 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive ECCM for Mitigating Smart Jammers
Dec 05, 2022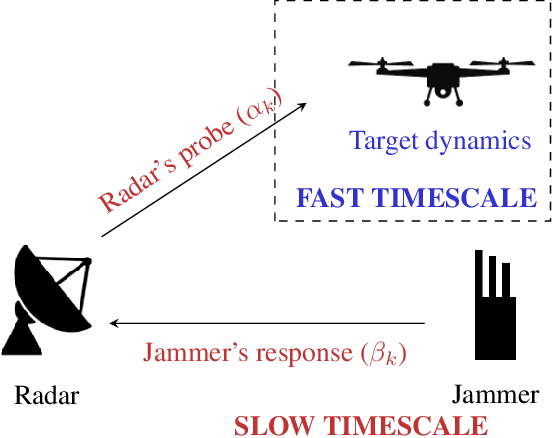
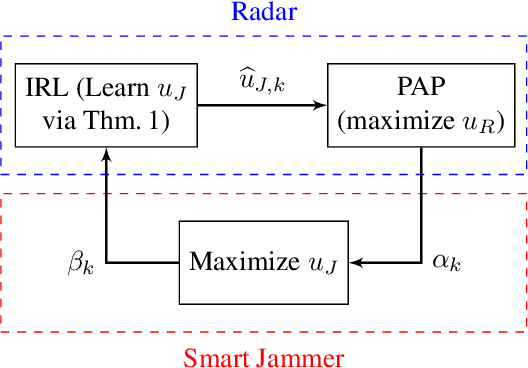
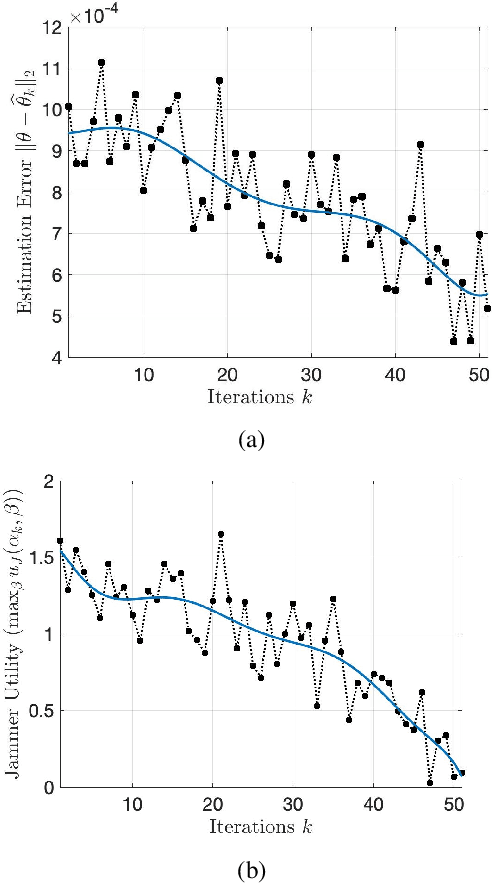
This paper considers adaptive radar electronic counter-counter measures (ECCM) to mitigate ECM by an adversarial jammer. Our ECCM approach models the jammer-radar interaction as a Principal Agent Problem (PAP), a popular economics framework for interaction between two entities with an information imbalance. In our setup, the radar does not know the jammer's utility. Instead, the radar learns the jammer's utility adaptively over time using inverse reinforcement learning. The radar's adaptive ECCM objective is two-fold (1) maximize its utility by solving the PAP, and (2) estimate the jammer's utility by observing its response. Our adaptive ECCM scheme uses deep ideas from revealed preference in micro-economics and principal agent problem in contract theory. Our numerical results show that, over time, our adaptive ECCM both identifies and mitigates the jammer's utility.
How can a Radar Mask its Cognition?
