 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLizard: A Large-Scale Dataset for Colonic Nuclear Instance Segmentation and Classification
Aug 25, 2021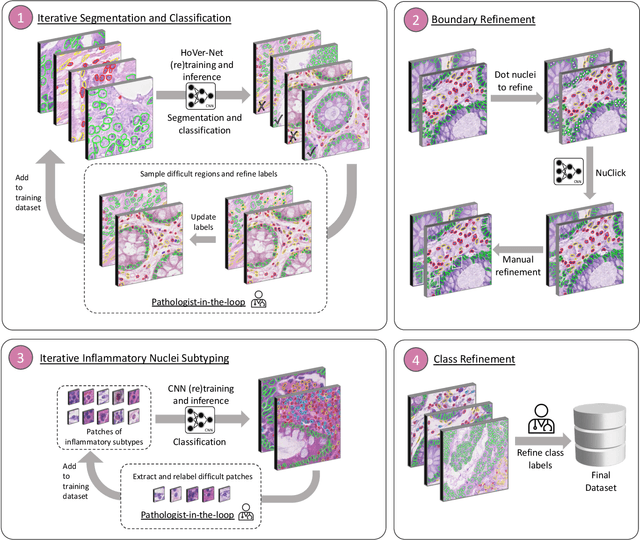
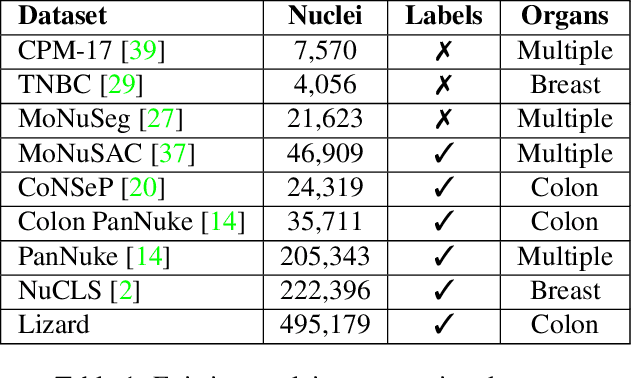
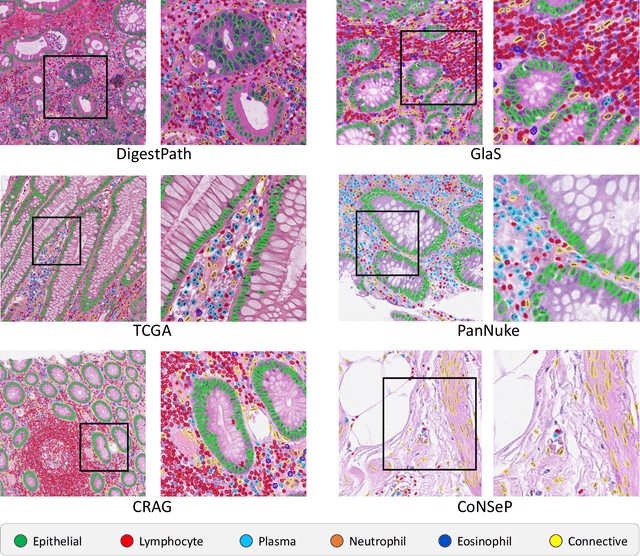
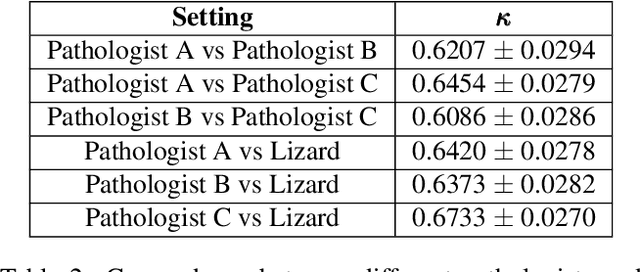
The development of deep segmentation models for computational pathology (CPath) can help foster the investigation of interpretable morphological biomarkers. Yet, there is a major bottleneck in the success of such approaches because supervised deep learning models require an abundance of accurately labelled data. This issue is exacerbated in the field of CPath because the generation of detailed annotations usually demands the input of a pathologist to be able to distinguish between different tissue constructs and nuclei. Manually labelling nuclei may not be a feasible approach for collecting large-scale annotated datasets, especially when a single image region can contain thousands of different cells. However, solely relying on automatic generation of annotations will limit the accuracy and reliability of ground truth. Therefore, to help overcome the above challenges, we propose a multi-stage annotation pipeline to enable the collection of large-scale datasets for histology image analysis, with pathologist-in-the-loop refinement steps. Using this pipeline, we generate the largest known nuclear instance segmentation and classification dataset, containing nearly half a million labelled nuclei in H&E stained colon tissue. We have released the dataset and encourage the research community to utilise it to drive forward the development of downstream cell-based models in CPath.
