 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow can a Radar Mask its Cognition?
Oct 20, 2022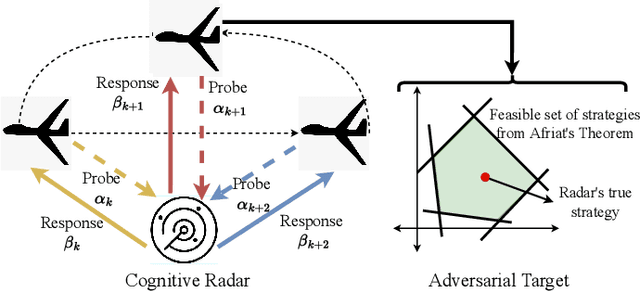

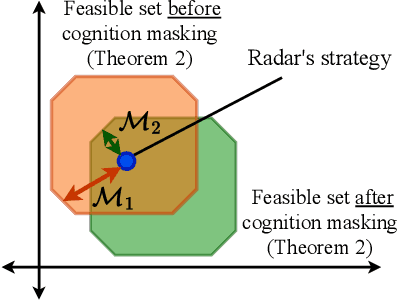
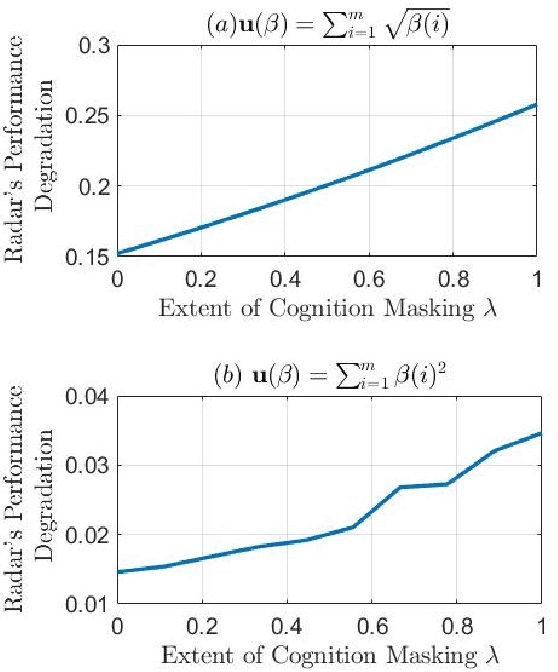
A cognitive radar is a constrained utility maximizer that adapts its sensing mode in response to a changing environment. If an adversary can estimate the utility function of a cognitive radar, it can determine the radar's sensing strategy and mitigate the radar performance via electronic countermeasures (ECM). This paper discusses how a cognitive radar can {\em hide} its strategy from an adversary that detects cognition. The radar does so by transmitting purposefully designed sub-optimal responses to spoof the adversary's Neyman-Pearson detector. We provide theoretical guarantees by ensuring the Type-I error probability of the adversary's detector exceeds a pre-defined level for a specified tolerance on the radar's performance loss. We illustrate our cognition masking scheme via numerical examples involving waveform adaptation and beam allocation. We show that small purposeful deviations from the optimal strategy of the radar confuse the adversary by significant amounts, thereby masking the radar's cognition. Our approach uses novel ideas from revealed preference in microeconomics and adversarial inverse reinforcement learning. Our proposed algorithms provide a principled approach for system-level electronic counter-countermeasures (ECCM) to mask the radar's cognition, i.e., hide the radar's strategy from an adversary. We also provide performance bounds for our cognition masking scheme when the adversary has misspecified measurements of the radar's response.
Inverse-Inverse Reinforcement Learning. How to Hide Strategy from an Adversarial Inverse Reinforcement Learner
May 22, 2022
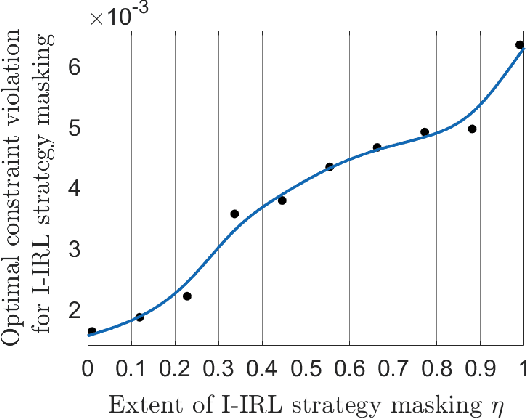
Inverse reinforcement learning (IRL) deals with estimating an agent's utility function from its actions. In this paper, we consider how an agent can hide its strategy and mitigate an adversarial IRL attack; we call this inverse IRL (I-IRL). How should the decision maker choose its response to ensure a poor reconstruction of its strategy by an adversary performing IRL to estimate the agent's strategy? This paper comprises four results: First, we present an adversarial IRL algorithm that estimates the agent's strategy while controlling the agent's utility function. Our second result for I-IRL result spoofs the IRL algorithm used by the adversary. Our I-IRL results are based on revealed preference theory in micro-economics. The key idea is for the agent to deliberately choose sub-optimal responses that sufficiently masks its true strategy. Third, we give a sample complexity result for our main I-IRL result when the agent has noisy estimates of the adversary specified utility function. Finally, we illustrate our I-IRL scheme in a radar problem where a meta-cognitive radar is trying to mitigate an adversarial target.