Oct 20, 2022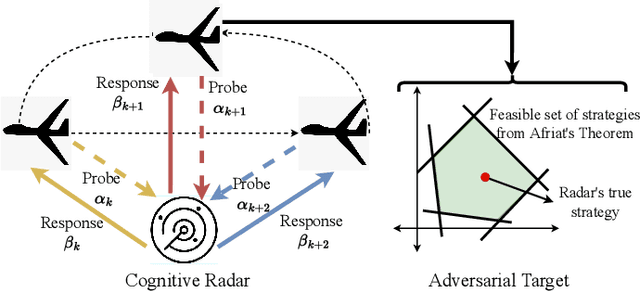

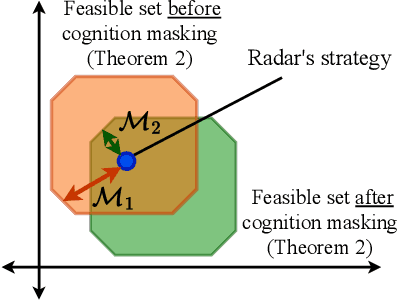
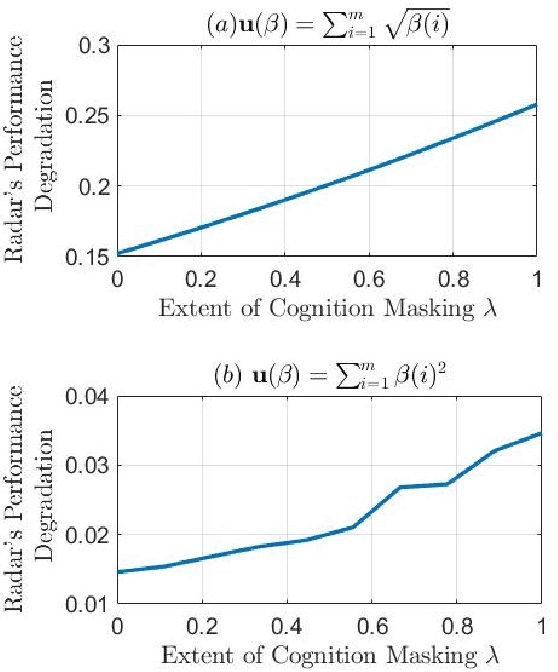
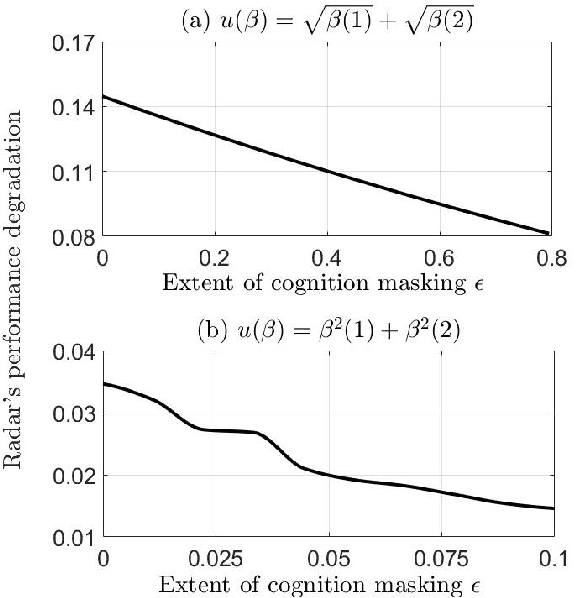
A cognitive radar is a constrained utility maximizer that adapts its sensing mode in response to a changing environment. If an adversary can estimate the utility function of a cognitive radar, it can determine the radar's sensing strategy and mitigate the radar performance via electronic countermeasures (ECM). This paper discusses how a cognitive radar can {\em hide} its strategy from an adversary that detects cognition. The radar does so by transmitting purposefully designed sub-optimal responses to spoof the adversary's Neyman-Pearson detector. We provide theoretical guarantees by ensuring the Type-I error probability of the adversary's detector exceeds a pre-defined level for a specified tolerance on the radar's performance loss. We illustrate our cognition masking scheme via numerical examples involving waveform adaptation and beam allocation. We show that small purposeful deviations from the optimal strategy of the radar confuse the adversary by significant amounts, thereby masking the radar's cognition. Our approach uses novel ideas from revealed preference in microeconomics and adversarial inverse reinforcement learning. Our proposed algorithms provide a principled approach for system-level electronic counter-countermeasures (ECCM) to mask the radar's cognition, i.e., hide the radar's strategy from an adversary. We also provide performance bounds for our cognition masking scheme when the adversary has misspecified measurements of the radar's response.
