 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-accelerated graph neural networks: an alternative approach for neuromorphic event-based audio classification and keyword spotting on SoC FPGA
Feb 18, 2026As the volume of data recorded by embedded edge sensors increases, particularly from neuromorphic devices producing discrete event streams, there is a growing need for hardware-aware neural architectures that enable efficient, low-latency, and energy-conscious local processing. We present an FPGA implementation of event-graph neural networks for audio processing. We utilise an artificial cochlea that converts time-series signals into sparse event data, reducing memory and computation costs. Our architecture was implemented on a SoC FPGA and evaluated on two open-source datasets. For classification task, our baseline floating-point model achieves 92.7% accuracy on SHD dataset - only 2.4% below the state of the art - while requiring over 10x and 67x fewer parameters. On SSC, our models achieve 66.9-71.0% accuracy. Compared to FPGA-based spiking neural networks, our quantised model reaches 92.3% accuracy, outperforming them by up to 19.3% while reducing resource usage and latency. For SSC, we report the first hardware-accelerated evaluation. We further demonstrate the first end-to-end FPGA implementation of event-audio keyword spotting, combining graph convolutional layers with recurrent sequence modelling. The system achieves up to 95% word-end detection accuracy, with only 10.53 microsecond latency and 1.18 W power consumption, establishing a strong benchmark for energy-efficient event-driven KWS.
Hardware-Accelerated Event-Graph Neural Networks for Low-Latency Time-Series Classification on SoC FPGA
Mar 09, 2025



As the quantities of data recorded by embedded edge sensors grow, so too does the need for intelligent local processing. Such data often comes in the form of time-series signals, based on which real-time predictions can be made locally using an AI model. However, a hardware-software approach capable of making low-latency predictions with low power consumption is required. In this paper, we present a hardware implementation of an event-graph neural network for time-series classification. We leverage an artificial cochlea model to convert the input time-series signals into a sparse event-data format that allows the event-graph to drastically reduce the number of calculations relative to other AI methods. We implemented the design on a SoC FPGA and applied it to the real-time processing of the Spiking Heidelberg Digits (SHD) dataset to benchmark our approach against competitive solutions. Our method achieves a floating-point accuracy of 92.7% on the SHD dataset for the base model, which is only 2.4% and 2% less than the state-of-the-art models with over 10% and 67% fewer model parameters, respectively. It also outperforms FPGA-based spiking neural network implementations by 19.3% and 4.5%, achieving 92.3% accuracy for the quantised model while using fewer computational resources and reducing latency.
Utilisation of Vision Systems and Digital Twin for Maintaining Cleanliness in Public Spaces
Nov 08, 2024Nowadays, the increasing demand for maintaining high cleanliness standards in public spaces results in the search for innovative solutions. The deployment of CCTV systems equipped with modern cameras and software enables not only real-time monitoring of the cleanliness status but also automatic detection of impurities and optimisation of cleaning schedules. The Digital Twin technology allows for the creation of a virtual model of the space, facilitating the simulation, training, and testing of cleanliness management strategies before implementation in the real world. In this paper, we present the utilisation of advanced vision surveillance systems and the Digital Twin technology in cleanliness management, using a railway station as an example. The Digital Twin was created based on an actual 3D model in the Nvidia Omniverse Isaac Sim simulator. A litter detector, bin occupancy level detector, stain segmentation, and a human detector (including the cleaning crew) along with their movement analysis were implemented. A preliminary assessment was conducted, and potential modifications for further enhancement and future development of the system were identified.
Embedded Graph Convolutional Networks for Real-Time Event Data Processing on SoC FPGAs
Jun 11, 2024The utilisation of event cameras represents an important and swiftly evolving trend aimed at addressing the constraints of traditional video systems. Particularly within the automotive domain, these cameras find significant relevance for their integration into embedded real-time systems due to lower latency and energy consumption. One effective approach to ensure the necessary throughput and latency for event processing systems is through the utilisation of graph convolutional networks (GCNs). In this study, we introduce a series of hardware-aware optimisations tailored for PointNet++, a GCN architecture designed for point cloud processing. The proposed techniques result in more than a 100-fold reduction in model size compared to Asynchronous Event-based GNN (AEGNN), one of the most recent works in the field, with a relatively small decrease in accuracy (2.3% for N-Caltech101 classification, 1.7% for N-Cars classification), thus following the TinyML trend. Based on software research, we designed a custom EFGCN (Event-Based FPGA-accelerated Graph Convolutional Network) and we implemented it on ZCU104 SoC FPGA platform, achieving a throughput of 13.3 million events per second (MEPS) and real-time partially asynchronous processing with a latency of 4.47 ms. We also address the scalability of the proposed hardware model to improve the obtained accuracy score. To the best of our knowledge, this study marks the first endeavour in accelerating PointNet++ networks on SoC FPGAs, as well as the first hardware architecture exploration of graph convolutional networks implementation for real-time continuous event data processing. We publish both software and hardware source code in an open repository: https://github.com/vision-agh/*** (will be published upon acceptance).
Optimising Graph Representation for Hardware Implementation of Graph Convolutional Networks for Event-based Vision
Jan 10, 2024Event-based vision is an emerging research field involving processing data generated by Dynamic Vision Sensors (neuromorphic cameras). One of the latest proposals in this area are Graph Convolutional Networks (GCNs), which allow to process events in its original sparse form while maintaining high detection and classification performance. In this paper, we present the hardware implementation of a~graph generation process from an event camera data stream, taking into account both the advantages and limitations of FPGAs. We propose various ways to simplify the graph representation and use scaling and quantisation of values. We consider both undirected and directed graphs that enable the use of PointNet convolution. The results obtained show that by appropriately modifying the graph representation, it is possible to create a~hardware module for graph generation. Moreover, the proposed modifications have no significant impact on object detection performance, only 0.08% mAP less for the base model and the N-Caltech data set.Finally, we describe the proposed hardware architecture of the graph generation module.
High-definition event frame generation using SoC FPGA devices
Jul 26, 2023In this paper we have addressed the implementation of the accumulation and projection of high-resolution event data stream (HD -1280 x 720 pixels) onto the image plane in FPGA devices. The results confirm the feasibility of this approach, but there are a number of challenges, limitations and trade-offs to be considered. The required hardware resources of selected data representations, such as binary frame, event frame, exponentially decaying time surface and event frequency, were compared with those available on several popular platforms from AMD Xilinx. The resulting event frames can be used for typical vision algorithms, such as object classification and detection, using both classical and deep neural network methods.
Fast-moving object counting with an event camera
Dec 16, 2022This paper proposes the use of an event camera as a component of a vision system that enables counting of fast-moving objects - in this case, falling corn grains. These type of cameras transmit information about the change in brightness of individual pixels and are characterised by low latency, no motion blur, correct operation in different lighting conditions, as well as very low power consumption. The proposed counting algorithm processes events in real time. The operation of the solution was demonstrated on a stand consisting of a chute with a vibrating feeder, which allowed the number of grains falling to be adjusted. The objective of the control system with a PID controller was to maintain a constant average number of falling objects. The proposed solution was subjected to a series of tests to determine the correctness of the developed method operation. On their basis, the validity of using an event camera to count small, fast-moving objects and the associated wide range of potential industrial applications can be confirmed.
Optimisation of a Siamese Neural Network for Real-Time Energy Efficient Object Tracking
Jul 01, 2020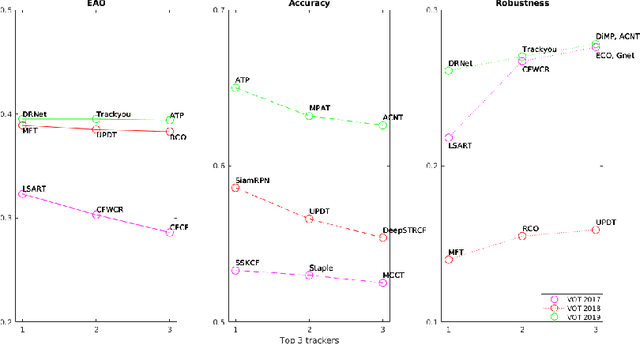

