 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Prediction for Semantic Segmentation using Post-Hoc Confidence Estimation and Its Performance under Distribution Shift
Feb 16, 2024



Semantic segmentation plays a crucial role in various computer vision applications, yet its efficacy is often hindered by the lack of high-quality labeled data. To address this challenge, a common strategy is to leverage models trained on data from different populations, such as publicly available datasets. This approach, however, leads to the distribution shift problem, presenting a reduced performance on the population of interest. In scenarios where model errors can have significant consequences, selective prediction methods offer a means to mitigate risks and reduce reliance on expert supervision. This paper investigates selective prediction for semantic segmentation in low-resource settings, thus focusing on post-hoc confidence estimators applied to pre-trained models operating under distribution shift. We propose a novel image-level confidence measure tailored for semantic segmentation and demonstrate its effectiveness through experiments on three medical imaging tasks. Our findings show that post-hoc confidence estimators offer a cost-effective approach to reducing the impacts of distribution shift.
Deep-learning-based Early Fixing for Gas-lifted Oil Production Optimization: Supervised and Weakly-supervised Approaches
Sep 01, 2023Maximizing oil production from gas-lifted oil wells entails solving Mixed-Integer Linear Programs (MILPs). As the parameters of the wells, such as the basic-sediment-to-water ratio and the gas-oil ratio, are updated, the problems must be repeatedly solved. Instead of relying on costly exact methods or the accuracy of general approximate methods, in this paper, we propose a tailor-made heuristic solution based on deep learning models trained to provide values to all integer variables given varying well parameters, early-fixing the integer variables and, thus, reducing the original problem to a linear program (LP). We propose two approaches for developing the learning-based heuristic: a supervised learning approach, which requires the optimal integer values for several instances of the original problem in the training set, and a weakly-supervised learning approach, which requires only solutions for the early-fixed linear problems with random assignments for the integer variables. Our results show a runtime reduction of 71.11% Furthermore, the weakly-supervised learning model provided significant values for early fixing, despite never seeing the optimal values during training.
Does pre-training on brain-related tasks results in better deep-learning-based brain age biomarkers?
Jul 11, 2023Brain age prediction using neuroimaging data has shown great potential as an indicator of overall brain health and successful aging, as well as a disease biomarker. Deep learning models have been established as reliable and efficient brain age estimators, being trained to predict the chronological age of healthy subjects. In this paper, we investigate the impact of a pre-training step on deep learning models for brain age prediction. More precisely, instead of the common approach of pre-training on natural imaging classification, we propose pre-training the models on brain-related tasks, which led to state-of-the-art results in our experiments on ADNI data. Furthermore, we validate the resulting brain age biomarker on images of patients with mild cognitive impairment and Alzheimer's disease. Interestingly, our results indicate that better-performing deep learning models in terms of brain age prediction on healthy patients do not result in more reliable biomarkers.
A Graph Neural Network Approach to Nanosatellite Task Scheduling: Insights into Learning Mixed-Integer Models
Mar 24, 2023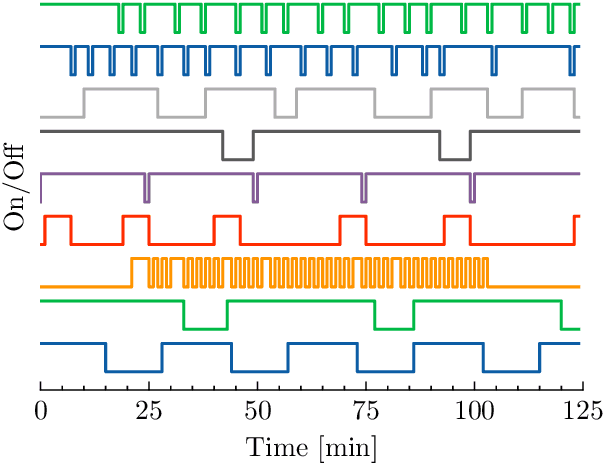