Inverse-Inverse Reinforcement Learning. How to Hide Strategy from an Adversarial Inverse Reinforcement Learner
May 22, 2022
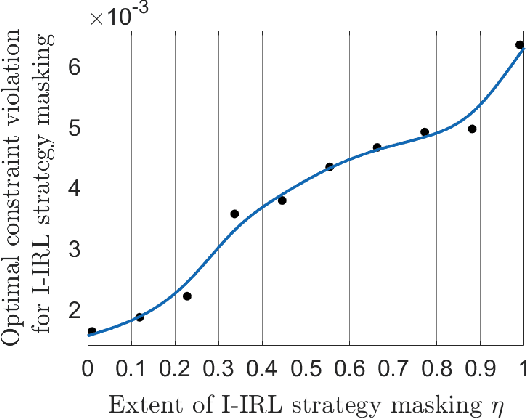
Inverse reinforcement learning (IRL) deals with estimating an agent's utility function from its actions. In this paper, we consider how an agent can hide its strategy and mitigate an adversarial IRL attack; we call this inverse IRL (I-IRL). How should the decision maker choose its response to ensure a poor reconstruction of its strategy by an adversary performing IRL to estimate the agent's strategy? This paper comprises four results: First, we present an adversarial IRL algorithm that estimates the agent's strategy while controlling the agent's utility function. Our second result for I-IRL result spoofs the IRL algorithm used by the adversary. Our I-IRL results are based on revealed preference theory in micro-economics. The key idea is for the agent to deliberately choose sub-optimal responses that sufficiently masks its true strategy. Third, we give a sample complexity result for our main I-IRL result when the agent has noisy estimates of the adversary specified utility function. Finally, we illustrate our I-IRL scheme in a radar problem where a meta-cognitive radar is trying to mitigate an adversarial target.
Meta-Cognition. An Inverse-Inverse Reinforcement Learning Approach for Cognitive Radars
May 03, 2022

This paper considers meta-cognitive radars in an adversarial setting. A cognitive radar optimally adapts its waveform (response) in response to maneuvers (probes) of a possibly adversarial moving target. A meta-cognitive radar is aware of the adversarial nature of the target and seeks to mitigate the adversarial target. How should the meta-cognitive radar choose its responses to sufficiently confuse the adversary trying to estimate the radar's utility function? This paper abstracts the radar's meta-cognition problem in terms of the spectra (eigenvalues) of the state and observation noise covariance matrices, and embeds the algebraic Riccati equation into an economics-based utility maximization setup. This adversarial target is an inverse reinforcement learner. By observing a noisy sequence of radar's responses (waveforms), the adversarial target uses a statistical hypothesis test to detect if the radar is a utility maximizer. In turn, the meta-cognitive radar deliberately chooses sub-optimal responses that increasing its Type-I error probability of the adversary's detector. We call this counter-adversarial step taken by the meta-cognitive radar as inverse inverse reinforcement learning (I-IRL). We illustrate the meta-cognition results of this paper via simple numerical examples. Our approach for meta-cognition in this paper is based on revealed preference theory in micro-economics and inspired by results in differential privacy and adversarial obfuscation in machine learning.
How can a Cognitive Radar Mask its Cognition?
