 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Robust Likelihood-Guided Diffusion Posterior Sampling with Amortized Variational Inference
Feb 06, 2026Zero-shot diffusion posterior sampling offers a flexible framework for inverse problems by accommodating arbitrary degradation operators at test time, but incurs high computational cost due to repeated likelihood-guided updates. In contrast, previous amortized diffusion approaches enable fast inference by replacing likelihood-based sampling with implicit inference models, but at the expense of robustness to unseen degradations. We introduce an amortization strategy for diffusion posterior sampling that preserves explicit likelihood guidance by amortizing the inner optimization problems arising in variational diffusion posterior sampling. This accelerates inference for in-distribution degradations while maintaining robustness to previously unseen operators, thereby improving the trade-off between efficiency and flexibility in diffusion-based inverse problems.
Make Inference Faster: Efficient GPU Memory Management for Butterfly Sparse Matrix Multiplication
May 23, 2024



This paper is the first to assess the state of existing sparse matrix multiplication algorithms on GPU for the butterfly structure, a promising form of sparsity. This is achieved through a comprehensive benchmark that can be easily modified to add a new implementation. The goal is to provide a simple tool for users to select the optimal implementation based on their settings. Using this benchmark, we find that existing implementations spend up to 50% of their total runtime on memory rewriting operations. We show that these memory operations can be optimized by introducing a new CUDA kernel that minimizes the transfers between the different levels of GPU memory, achieving a median speed-up factor of x1.4 while also reducing energy consumption (median of x0.85). We also demonstrate the broader significance of our results by showing how the new kernel can speed up the inference of neural networks.
Sparsity in neural networks can improve their privacy
Apr 20, 2023



This article measures how sparsity can make neural networks more robust to membership inference attacks. The obtained empirical results show that sparsity improves the privacy of the network, while preserving comparable performances on the task at hand. This empirical study completes and extends existing literature.
Sparsity in neural networks can increase their privacy
Apr 11, 2023This article measures how sparsity can make neural networks more robust to membership inference attacks. The obtained empirical results show that sparsity improves the privacy of the network, while preserving comparable performances on the task at hand. This empirical study completes and extends existing literature.
Self-supervised learning with rotation-invariant kernels
Jul 28, 2022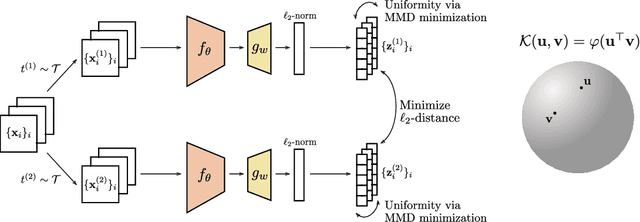
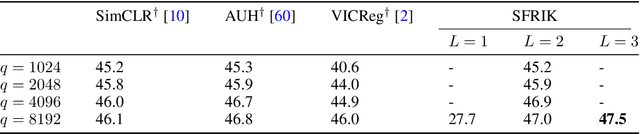
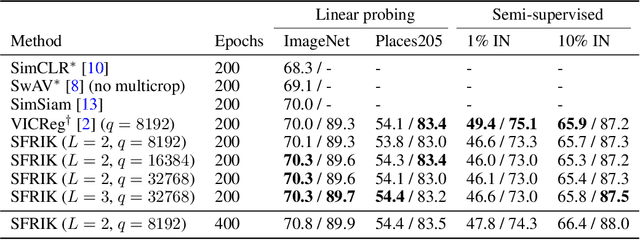

A major paradigm for learning image representations in a self-supervised manner is to learn a model that is invariant to some predefined image transformations (cropping, blurring, color jittering, etc.), while regularizing the embedding distribution to avoid learning a degenerate solution. Our first contribution is to propose a general kernel framework to design a generic regularization loss that promotes the embedding distribution to be close to the uniform distribution on the hypersphere, with respect to the maximum mean discrepancy pseudometric. Our framework uses rotation-invariant kernels defined on the hypersphere, also known as dot-product kernels. Our second contribution is to show that this flexible kernel approach encompasses several existing self-supervised learning methods, including uniformity-based and information-maximization methods. Finally, by exploring empirically several kernel choices, our experiments demonstrate that using a truncated rotation-invariant kernel provides competitive results compared to state-of-the-art methods, and we show practical situations where our method benefits from the kernel trick to reduce computational complexity.
Identifiability in Exact Two-Layer Sparse Matrix Factorization
Oct 04, 2021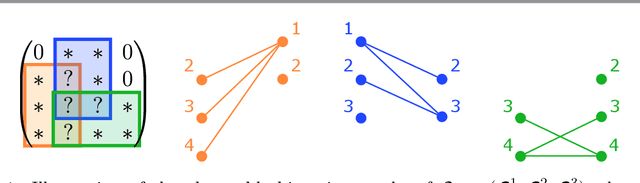
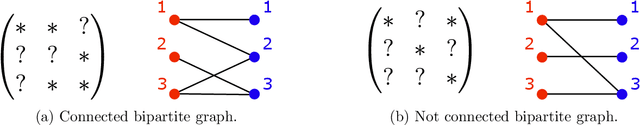
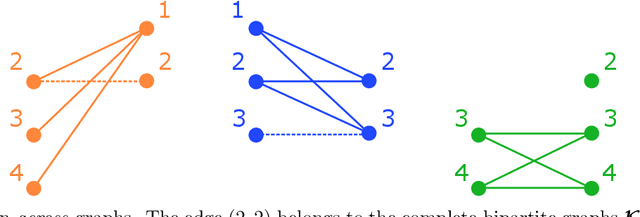
Sparse matrix factorization is the problem of approximating a matrix Z by a product of L sparse factors X^(L) X^(L--1). .. X^(1). This paper focuses on identifiability issues that appear in this problem, in view of better understanding under which sparsity constraints the problem is well-posed. We give conditions under which the problem of factorizing a matrix into two sparse factors admits a unique solution, up to unavoidable permutation and scaling equivalences. Our general framework considers an arbitrary family of prescribed sparsity patterns, allowing us to capture more structured notions of sparsity than simply the count of nonzero entries. These conditions are shown to be related to essential uniqueness of exact matrix decomposition into a sum of rank-one matrices, with structured sparsity constraints. A companion paper further exploits these conditions to derive identifiability properties in multilayer sparse matrix factorization of some well-known matrices like the Hadamard or the discrete Fourier transform matrices.
Identifiability in Exact Multilayer Sparse Matrix Factorization
Oct 04, 2021