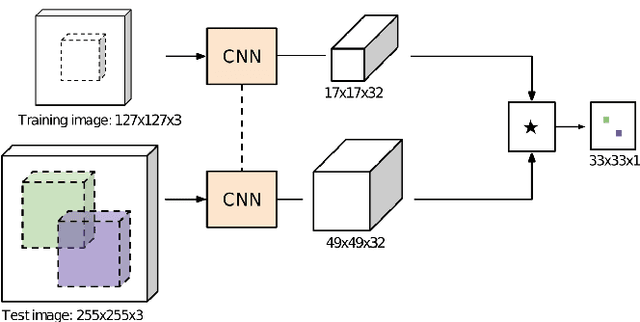

In this paper the research on optimisation of visual object tracking using a Siamese neural network for embedded vision systems is presented. It was assumed that the solution shall operate in real-time, preferably for a high resolution video stream, with the lowest possible energy consumption. To meet these requirements, techniques such as the reduction of computational precision and pruning were considered. Brevitas, a tool dedicated for optimisation and quantisation of neural networks for FPGA implementation, was used. A number of training scenarios were tested with varying levels of optimisations - from integer uniform quantisation with 16 bits to ternary and binary networks. Next, the influence of these optimisations on the tracking performance was evaluated. It was possible to reduce the size of the convolutional filters up to 10 times in relation to the original network. The obtained results indicate that using quantisation can significantly reduce the memory and computational complexity of the proposed network while still enabling precise tracking, thus allow to use it in embedded vision systems. Moreover, quantisation of weights positively affects the network training by decreasing overfitting.
Vision based hardware-software real-time control system for autonomous landing of an UAV
Apr 24, 2020

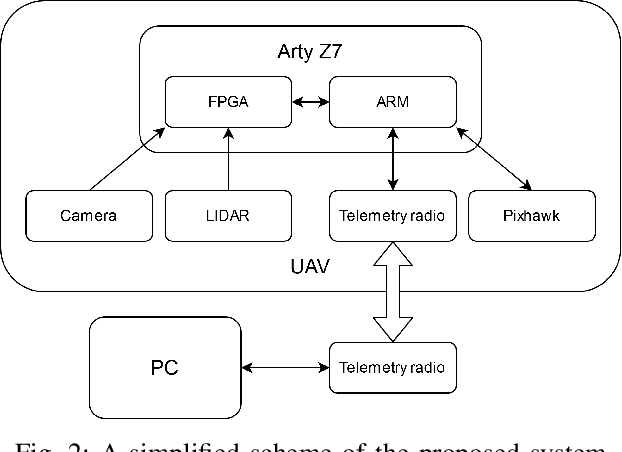

In this paper we present a vision based hardware-software control system enabling autonomous landing of a multirotor unmanned aerial vehicle (UAV). It allows the detection of a marked landing pad in real-time for a 1280 x 720 @ 60 fps video stream. In addition, a LiDAR sensor is used to measure the altitude above ground. A heterogeneous Zynq SoC device is used as the computing platform. The solution was tested on a number of sequences and the landing pad was detected with 96% accuracy. This research shows that a reprogrammable heterogeneous computing system is a good solution for UAVs because it enables real-time data stream processing with relatively low energy consumption.