Oct 16, 2021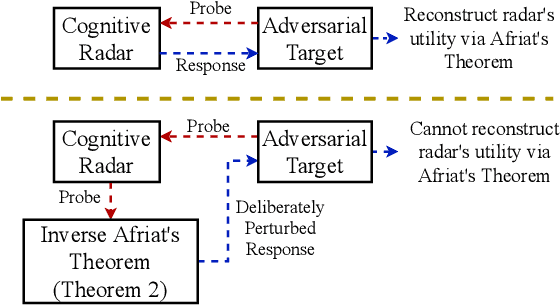
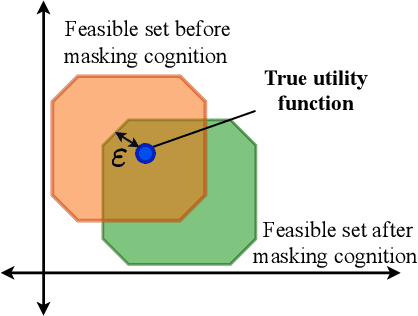
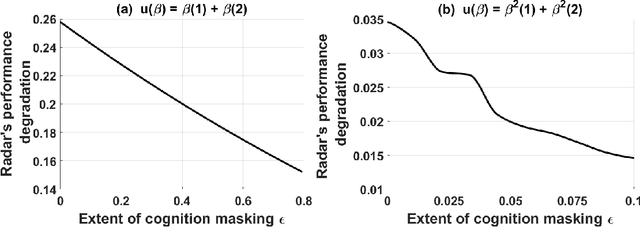
We study how a cognitive radar can mask (hide) its cognitive ability from an adversarial jamming device. Specifically, if the radar optimally adapts its waveform based on adversarial target maneuvers (probes), how should the radar choose its waveform parameters (response) so that its utility function cannot be recovered by the adversary. This paper abstracts the radar's cognition masking problem in terms of the spectra (eigenvalues) of the state and observation noise covariance matrices, and embeds the algebraic Riccati equation into an economics-based utility maximization setup. Given an observed sequence of radar responses, the adversary tests for utility maximization behavior of the radar and estimates its utility function that rationalizes the radar's responses. In turn, the radar deliberately chooses sub-optimal responses so that its utility function almost fails the utility maximization test, and hence, its cognitive ability is masked from the adversary. We illustrate the performance of our cognition masking scheme via simple numerical examples. Our approach in this paper is based on revealed preference theory in microeconomics for identifying rationality.
Behavioral Economics Approach to Interpretable Deep Image Classification. Rationally Inattentive Utility Maximization Explains Deep Image Classification
Feb 16, 2021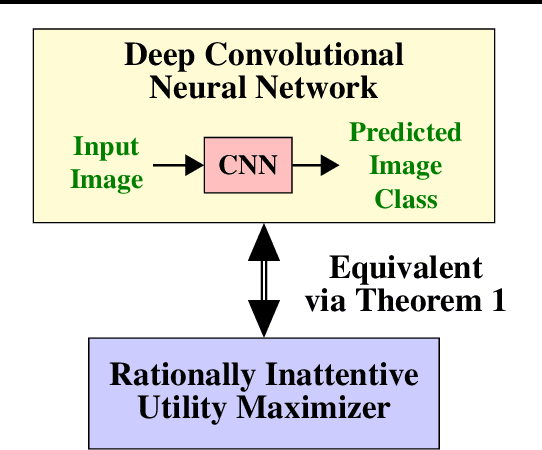

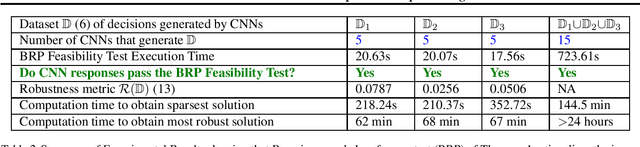
Are deep convolutional neural networks (CNNs) for image classification consistent with utility maximization behavior with information acquisition costs? This paper demonstrates the remarkable result that a deep CNN behaves equivalently (in terms of necessary and sufficient conditions) to a rationally inattentive utility maximizer, a model extensively used in behavioral economics to explain human decision making. This implies that a deep CNN has a parsimonious representation in terms of simple intuitive human-like decision parameters, namely, a utility function and an information acquisition cost. Also the reconstructed utility function that rationalizes the decisions of the deep CNNs, yields a useful preference order amongst the image classes (hypotheses).
