 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Transfer Learning with an Application to Selection Process
Paper and Code
Jun 01, 2020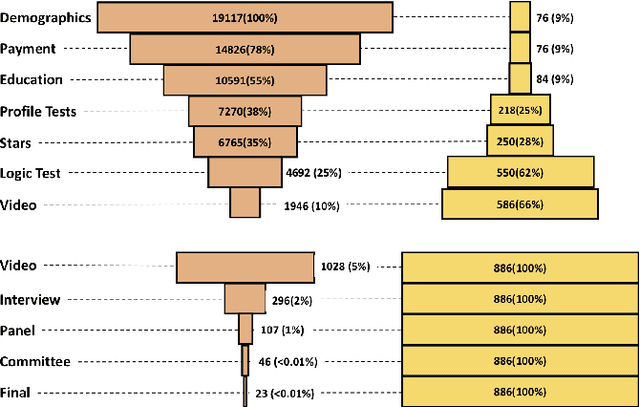

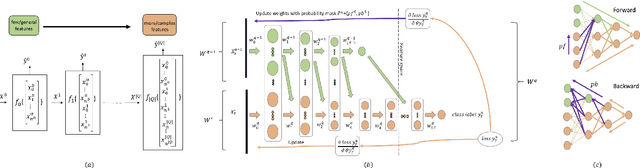
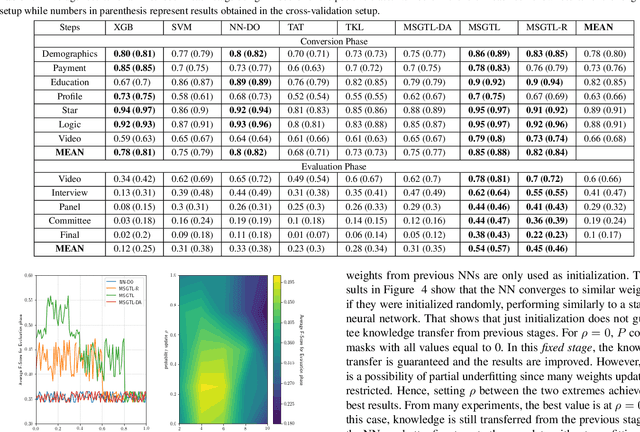
In multi-stage processes, decisions happen in an ordered sequence of stages. Many of them have the structure of dual funnel problem: as the sample size decreases from one stage to the other, the information increases. A related example is a selection process, where applicants apply for a position, prize, or grant. In each stage, more applicants are evaluated and filtered out, and from the remaining ones, more information is collected. In the last stage, decision-makers use all available information to make their final decision. To train a classifier for each stage becomes impracticable as they can underfit due to the low dimensionality in early stages or overfit due to the small sample size in the latter stages. In this work, we proposed a \textit{Multi-StaGe Transfer Learning} (MSGTL) approach that uses knowledge from simple classifiers trained in early stages to improve the performance of classifiers in the latter stages. By transferring weights from simpler neural networks trained in larger datasets, we able to fine-tune more complex neural networks in the latter stages without overfitting due to the small sample size. We show that it is possible to control the trade-off between conserving knowledge and fine-tuning using a simple probabilistic map. Experiments using real-world data demonstrate the efficacy of our approach as it outperforms other state-of-the-art methods for transfer learning and regularization.