 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-Aware Feature Extraction Quantisation for Real-Time Visual Odometry on FPGA Platforms
Jul 10, 2025Accurate position estimation is essential for modern navigation systems deployed in autonomous platforms, including ground vehicles, marine vessels, and aerial drones. In this context, Visual Simultaneous Localisation and Mapping (VSLAM) - which includes Visual Odometry - relies heavily on the reliable extraction of salient feature points from the visual input data. In this work, we propose an embedded implementation of an unsupervised architecture capable of detecting and describing feature points. It is based on a quantised SuperPoint convolutional neural network. Our objective is to minimise the computational demands of the model while preserving high detection quality, thus facilitating efficient deployment on platforms with limited resources, such as mobile or embedded systems. We implemented the solution on an FPGA System-on-Chip (SoC) platform, specifically the AMD/Xilinx Zynq UltraScale+, where we evaluated the performance of Deep Learning Processing Units (DPUs) and we also used the Brevitas library and the FINN framework to perform model quantisation and hardware-aware optimisation. This allowed us to process 640 x 480 pixel images at up to 54 fps on an FPGA platform, outperforming state-of-the-art solutions in the field. We conducted experiments on the TUM dataset to demonstrate and discuss the impact of different quantisation techniques on the accuracy and performance of the model in a visual odometry task.
Vision-based automatic fruit counting with UAV
Mar 17, 2025The use of unmanned aerial vehicles (UAVs) for smart agriculture is becoming increasingly popular. This is evidenced by recent scientific works, as well as the various competitions organised on this topic. Therefore, in this work we present a system for automatic fruit counting using UAVs. To detect them, our solution uses a vision algorithm that processes streams from an RGB camera and a depth sensor using classical image operations. Our system also allows the planning and execution of flight trajectories, taking into account the minimisation of flight time and distance covered. We tested the proposed solution in simulation and obtained an average score of 87.27/100 points from a total of 500 missions. We also submitted it to the UAV Competition organised as part of the ICUAS 2024 conference, where we achieved an average score of 84.83/100 points, placing 6th in a field of 23 teams and advancing to the finals.
Utilisation of Vision Systems and Digital Twin for Maintaining Cleanliness in Public Spaces
Nov 08, 2024Nowadays, the increasing demand for maintaining high cleanliness standards in public spaces results in the search for innovative solutions. The deployment of CCTV systems equipped with modern cameras and software enables not only real-time monitoring of the cleanliness status but also automatic detection of impurities and optimisation of cleaning schedules. The Digital Twin technology allows for the creation of a virtual model of the space, facilitating the simulation, training, and testing of cleanliness management strategies before implementation in the real world. In this paper, we present the utilisation of advanced vision surveillance systems and the Digital Twin technology in cleanliness management, using a railway station as an example. The Digital Twin was created based on an actual 3D model in the Nvidia Omniverse Isaac Sim simulator. A litter detector, bin occupancy level detector, stain segmentation, and a human detector (including the cleaning crew) along with their movement analysis were implemented. A preliminary assessment was conducted, and potential modifications for further enhancement and future development of the system were identified.
Implementation of a perception system for autonomous vehicles using a detection-segmentation network in SoC FPGA
Jul 17, 2023Perception and control systems for autonomous vehicles are an active area of scientific and industrial research. These solutions should be characterised by high efficiency in recognising obstacles and other environmental elements in different road conditions, real-time capability, and energy efficiency. Achieving such functionality requires an appropriate algorithm and a suitable computing platform. In this paper, we have used the MultiTaskV3 detection-segmentation network as the basis for a perception system that can perform both functionalities within a single architecture. It was appropriately trained, quantised, and implemented on the AMD Xilinx Kria KV260 Vision AI embedded platform. By using this device, it was possible to parallelise and accelerate the computations. Furthermore, the whole system consumes relatively little power compared to a CPU-based implementation (an average of 5 watts, compared to the minimum of 55 watts for weaker CPUs, and the small size (119mm x 140mm x 36mm) of the platform allows it to be used in devices where the amount of space available is limited. It also achieves an accuracy higher than 97% of the mAP (mean average precision) for object detection and above 90% of the mIoU (mean intersection over union) for image segmentation. The article also details the design of the Mecanum wheel vehicle, which was used to test the proposed solution in a mock-up city.
