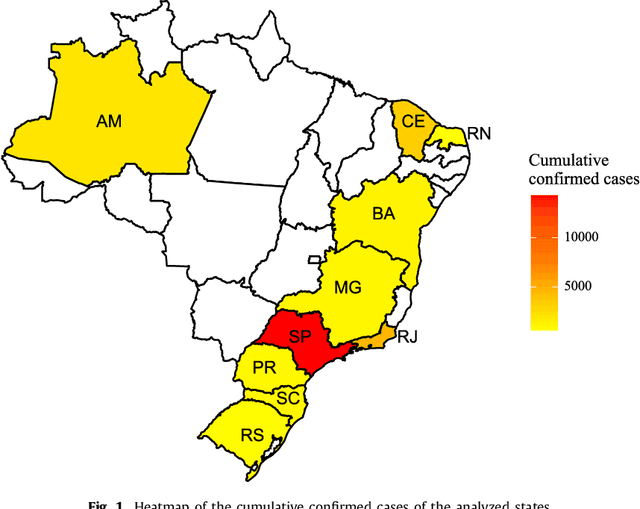
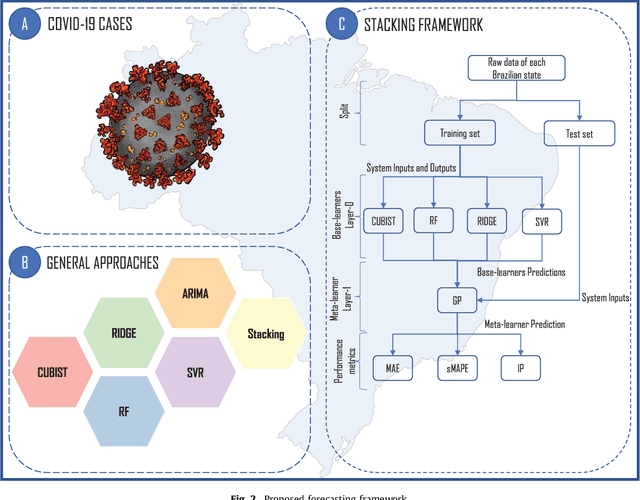
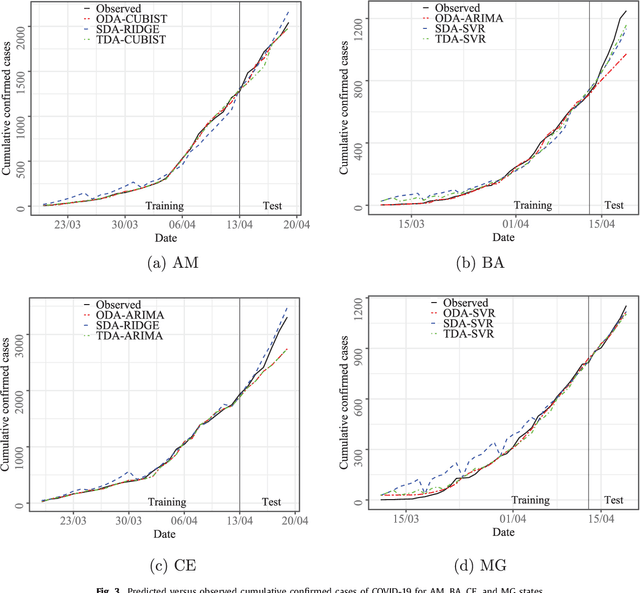
The new Coronavirus (COVID-19) is an emerging disease responsible for infecting millions of people since the first notification until nowadays. Developing efficient short-term forecasting models allow knowing the number of future cases. In this context, it is possible to develop strategic planning in the public health system to avoid deaths. In this paper, autoregressive integrated moving average (ARIMA), cubist (CUBIST), random forest (RF), ridge regression (RIDGE), support vector regression (SVR), and stacking-ensemble learning are evaluated in the task of time series forecasting with one, three, and six-days ahead the COVID-19 cumulative confirmed cases in ten Brazilian states with a high daily incidence. In the stacking learning approach, the cubist, RF, RIDGE, and SVR models are adopted as base-learners and Gaussian process (GP) as meta-learner. The models' effectiveness is evaluated based on the improvement index, mean absolute error, and symmetric mean absolute percentage error criteria. In most of the cases, the SVR and stacking ensemble learning reach a better performance regarding adopted criteria than compared models. In general, the developed models can generate accurate forecasting, achieving errors in a range of 0.87% - 3.51%, 1.02% - 5.63%, and 0.95% - 6.90% in one, three, and six-days-ahead, respectively. The ranking of models in all scenarios is SVR, stacking ensemble learning, ARIMA, CUBIST, RIDGE, and RF models. The use of evaluated models is recommended to forecasting and monitor the ongoing growth of COVID-19 cases, once these models can assist the managers in the decision-making support systems.