PanNuke Dataset Extension, Insights and Baselines
Apr 22, 2020
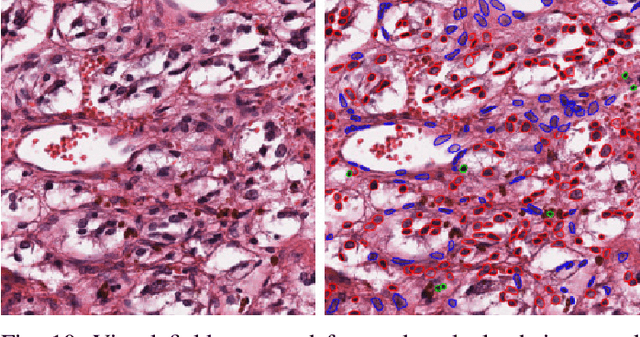
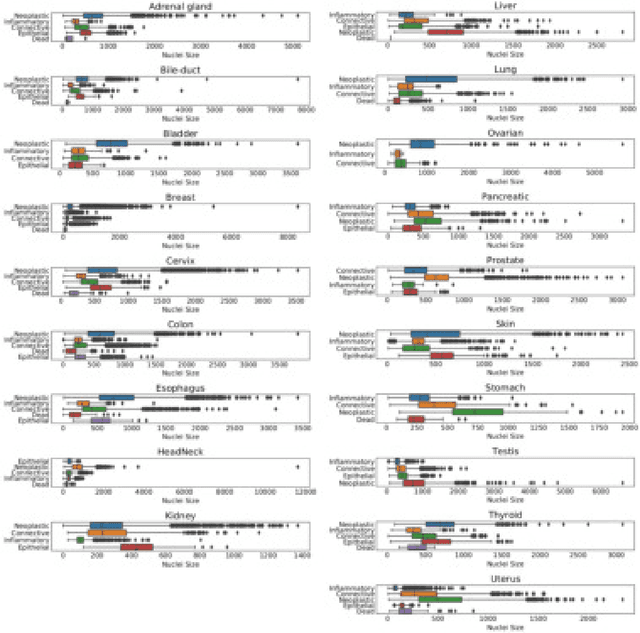
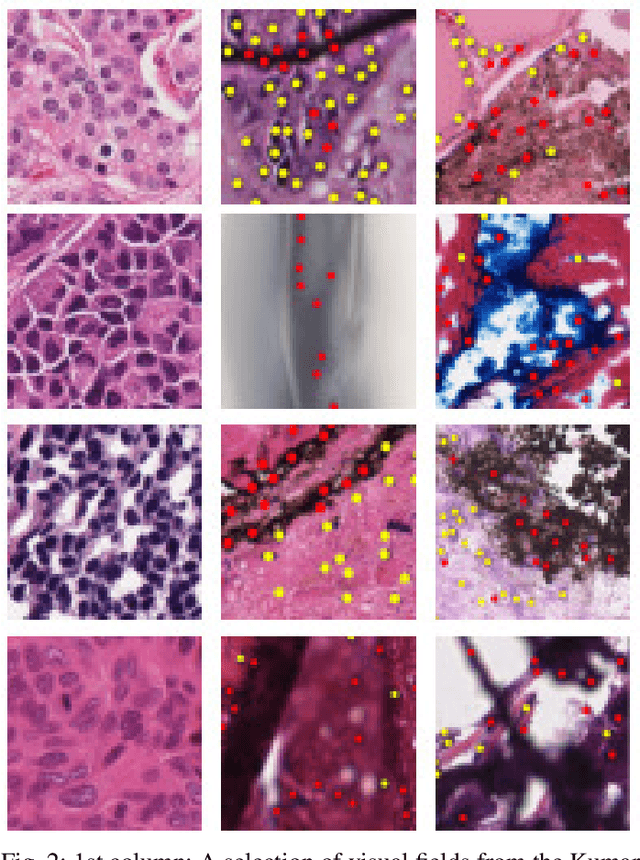
The emerging area of computational pathology (CPath) is ripe ground for the application of deep learning (DL) methods to healthcare due to the sheer volume of raw pixel data in whole-slide images (WSIs) of cancerous tissue slides. However, it is imperative for the DL algorithms relying on nuclei-level details to be able to cope with data from `the clinical wild', which tends to be quite challenging. We study, and extend recently released PanNuke dataset consisting of ~200,000 nuclei categorized into 5 clinically important classes for the challenging tasks of segmenting and classifying nuclei in WSIs. Previous pan-cancer datasets consisted of only up to 9 different tissues and up to 21,000 unlabeled nuclei and just over 24,000 labeled nuclei with segmentation masks. PanNuke consists of 19 different tissue types that have been semi-automatically annotated and quality controlled by clinical pathologists, leading to a dataset with statistics similar to the clinical wild and with minimal selection bias. We study the performance of segmentation and classification models when applied to the proposed dataset and demonstrate the application of models trained on PanNuke to whole-slide images. We provide comprehensive statistics about the dataset and outline recommendations and research directions to address the limitations of existing DL tools when applied to real-world CPath applications.