Detection-segmentation convolutional neural network for autonomous vehicle perception
Jun 30, 2023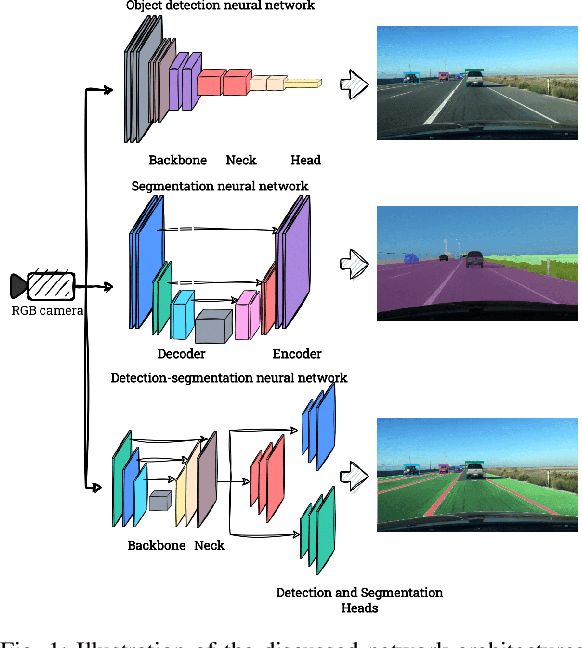
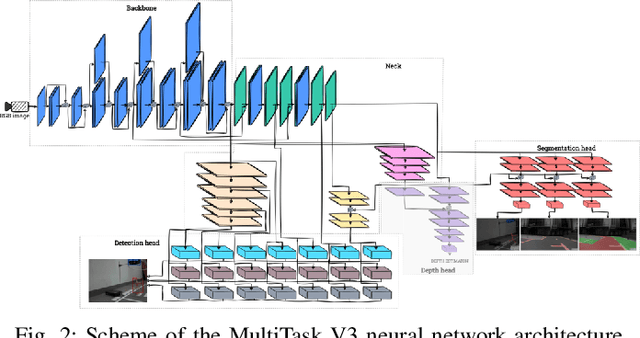
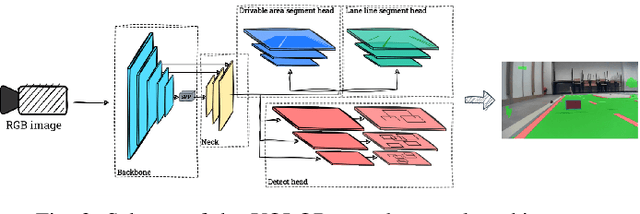
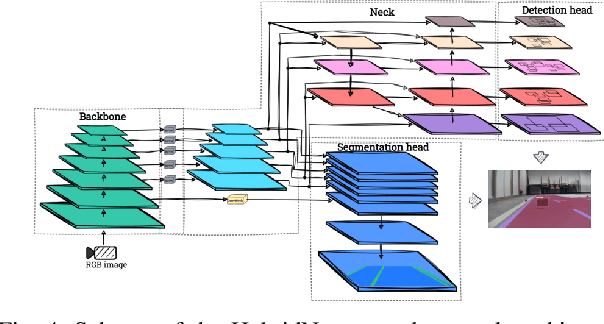
Object detection and segmentation are two core modules of an autonomous vehicle perception system. They should have high efficiency and low latency while reducing computational complexity. Currently, the most commonly used algorithms are based on deep neural networks, which guarantee high efficiency but require high-performance computing platforms. In the case of autonomous vehicles, i.e. cars, but also drones, it is necessary to use embedded platforms with limited computing power, which makes it difficult to meet the requirements described above. A reduction in the complexity of the network can be achieved by using an appropriate: architecture, representation (reduced numerical precision, quantisation, pruning), and computing platform. In this paper, we focus on the first factor - the use of so-called detection-segmentation networks as a component of a perception system. We considered the task of segmenting the drivable area and road markings in combination with the detection of selected objects (pedestrians, traffic lights, and obstacles). We compared the performance of three different architectures described in the literature: MultiTask V3, HybridNets, and YOLOP. We conducted the experiments on a custom dataset consisting of approximately 500 images of the drivable area and lane markings, and 250 images of detected objects. Of the three methods analysed, MultiTask V3 proved to be the best, achieving 99% mAP_50 for detection, 97% MIoU for drivable area segmentation, and 91% MIoU for lane segmentation, as well as 124 fps on the RTX 3060 graphics card. This architecture is a good solution for embedded perception systems for autonomous vehicles. The code is available at: https://github.com/vision-agh/MMAR_2023.
