 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWater and Electricity Consumption Forecasting at an Educational Institution using Machine Learning models with Metaheuristic Optimization
Oct 25, 2024

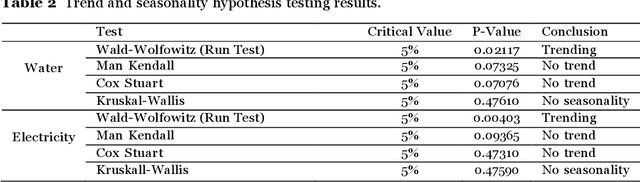
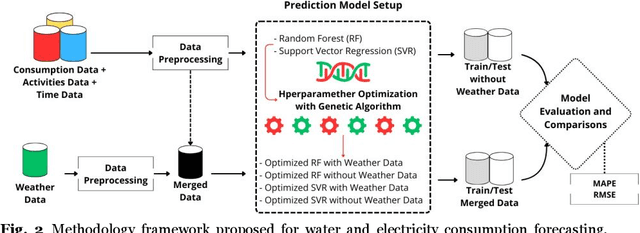
Educational institutions are essential for economic and social development. Budget cuts in Brazil in recent years have made it difficult to carry out their activities and projects. In the case of expenses with water and electricity, unexpected situations can occur, such as leaks and equipment failures, which make their management challenging. This study proposes a comparison between two machine learning models, Random Forest (RF) and Support Vector Regression (SVR), for water and electricity consumption forecasting at the Federal Institute of Paran\'a-Campus Palmas, with a 12-month forecasting horizon, as well as evaluating the influence of the application of climatic variables as exogenous features. The data were collected over the past five years, combining details pertaining to invoices with exogenous and endogenous variables. The two models had their hyperpa-rameters optimized using the Genetic Algorithm (GA) to select the individuals with the best fitness to perform the forecasting with and without climatic variables. The absolute percentage errors and root mean squared error were used as performance measures to evaluate the forecasting accuracy. The results suggest that in forecasting water and electricity consumption over a 12-step horizon, the Random Forest model exhibited the most superior performance. The integration of climatic variables often led to diminished forecasting accuracy, resulting in higher errors. Both models still had certain difficulties in predicting water consumption, indicating that new studies with different models or variables are welcome.
Short-term forecasting of Amazon rainforest fires based on ensemble decomposition model
Jul 23, 2020
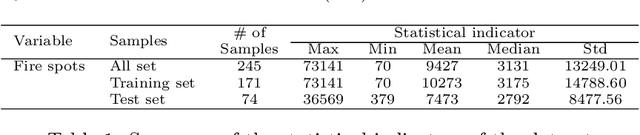
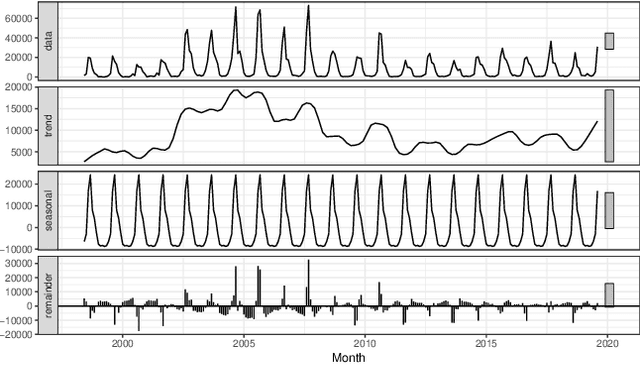
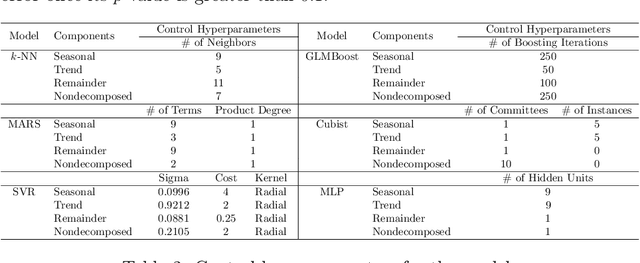
Accurate forecasting is important for decision-makers. Recently, the Amazon rainforest is reaching record levels of the number of fires, a situation that concerns both climate and public health problems. Obtaining the desired forecasting accuracy becomes difficult and challenging. In this paper were developed a novel heterogeneous decomposition-ensemble model by using Seasonal and Trend decomposition based on Loess in combination with algorithms for short-term load forecasting multi-month-ahead, to explore temporal patterns of Amazon rainforest fires in Brazil. The results demonstrate the proposed decomposition-ensemble models can provide more accurate forecasting evaluated by performance measures. Diebold-Mariano statistical test showed the proposed models are better than other compared models, but it is statistically equal to one of them.