Meta-Cognition. An Inverse-Inverse Reinforcement Learning Approach for Cognitive Radars
May 03, 2022

This paper considers meta-cognitive radars in an adversarial setting. A cognitive radar optimally adapts its waveform (response) in response to maneuvers (probes) of a possibly adversarial moving target. A meta-cognitive radar is aware of the adversarial nature of the target and seeks to mitigate the adversarial target. How should the meta-cognitive radar choose its responses to sufficiently confuse the adversary trying to estimate the radar's utility function? This paper abstracts the radar's meta-cognition problem in terms of the spectra (eigenvalues) of the state and observation noise covariance matrices, and embeds the algebraic Riccati equation into an economics-based utility maximization setup. This adversarial target is an inverse reinforcement learner. By observing a noisy sequence of radar's responses (waveforms), the adversarial target uses a statistical hypothesis test to detect if the radar is a utility maximizer. In turn, the meta-cognitive radar deliberately chooses sub-optimal responses that increasing its Type-I error probability of the adversary's detector. We call this counter-adversarial step taken by the meta-cognitive radar as inverse inverse reinforcement learning (I-IRL). We illustrate the meta-cognition results of this paper via simple numerical examples. Our approach for meta-cognition in this paper is based on revealed preference theory in micro-economics and inspired by results in differential privacy and adversarial obfuscation in machine learning.
How can a Cognitive Radar Mask its Cognition?
Oct 16, 2021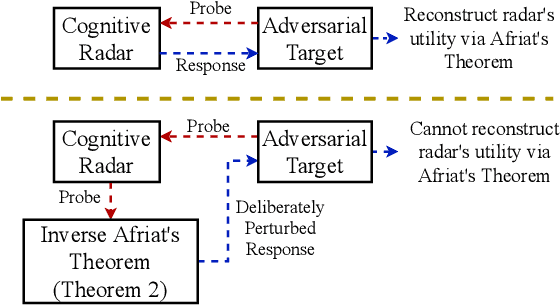
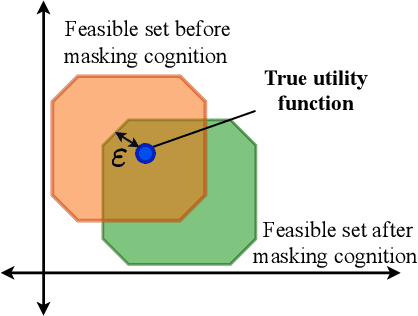
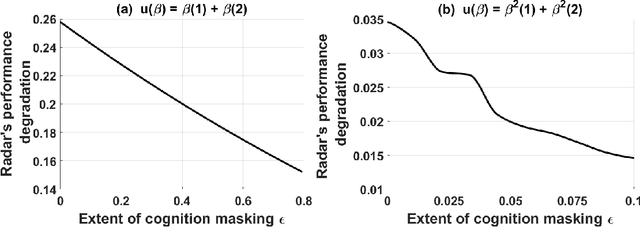
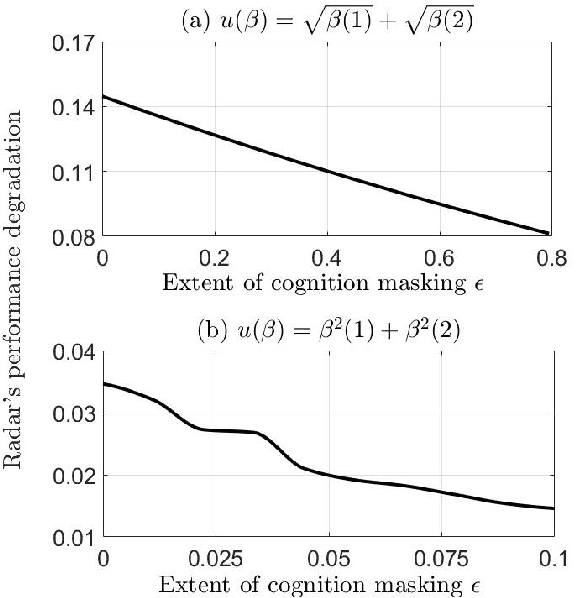
We study how a cognitive radar can mask (hide) its cognitive ability from an adversarial jamming device. Specifically, if the radar optimally adapts its waveform based on adversarial target maneuvers (probes), how should the radar choose its waveform parameters (response) so that its utility function cannot be recovered by the adversary. This paper abstracts the radar's cognition masking problem in terms of the spectra (eigenvalues) of the state and observation noise covariance matrices, and embeds the algebraic Riccati equation into an economics-based utility maximization setup. Given an observed sequence of radar responses, the adversary tests for utility maximization behavior of the radar and estimates its utility function that rationalizes the radar's responses. In turn, the radar deliberately chooses sub-optimal responses so that its utility function almost fails the utility maximization test, and hence, its cognitive ability is masked from the adversary. We illustrate the performance of our cognition masking scheme via simple numerical examples. Our approach in this paper is based on revealed preference theory in microeconomics for identifying rationality.