 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Benefits of Diversity: Combining Comparisons and Ratings for Efficient Scoring
Feb 08, 2026Should humans be asked to evaluate entities individually or comparatively? This question has been the subject of long debates. In this work, we show that, interestingly, combining both forms of preference elicitation can outperform the focus on a single kind. More specifically, we introduce SCoRa (Scoring from Comparisons and Ratings), a unified probabilistic model that allows to learn from both signals. We prove that the MAP estimator of SCoRa is well-behaved. It verifies monotonicity and robustness guarantees. We then empirically show that SCoRa recovers accurate scores, even under model mismatch. Most interestingly, we identify a realistic setting where combining comparisons and ratings outperforms using either one alone, and when the accurate ordering of top entities is critical. Given the de facto availability of signals of multiple forms, SCoRa additionally offers a versatile foundation for preference learning.
Generalizing while preserving monotonicity in comparison-based preference learning models
Jun 10, 2025If you tell a learning model that you prefer an alternative $a$ over another alternative $b$, then you probably expect the model to be monotone, that is, the valuation of $a$ increases, and that of $b$ decreases. Yet, perhaps surprisingly, many widely deployed comparison-based preference learning models, including large language models, fail to have this guarantee. Until now, the only comparison-based preference learning algorithms that were proved to be monotone are the Generalized Bradley-Terry models. Yet, these models are unable to generalize to uncompared data. In this paper, we advance the understanding of the set of models with generalization ability that are monotone. Namely, we propose a new class of Linear Generalized Bradley-Terry models with Diffusion Priors, and identify sufficient conditions on alternatives' embeddings that guarantee monotonicity. Our experiments show that this monotonicity is far from being a general guarantee, and that our new class of generalizing models improves accuracy, especially when the dataset is limited.
On Goodhart's law, with an application to value alignment
Oct 12, 2024``When a measure becomes a target, it ceases to be a good measure'', this adage is known as {\it Goodhart's law}. In this paper, we investigate formally this law and prove that it critically depends on the tail distribution of the discrepancy between the true goal and the measure that is optimized. Discrepancies with long-tail distributions favor a Goodhart's law, that is, the optimization of the measure can have a counter-productive effect on the goal. We provide a formal setting to assess Goodhart's law by studying the asymptotic behavior of the correlation between the goal and the measure, as the measure is optimized. Moreover, we introduce a distinction between a {\it weak} Goodhart's law, when over-optimizing the metric is useless for the true goal, and a {\it strong} Goodhart's law, when over-optimizing the metric is harmful for the true goal. A distinction which we prove to depend on the tail distribution. We stress the implications of this result to large-scale decision making and policies that are (and have to be) based on metrics, and propose numerous research directions to better assess the safety of such policies in general, and to the particularly concerning case where these policies are automated with algorithms.
The poison of dimensionality
Sep 25, 2024This paper advances the understanding of how the size of a machine learning model affects its vulnerability to poisoning, despite state-of-the-art defenses. Given isotropic random honest feature vectors and the geometric median (or clipped mean) as the robust gradient aggregator rule, we essentially prove that, perhaps surprisingly, linear and logistic regressions with $D \geq 169 H^2/P^2$ parameters are subject to arbitrary model manipulation by poisoners, where $H$ and $P$ are the numbers of honestly labeled and poisoned data points used for training. Our experiments go on exposing a fundamental tradeoff between augmenting model expressivity and increasing the poisoners' attack surface, on both synthetic data, and on MNIST & FashionMNIST data for linear classifiers with random features. We also discuss potential implications for source-based learning and neural nets.
SoK: On the Impossible Security of Very Large Foundation Models
Sep 30, 2022Large machine learning models, or so-called foundation models, aim to serve as base-models for application-oriented machine learning. Although these models showcase impressive performance, they have been empirically found to pose serious security and privacy issues. We may however wonder if this is a limitation of the current models, or if these issues stem from a fundamental intrinsic impossibility of the foundation model learning problem itself. This paper aims to systematize our knowledge supporting the latter. More precisely, we identify several key features of today's foundation model learning problem which, given the current understanding in adversarial machine learning, suggest incompatibility of high accuracy with both security and privacy. We begin by observing that high accuracy seems to require (1) very high-dimensional models and (2) huge amounts of data that can only be procured through user-generated datasets. Moreover, such data is fundamentally heterogeneous, as users generally have very specific (easily identifiable) data-generating habits. More importantly, users' data is filled with highly sensitive information, and maybe heavily polluted by fake users. We then survey lower bounds on accuracy in privacy-preserving and Byzantine-resilient heterogeneous learning that, we argue, constitute a compelling case against the possibility of designing a secure and privacy-preserving high-accuracy foundation model. We further stress that our analysis also applies to other high-stake machine learning applications, including content recommendation. We conclude by calling for measures to prioritize security and privacy, and to slow down the race for ever larger models.