* 17 pages, 5 figures. Published paper. arXiv admin note: substantial text overlap with arXiv:2007.10981
Forecasting Brazilian and American COVID-19 cases based on artificial intelligence coupled with climatic exogenous variables
Jul 21, 2020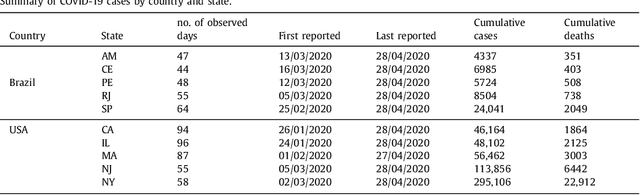
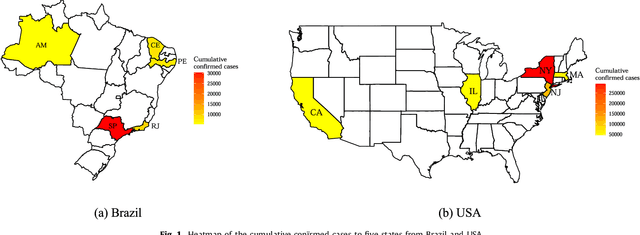
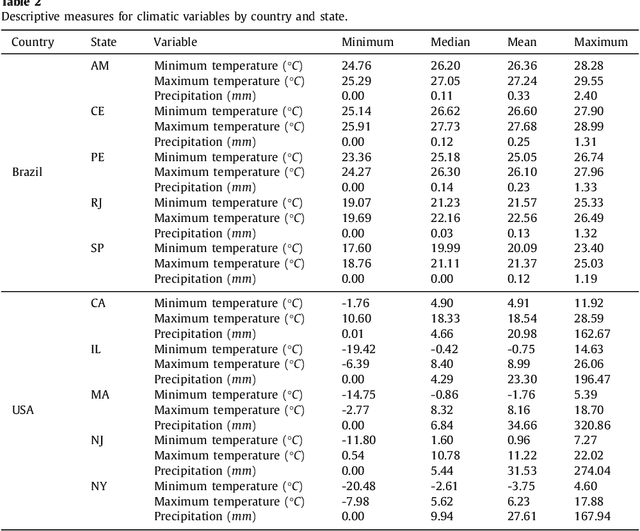
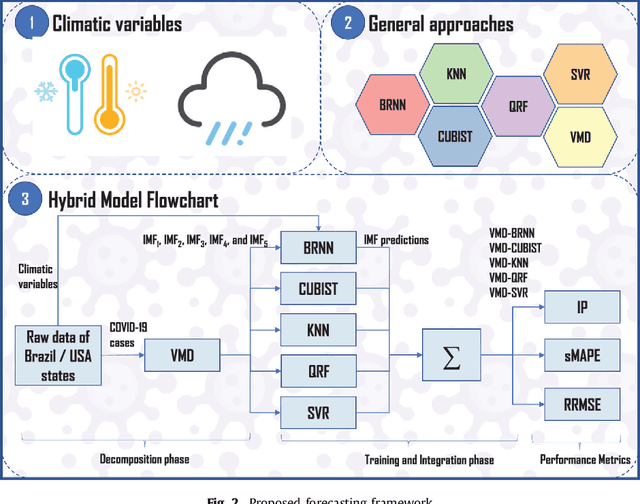
The novel coronavirus disease (COVID-19) is a public health problem once according to the World Health Organization up to June 10th, 2020, more than 7.1 million people were infected, and more than 400 thousand have died worldwide. In the current scenario, the Brazil and the United States of America present a high daily incidence of new cases and deaths. It is important to forecast the number of new cases in a time window of one week, once this can help the public health system developing strategic planning to deals with the COVID-19. In this paper, Bayesian regression neural network, cubist regression, k-nearest neighbors, quantile random forest, and support vector regression, are used stand-alone, and coupled with the recent pre-processing variational mode decomposition (VMD) employed to decompose the time series into several intrinsic mode functions. All Artificial Intelligence techniques are evaluated in the task of time-series forecasting with one, three, and six-days-ahead the cumulative COVID-19 cases in five Brazilian and American states up to April 28th, 2020. Previous cumulative COVID-19 cases and exogenous variables as daily temperature and precipitation were employed as inputs for all forecasting models. The hybridization of VMD outperformed single forecasting models regarding the accuracy, specifically when the horizon is six-days-ahead, achieving better accuracy in 70% of the cases. Regarding the exogenous variables, the importance ranking as predictor variables is past cases, temperature, and precipitation. Due to the efficiency of evaluated models to forecasting cumulative COVID-19 cases up to six-days-ahead, the adopted models can be recommended as a promising models for forecasting and be used to assist in the development of public policies to mitigate the effects of COVID-19 outbreak.