Real-time HOG+SVM based object detection using SoC FPGA for a UHD video stream
Apr 22, 2022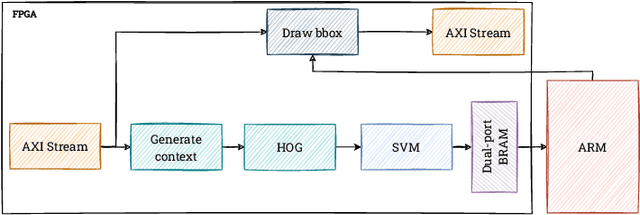
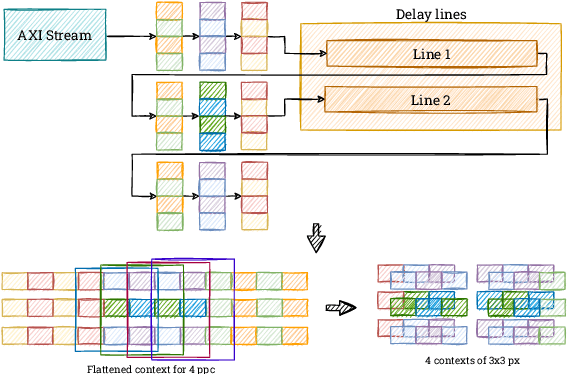
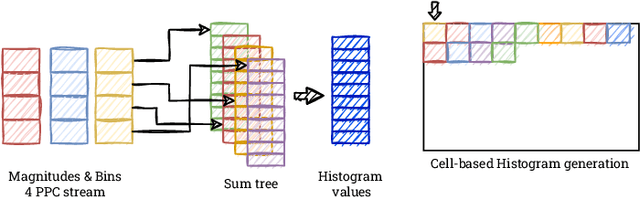
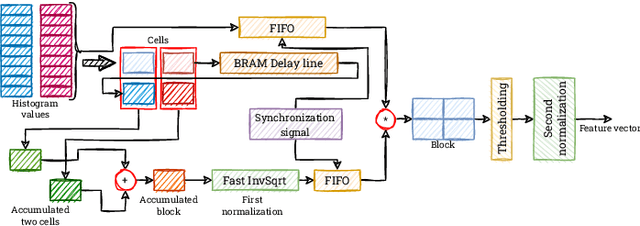
Object detection is an essential component of many vision systems. For example, pedestrian detection is used in advanced driver assistance systems (ADAS) and advanced video surveillance systems (AVSS). Currently, most detectors use deep convolutional neural networks (e.g., the YOLO -- You Only Look Once -- family), which, however, due to their high computational complexity, are not able to process a very high-resolution video stream in real-time, especially within a limited energy budget. In this paper we present a hardware implementation of the well-known pedestrian detector with HOG (Histogram of Oriented Gradients) feature extraction and SVM (Support Vector Machine) classification. Our system running on AMD Xilinx Zynq UltraScale+ MPSoC (Multiprocessor System on Chip) device allows real-time processing of 4K resolution (UHD -- Ultra High Definition, 3840 x 2160 pixels) video for 60 frames per second. The system is capable of detecting a pedestrian in a single scale. The results obtained confirm the high suitability of reprogrammable devices in the real-time implementation of embedded vision systems.