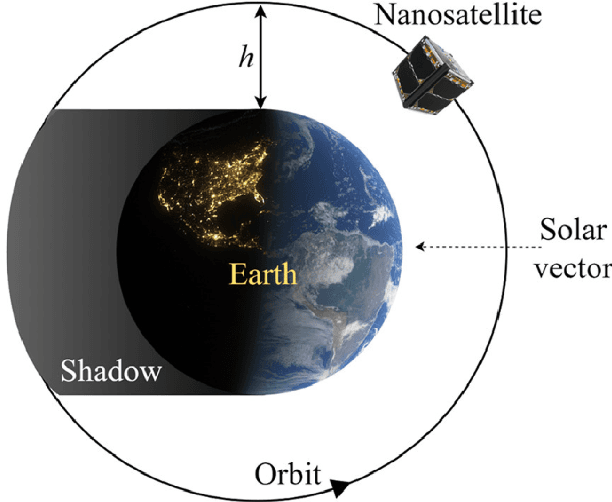
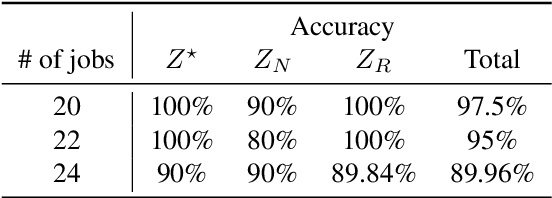
This study investigates how to schedule nanosatellite tasks more efficiently using Graph Neural Networks (GNN). In the Offline Nanosatellite Task Scheduling (ONTS) problem, the goal is to find the optimal schedule for tasks to be carried out in orbit while taking into account Quality-of-Service (QoS) considerations such as priority, minimum and maximum activation events, execution time-frames, periods, and execution windows, as well as constraints on the satellite's power resources and the complexity of energy harvesting and management. The ONTS problem has been approached using conventional mathematical formulations and precise methods, but their applicability to challenging cases of the problem is limited. This study examines the use of GNNs in this context, which has been effectively applied to many optimization problems, including traveling salesman problems, scheduling problems, and facility placement problems. Here, we fully represent MILP instances of the ONTS problem in bipartite graphs. We apply a feature aggregation and message-passing methodology allied to a ReLU activation function to learn using a classic deep learning model, obtaining an optimal set of parameters. Furthermore, we apply Explainable AI (XAI), another emerging field of research, to determine which features -- nodes, constraints -- had the most significant impact on learning performance, shedding light on the inner workings and decision process of such models. We also explored an early fixing approach by obtaining an accuracy above 80\% both in predicting the feasibility of a solution and the probability of a decision variable value being in the optimal solution. Our results point to GNNs as a potentially effective method for scheduling nanosatellite tasks and shed light on the advantages of explainable machine learning models for challenging combinatorial optimization problems.
Towards fully automated deep-learning-based brain tumor segmentation: is brain extraction still necessary?
Dec 14, 2022
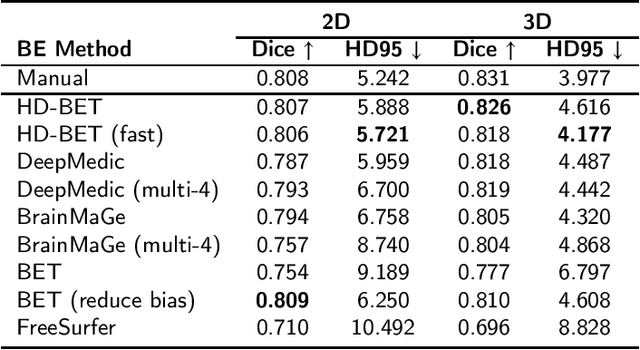

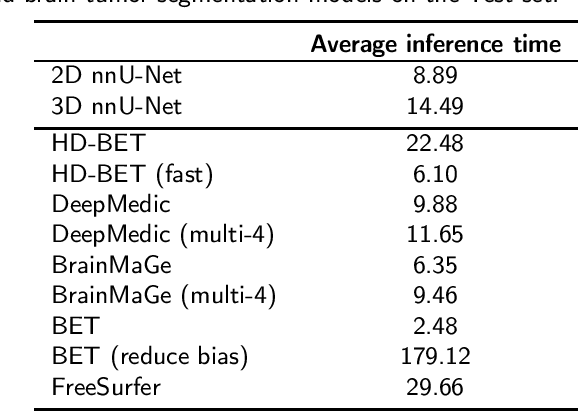
State-of-the-art brain tumor segmentation is based on deep learning models applied to multi-modal MRIs. Currently, these models are trained on images after a preprocessing stage that involves registration, interpolation, brain extraction (BE, also known as skull-stripping) and manual correction by an expert. However, for clinical practice, this last step is tedious and time-consuming and, therefore, not always feasible, resulting in skull-stripping faults that can negatively impact the tumor segmentation quality. Still, the extent of this impact has never been measured for any of the many different BE methods available. In this work, we propose an automatic brain tumor segmentation pipeline and evaluate its performance with multiple BE methods. Our experiments show that the choice of a BE method can compromise up to 15.7% of the tumor segmentation performance. Moreover, we propose training and testing tumor segmentation models on non-skull-stripped images, effectively discarding the BE step from the pipeline. Our results show that this approach leads to a competitive performance at a fraction of the time. We conclude that, in contrast to the current paradigm, training tumor segmentation models on non-skull-stripped images can be the best option when high performance in clinical practice is desired.