* 24 pages, 6 figures. Published paper
Multi-Stage Transfer Learning with an Application to Selection Process
Jun 01, 2020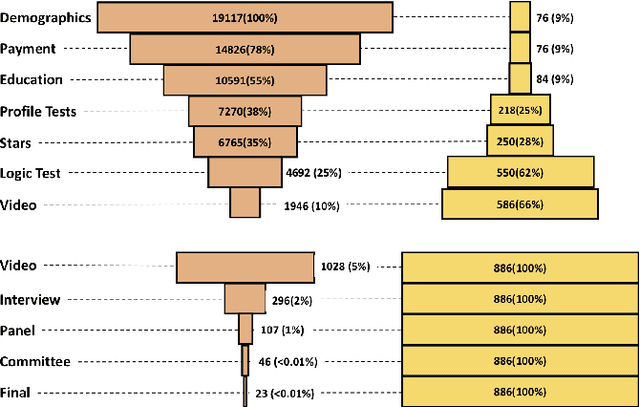

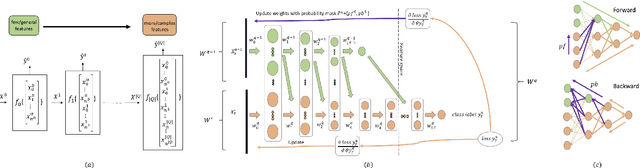
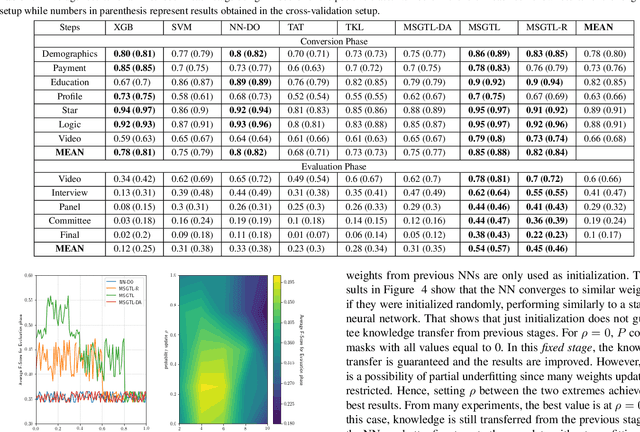
In multi-stage processes, decisions happen in an ordered sequence of stages. Many of them have the structure of dual funnel problem: as the sample size decreases from one stage to the other, the information increases. A related example is a selection process, where applicants apply for a position, prize, or grant. In each stage, more applicants are evaluated and filtered out, and from the remaining ones, more information is collected. In the last stage, decision-makers use all available information to make their final decision. To train a classifier for each stage becomes impracticable as they can underfit due to the low dimensionality in early stages or overfit due to the small sample size in the latter stages. In this work, we proposed a \textit{Multi-StaGe Transfer Learning} (MSGTL) approach that uses knowledge from simple classifiers trained in early stages to improve the performance of classifiers in the latter stages. By transferring weights from simpler neural networks trained in larger datasets, we able to fine-tune more complex neural networks in the latter stages without overfitting due to the small sample size. We show that it is possible to control the trade-off between conserving knowledge and fine-tuning using a simple probabilistic map. Experiments using real-world data demonstrate the efficacy of our approach as it outperforms other state-of-the-art methods for transfer learning and regularization.