Short-term forecasting COVID-19 cumulative confirmed cases: Perspectives for Brazil
Jul 21, 2020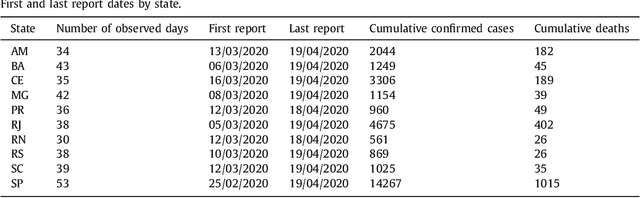
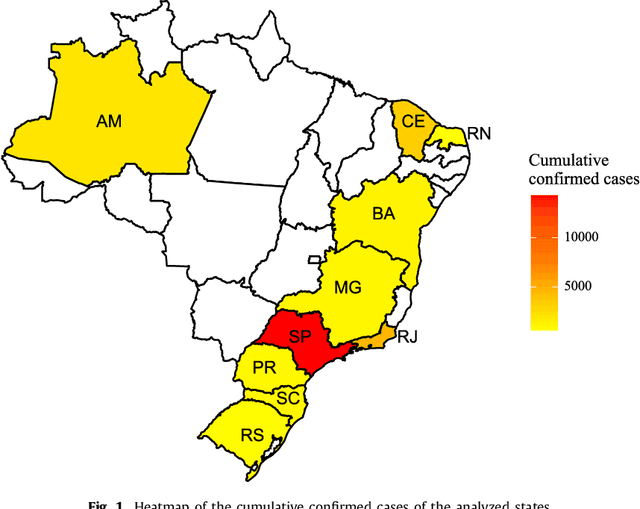
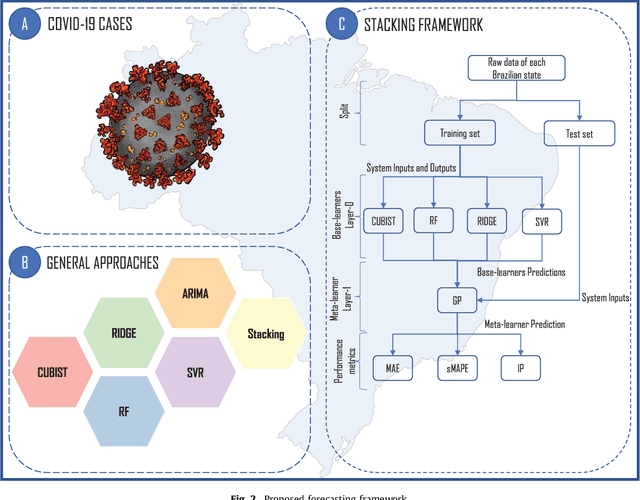
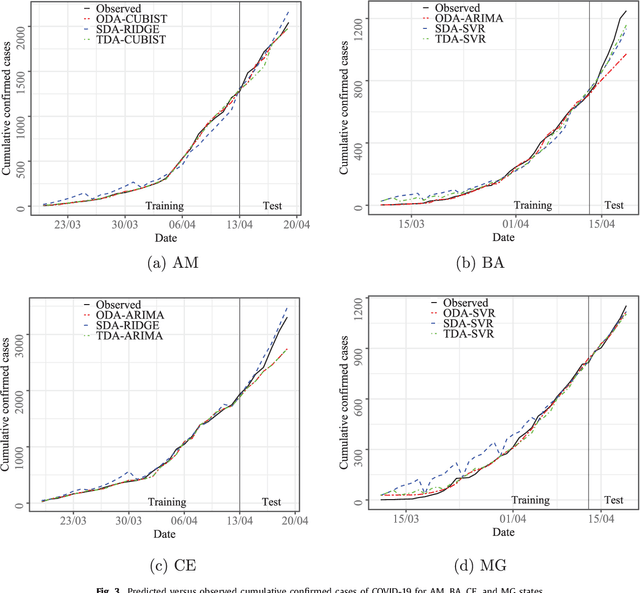
The new Coronavirus (COVID-19) is an emerging disease responsible for infecting millions of people since the first notification until nowadays. Developing efficient short-term forecasting models allow knowing the number of future cases. In this context, it is possible to develop strategic planning in the public health system to avoid deaths. In this paper, autoregressive integrated moving average (ARIMA), cubist (CUBIST), random forest (RF), ridge regression (RIDGE), support vector regression (SVR), and stacking-ensemble learning are evaluated in the task of time series forecasting with one, three, and six-days ahead the COVID-19 cumulative confirmed cases in ten Brazilian states with a high daily incidence. In the stacking learning approach, the cubist, RF, RIDGE, and SVR models are adopted as base-learners and Gaussian process (GP) as meta-learner. The models' effectiveness is evaluated based on the improvement index, mean absolute error, and symmetric mean absolute percentage error criteria. In most of the cases, the SVR and stacking ensemble learning reach a better performance regarding adopted criteria than compared models. In general, the developed models can generate accurate forecasting, achieving errors in a range of 0.87% - 3.51%, 1.02% - 5.63%, and 0.95% - 6.90% in one, three, and six-days-ahead, respectively. The ranking of models in all scenarios is SVR, stacking ensemble learning, ARIMA, CUBIST, RIDGE, and RF models. The use of evaluated models is recommended to forecasting and monitor the ongoing growth of COVID-19 cases, once these models can assist the managers in the decision-making support systems.
