 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Transfer Learning with an Application to Selection Process
Jun 01, 2020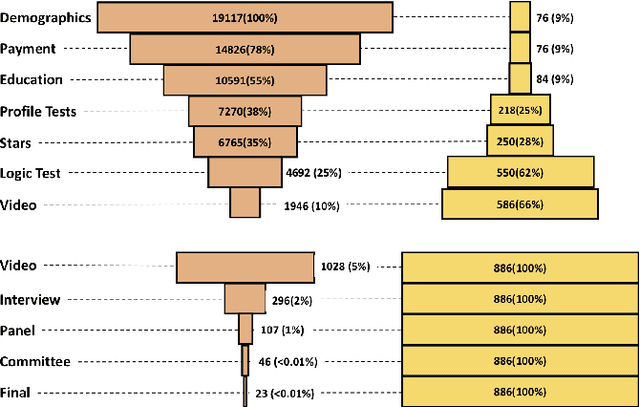

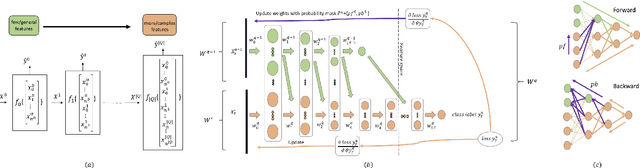
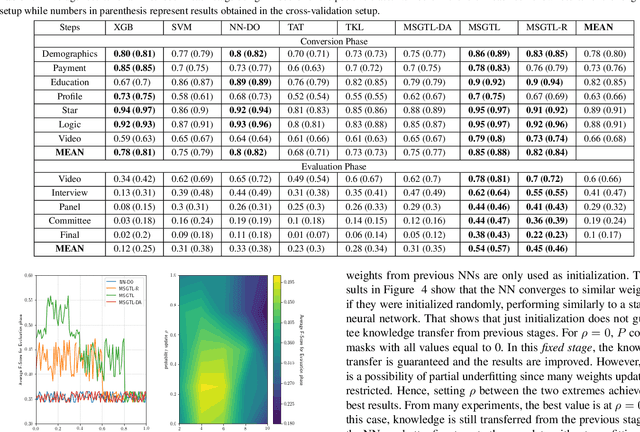
In multi-stage processes, decisions happen in an ordered sequence of stages. Many of them have the structure of dual funnel problem: as the sample size decreases from one stage to the other, the information increases. A related example is a selection process, where applicants apply for a position, prize, or grant. In each stage, more applicants are evaluated and filtered out, and from the remaining ones, more information is collected. In the last stage, decision-makers use all available information to make their final decision. To train a classifier for each stage becomes impracticable as they can underfit due to the low dimensionality in early stages or overfit due to the small sample size in the latter stages. In this work, we proposed a \textit{Multi-StaGe Transfer Learning} (MSGTL) approach that uses knowledge from simple classifiers trained in early stages to improve the performance of classifiers in the latter stages. By transferring weights from simpler neural networks trained in larger datasets, we able to fine-tune more complex neural networks in the latter stages without overfitting due to the small sample size. We show that it is possible to control the trade-off between conserving knowledge and fine-tuning using a simple probabilistic map. Experiments using real-world data demonstrate the efficacy of our approach as it outperforms other state-of-the-art methods for transfer learning and regularization.
Unified Multi-Domain Learning and Data Imputation using Adversarial Autoencoder
Mar 15, 2020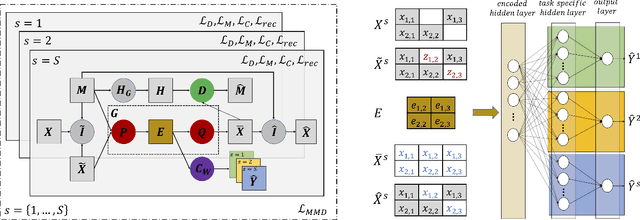
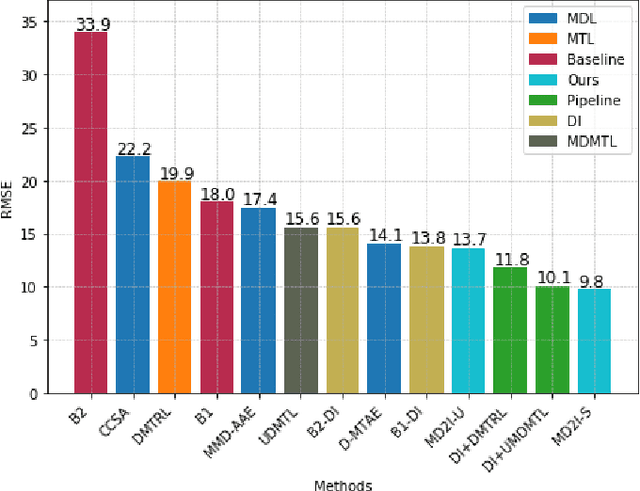