Unified Multi-Domain Learning and Data Imputation using Adversarial Autoencoder
Mar 15, 2020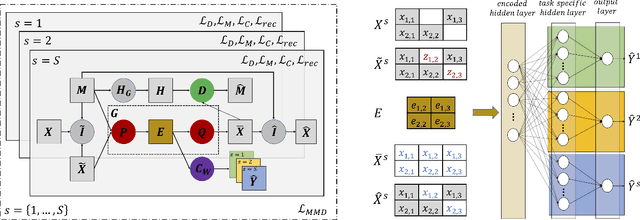
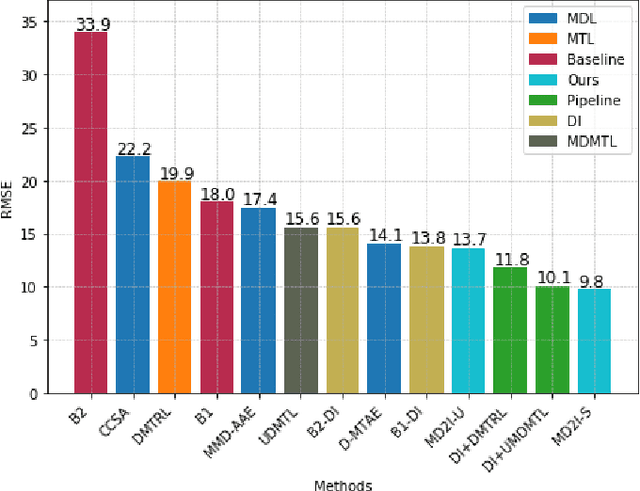

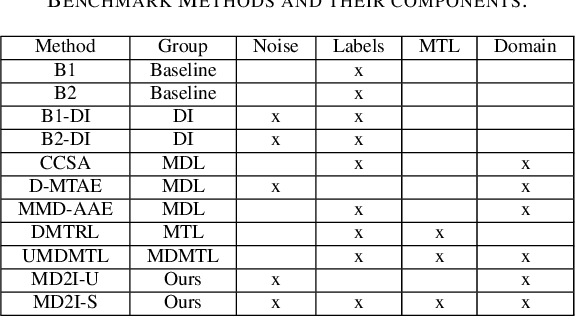
We present a novel framework that can combine multi-domain learning (MDL), data imputation (DI) and multi-task learning (MTL) to improve performance for classification and regression tasks in different domains. The core of our method is an adversarial autoencoder that can: (1) learn to produce domain-invariant embeddings to reduce the difference between domains; (2) learn the data distribution for each domain and correctly perform data imputation on missing data. For MDL, we use the Maximum Mean Discrepancy (MMD) measure to align the domain distributions. For DI, we use an adversarial approach where a generator fill in information for missing data and a discriminator tries to distinguish between real and imputed values. Finally, using the universal feature representation in the embeddings, we train a classifier using MTL that given input from any domain, can predict labels for all domains. We demonstrate the superior performance of our approach compared to other state-of-art methods in three distinct settings, DG-DI in image recognition with unstructured data, MTL-DI in grade estimation with structured data and MDMTL-DI in a selection process using mixed data.
Adversarial Encoder-Multi-Task-Decoder for Multi-Stage Processes
Mar 15, 2020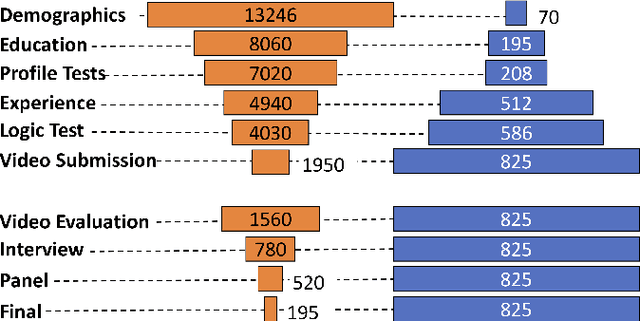
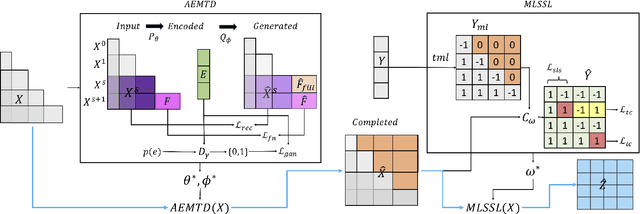
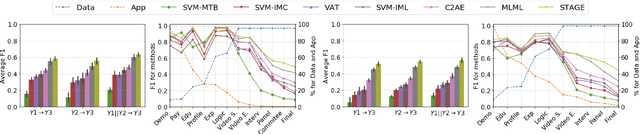

In multi-stage processes, decisions occur in an ordered sequence of stages. Early stages usually have more observations with general information (easier/cheaper to collect), while later stages have fewer observations but more specific data. This situation can be represented by a dual funnel structure, in which the sample size decreases from one stage to the other while the information increases. Training classifiers in this scenario is challenging since information in the early stages may not contain distinct patterns to learn (underfitting). In contrast, the small sample size in later stages can cause overfitting. We address both cases by introducing a framework that combines adversarial autoencoders (AAE), multi-task learning (MTL), and multi-label semi-supervised learning (MLSSL). We improve the decoder of the AAE with an MTL component so it can jointly reconstruct the original input and use feature nets to predict the features for the next stages. We also introduce a sequence constraint in the output of an MLSSL classifier to guarantee the sequential pattern in the predictions. Using real-world data from different domains (selection process, medical diagnosis), we show that our approach outperforms other state-of-the-art methods.