Adversarial Radar Inference: Inverse Tracking, Identifying Cognition and Designing Smart Interference
Aug 01, 2020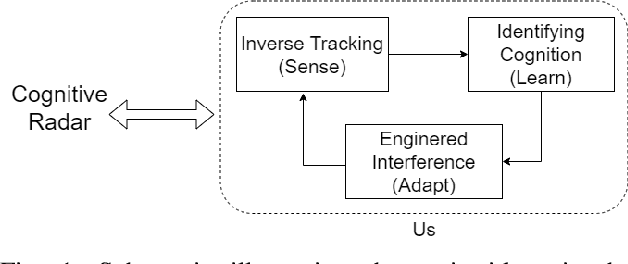
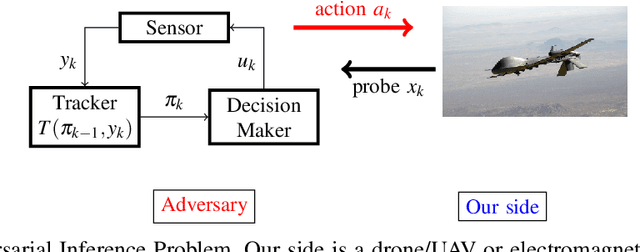
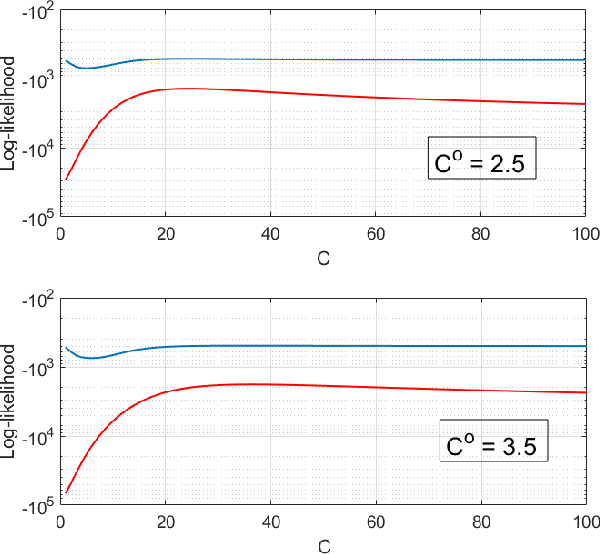
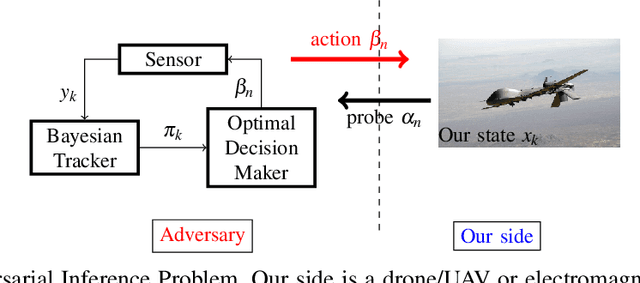
This paper considers three inter-related adversarial inference problems involving cognitive radars. We first discuss inverse tracking of the radar to estimate the adversary's estimate of us based on the radar's actions and calibrate the radar's sensing accuracy. Second, using revealed preference from microeconomics, we formulate a non-parametric test to identify if the cognitive radar is a constrained utility maximizer with signal processing constraints. We consider two radar functionalities, namely, beam allocation and waveform design, with respect to which the cognitive radar is assumed to maximize its utility and construct a set-valued estimator for the radar's utility function. Finally, we discuss how to engineer interference at the physical layer level to confuse the radar which forces it to change its transmit waveform. The levels of abstraction range from smart interference design based on Wiener filters (at the pulse/waveform level), inverse Kalman filters at the tracking level and revealed preferences for identifying utility maximization at the systems level.