* 17 pages, 5 figures. Published paper. arXiv admin note: substantial text overlap with arXiv:2007.10981
Forecasting Brazilian and American COVID-19 cases based on artificial intelligence coupled with climatic exogenous variables
Jul 21, 2020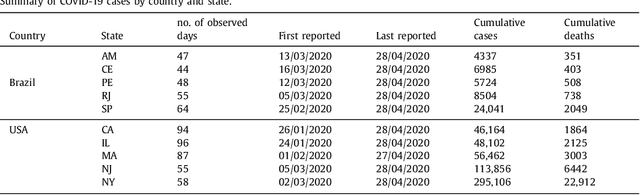
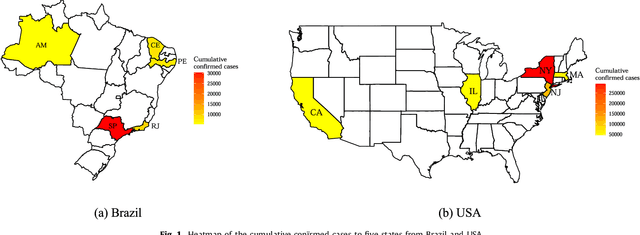
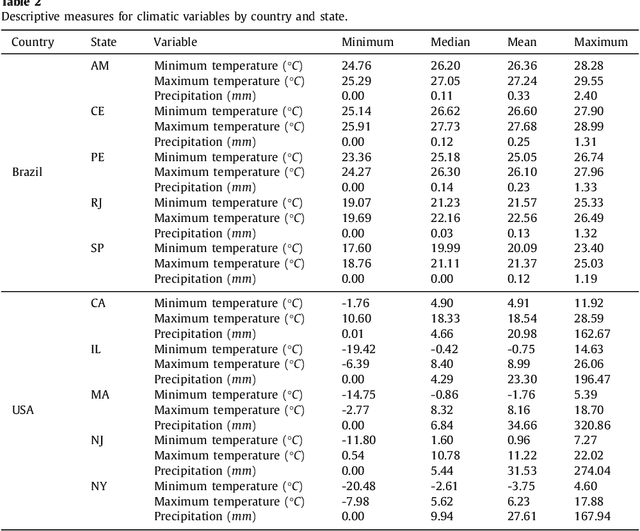
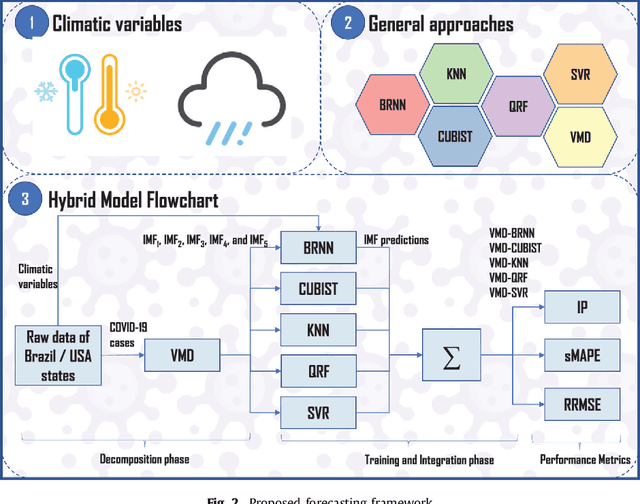
The novel coronavirus disease (COVID-19) is a public health problem once according to the World Health Organization up to June 10th, 2020, more than 7.1 million people were infected, and more than 400 thousand have died worldwide. In the current scenario, the Brazil and the United States of America present a high daily incidence of new cases and deaths. It is important to forecast the number of new cases in a time window of one week, once this can help the public health system developing strategic planning to deals with the COVID-19. In this paper, Bayesian regression neural network, cubist regression, k-nearest neighbors, quantile random forest, and support vector regression, are used stand-alone, and coupled with the recent pre-processing variational mode decomposition (VMD) employed to decompose the time series into several intrinsic mode functions. All Artificial Intelligence techniques are evaluated in the task of time-series forecasting with one, three, and six-days-ahead the cumulative COVID-19 cases in five Brazilian and American states up to April 28th, 2020. Previous cumulative COVID-19 cases and exogenous variables as daily temperature and precipitation were employed as inputs for all forecasting models. The hybridization of VMD outperformed single forecasting models regarding the accuracy, specifically when the horizon is six-days-ahead, achieving better accuracy in 70% of the cases. Regarding the exogenous variables, the importance ranking as predictor variables is past cases, temperature, and precipitation. Due to the efficiency of evaluated models to forecasting cumulative COVID-19 cases up to six-days-ahead, the adopted models can be recommended as a promising models for forecasting and be used to assist in the development of public policies to mitigate the effects of COVID-19 outbreak.
* 24 pages, 6 figures. Published paper