Optimisation of a Siamese Neural Network for Real-Time Energy Efficient Object Tracking
Jul 01, 2020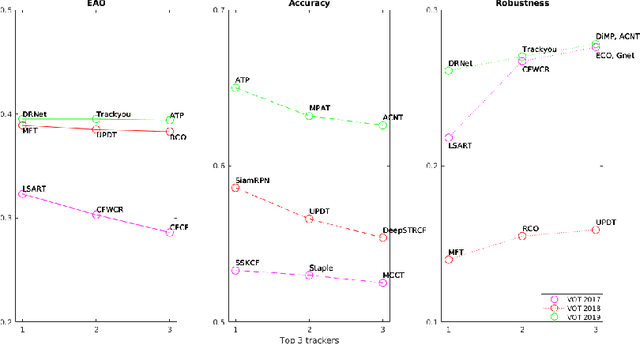

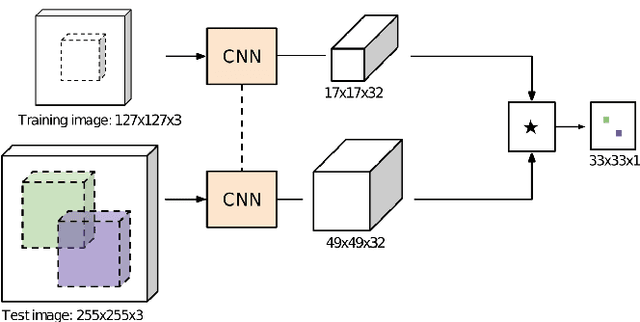

In this paper the research on optimisation of visual object tracking using a Siamese neural network for embedded vision systems is presented. It was assumed that the solution shall operate in real-time, preferably for a high resolution video stream, with the lowest possible energy consumption. To meet these requirements, techniques such as the reduction of computational precision and pruning were considered. Brevitas, a tool dedicated for optimisation and quantisation of neural networks for FPGA implementation, was used. A number of training scenarios were tested with varying levels of optimisations - from integer uniform quantisation with 16 bits to ternary and binary networks. Next, the influence of these optimisations on the tracking performance was evaluated. It was possible to reduce the size of the convolutional filters up to 10 times in relation to the original network. The obtained results indicate that using quantisation can significantly reduce the memory and computational complexity of the proposed network while still enabling precise tracking, thus allow to use it in embedded vision systems. Moreover, quantisation of weights positively affects the network training by decreasing overfitting.
Vision based hardware-software real-time control system for autonomous landing of an UAV
Apr 24, 2020

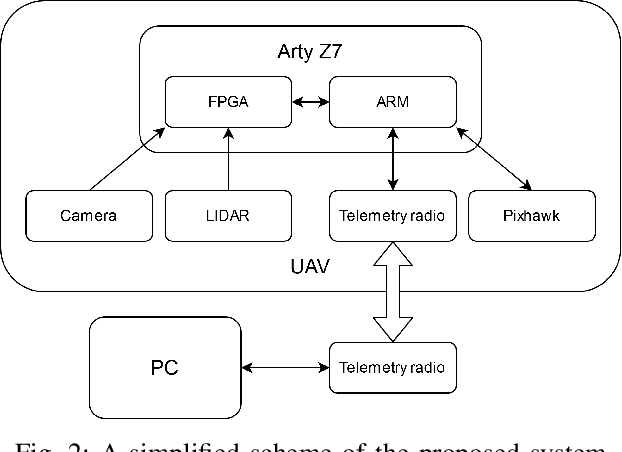

In this paper we present a vision based hardware-software control system enabling autonomous landing of a multirotor unmanned aerial vehicle (UAV). It allows the detection of a marked landing pad in real-time for a 1280 x 720 @ 60 fps video stream. In addition, a LiDAR sensor is used to measure the altitude above ground. A heterogeneous Zynq SoC device is used as the computing platform. The solution was tested on a number of sequences and the landing pad was detected with 96% accuracy. This research shows that a reprogrammable heterogeneous computing system is a good solution for UAVs because it enables real-time data stream processing with relatively low energy consumption.