Inverse Reinforcement Learning for Sequential Hypothesis Testing and Search
Jul 07, 2020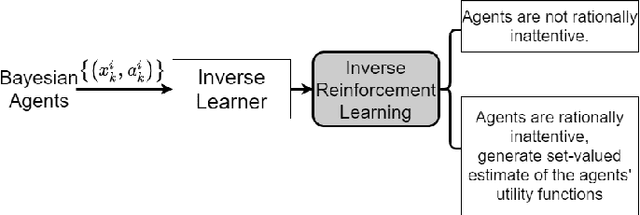



This paper considers a novel formulation of inverse reinforcement learning~(IRL) with behavioral economics constraints to address inverse sequential hypothesis testing (SHT) and inverse search in Bayesian agents. We first estimate the stopping and search costs by observing the actions of these agents using Bayesian revealed preference from microeconomics and rational inattention from behavioral economics. We also solve the inverse problem of the more general rationally inattentive SHT where the agent incorporates controlled sensing by optimally choosing from various sensing modes. Second, we design statistical hypothesis tests with bounded Type-I and Type-II error probabilities to detect if the agents are Bayesian utility maximizers when their actions are measured in noise. By dynamically tuning the prior specified to the agents, we formulate an {\em active} IRL framework which enhances these detection tests and minimizes their Type-II and Type-I error probabilities of utility maximization detection. Finally, we give a finite sample complexity result which provides finite sample bounds on the error probabilities of the detection tests.
Rationally Inattentive Inverse Reinforcement Learning Explains YouTube Commenting Behavior
Oct 24, 2019

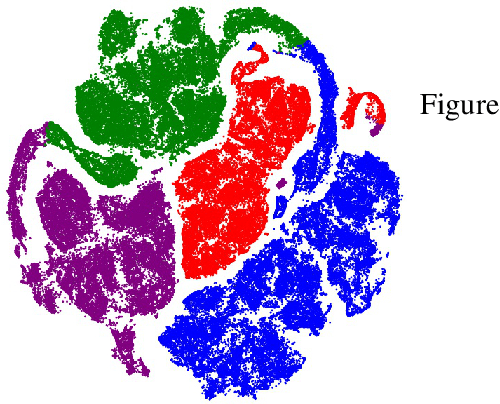
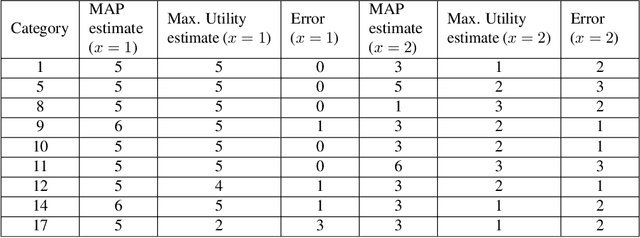
We consider a novel application of inverse reinforcement learning which involves modeling, learning and predicting the commenting behavior of YouTube viewers. Each group of users is modeled as a rationally inattentive Bayesian agent. Our methodology integrates three key components. First, to identify distinct commenting patterns, we use deep embedded clustering to estimate framing information (essential extrinsic features) that clusters users into distinct groups. Second, we present an inverse reinforcement learning algorithm that uses Bayesian revealed preferences to test for rationality: does there exist a utility function that rationalizes the given data, and if yes, can it be used to predict future behavior? Finally, we impose behavioral economics constraints stemming from rational inattention to characterize the attention span of groups of users.The test imposes a R{\'e}nyi mutual information cost constraint which impacts how the agent can select attention strategies to maximize their expected utility. After a careful analysis of a massive YouTube dataset, our surprising result is that in most YouTube user groups, the commenting behavior is consistent with optimizing a Bayesian utility with rationally inattentive constraints. The paper also highlights how the rational inattention model can accurately predict future commenting behavior. The massive YouTube dataset and analysis used in this paper are available on GitHub and completely reproducible.