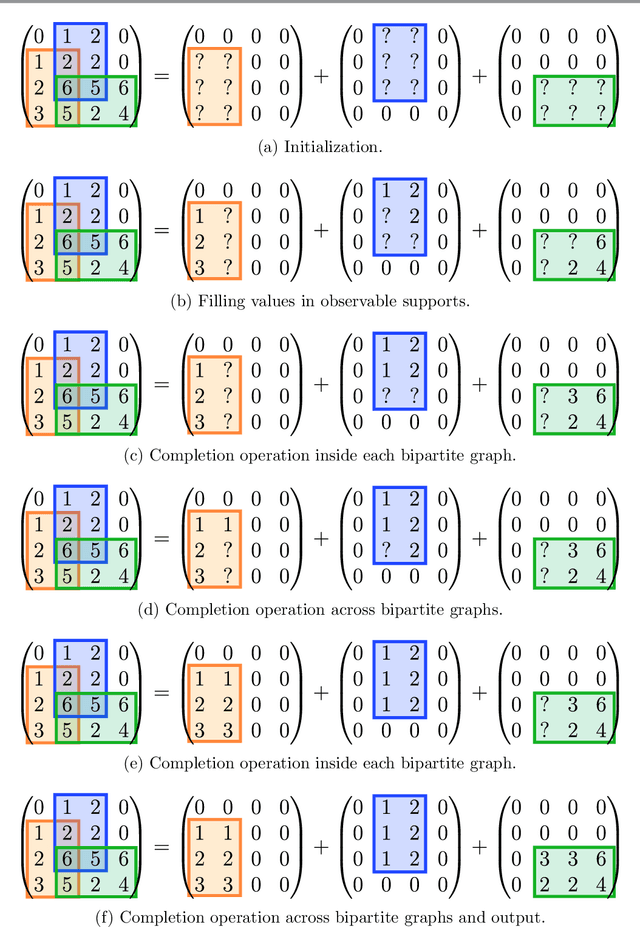
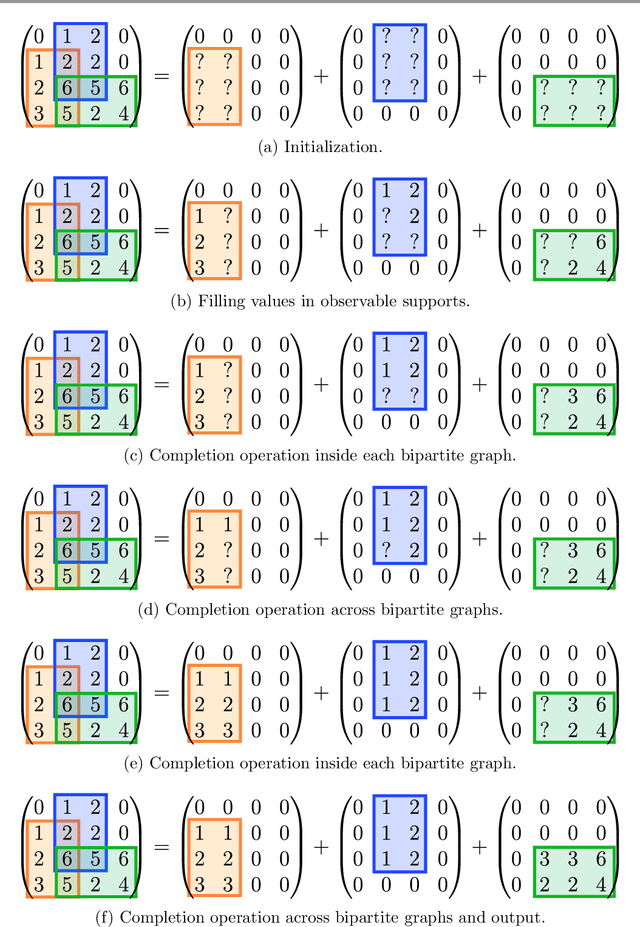
Many well-known matrices Z are associated to fast transforms corresponding to factorizations of the form Z = X^(L). .. X^(1) , where each factor X^(l) is sparse. Based on general result for the case with two factors, established in a companion paper, we investigate essential uniqueness of such factorizations. We show some identifiability results for the sparse factorization into two factors of the discrete Fourier Transform, discrete cosine transform or discrete sine transform matrices of size N = 2^L , when enforcing N/2-sparsity by column on the left factor, and 2-sparsity by row on the right factor. We also show that the analysis with two factors can be extended to the multilayer case, based on a hierarchical factorization method. We prove that any matrix which is the product of L factors whose supports are exactly the so-called butterfly supports, admits a unique sparse factorization into L factors. This applies in particular to the Hadamard or the discrete Fourier transform matrix of size 2^L .