An Equivalence Between Data Poisoning and Byzantine Gradient Attacks
Feb 17, 2022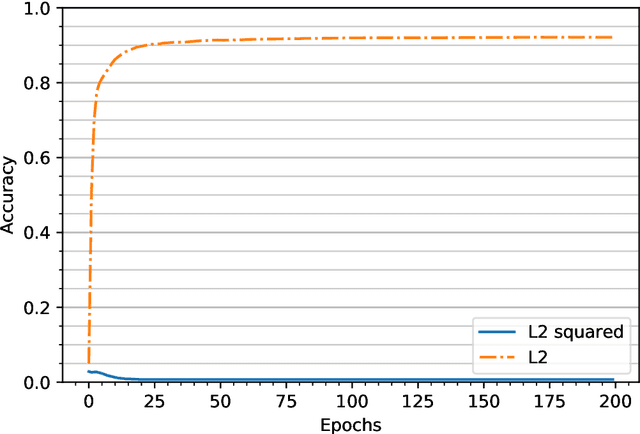

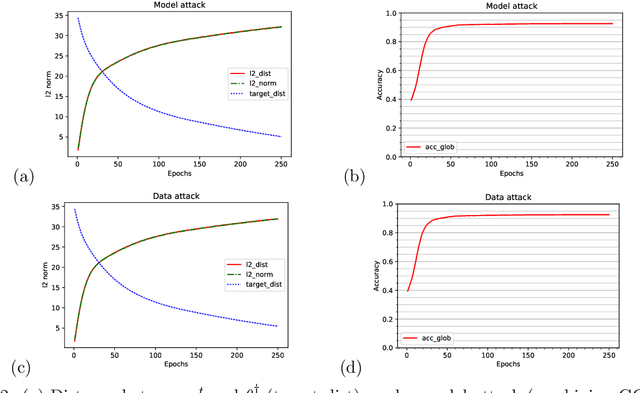
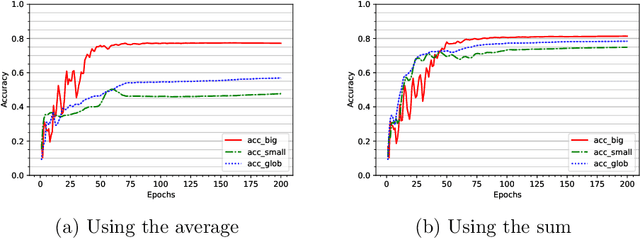
To study the resilience of distributed learning, the "Byzantine" literature considers a strong threat model where workers can report arbitrary gradients to the parameter server. Whereas this model helped obtain several fundamental results, it has sometimes been considered unrealistic, when the workers are mostly trustworthy machines. In this paper, we show a surprising equivalence between this model and data poisoning, a threat considered much more realistic. More specifically, we prove that every gradient attack can be reduced to data poisoning, in any personalized federated learning system with PAC guarantees (which we show are both desirable and realistic). This equivalence makes it possible to obtain new impossibility results on the resilience to data poisoning as corollaries of existing impossibility theorems on Byzantine machine learning. Moreover, using our equivalence, we derive a practical attack that we show (theoretically and empirically) can be very effective against classical personalized federated learning models.
Strategyproof Learning: Building Trustworthy User-Generated Datasets
Jun 04, 2021
Today's large-scale machine learning algorithms harness massive amounts of user-generated data to train large models. However, especially in the context of content recommendation with enormous social, economical and political incentives to promote specific views, products or ideologies, strategic users might be tempted to fabricate or mislabel data in order to bias algorithms in their favor. Unfortunately, today's learning schemes strongly incentivize such strategic data misreporting. This is a major concern, as it endangers the trustworthiness of the entire training datasets, and questions the safety of any algorithm trained on such datasets. In this paper, we show that, perhaps surprisingly, incentivizing data misreporting is not a fatality. We propose the first personalized collaborative learning framework, Licchavi, with provable strategyproofness guarantees through a careful design of the underlying loss function. Interestingly, we also prove that Licchavi is Byzantine resilient: it tolerates a minority of users that provide arbitrary data.