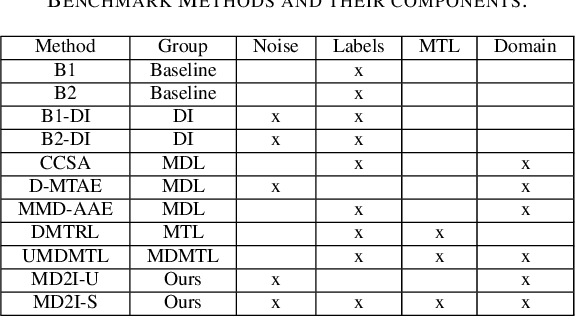
We present a novel framework that can combine multi-domain learning (MDL), data imputation (DI) and multi-task learning (MTL) to improve performance for classification and regression tasks in different domains. The core of our method is an adversarial autoencoder that can: (1) learn to produce domain-invariant embeddings to reduce the difference between domains; (2) learn the data distribution for each domain and correctly perform data imputation on missing data. For MDL, we use the Maximum Mean Discrepancy (MMD) measure to align the domain distributions. For DI, we use an adversarial approach where a generator fill in information for missing data and a discriminator tries to distinguish between real and imputed values. Finally, using the universal feature representation in the embeddings, we train a classifier using MTL that given input from any domain, can predict labels for all domains. We demonstrate the superior performance of our approach compared to other state-of-art methods in three distinct settings, DG-DI in image recognition with unstructured data, MTL-DI in grade estimation with structured data and MDMTL-DI in a selection process using mixed data.
Adversarial Encoder-Multi-Task-Decoder for Multi-Stage Processes
Mar 15, 2020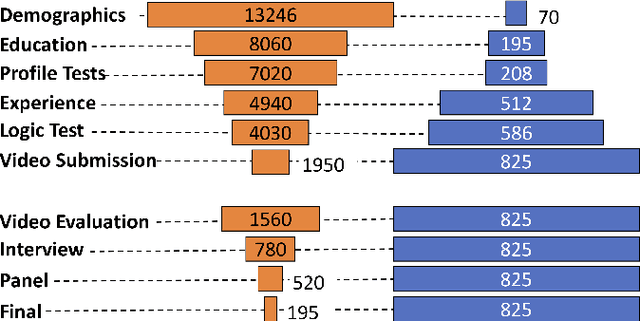
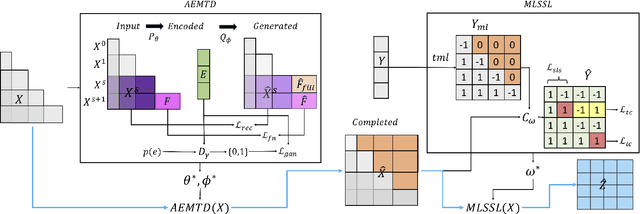
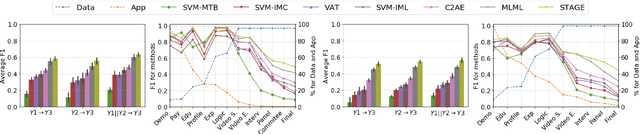

In multi-stage processes, decisions occur in an ordered sequence of stages. Early stages usually have more observations with general information (easier/cheaper to collect), while later stages have fewer observations but more specific data. This situation can be represented by a dual funnel structure, in which the sample size decreases from one stage to the other while the information increases. Training classifiers in this scenario is challenging since information in the early stages may not contain distinct patterns to learn (underfitting). In contrast, the small sample size in later stages can cause overfitting. We address both cases by introducing a framework that combines adversarial autoencoders (AAE), multi-task learning (MTL), and multi-label semi-supervised learning (MLSSL). We improve the decoder of the AAE with an MTL component so it can jointly reconstruct the original input and use feature nets to predict the features for the next stages. We also introduce a sequence constraint in the output of an MLSSL classifier to guarantee the sequential pattern in the predictions. Using real-world data from different domains (selection process, medical diagnosis), we show that our approach outperforms other state-of-the-art methods.