 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation of a perception system for autonomous vehicles using a detection-segmentation network in SoC FPGA
Jul 17, 2023Perception and control systems for autonomous vehicles are an active area of scientific and industrial research. These solutions should be characterised by high efficiency in recognising obstacles and other environmental elements in different road conditions, real-time capability, and energy efficiency. Achieving such functionality requires an appropriate algorithm and a suitable computing platform. In this paper, we have used the MultiTaskV3 detection-segmentation network as the basis for a perception system that can perform both functionalities within a single architecture. It was appropriately trained, quantised, and implemented on the AMD Xilinx Kria KV260 Vision AI embedded platform. By using this device, it was possible to parallelise and accelerate the computations. Furthermore, the whole system consumes relatively little power compared to a CPU-based implementation (an average of 5 watts, compared to the minimum of 55 watts for weaker CPUs, and the small size (119mm x 140mm x 36mm) of the platform allows it to be used in devices where the amount of space available is limited. It also achieves an accuracy higher than 97% of the mAP (mean average precision) for object detection and above 90% of the mIoU (mean intersection over union) for image segmentation. The article also details the design of the Mecanum wheel vehicle, which was used to test the proposed solution in a mock-up city.
Detection-segmentation convolutional neural network for autonomous vehicle perception
Jun 30, 2023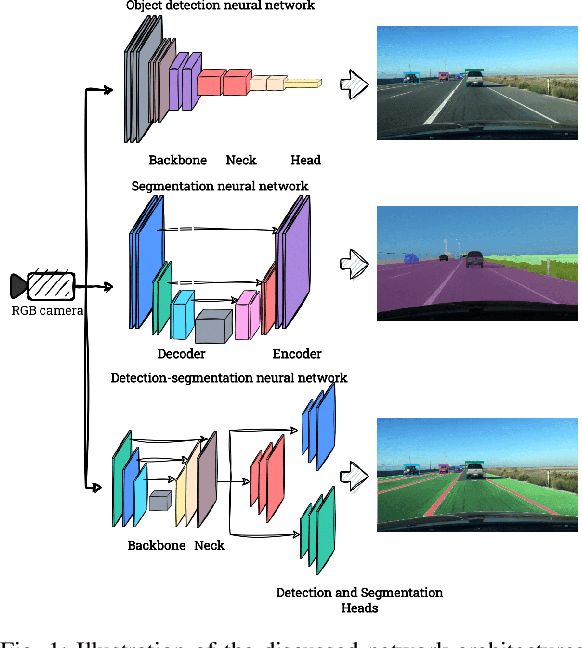
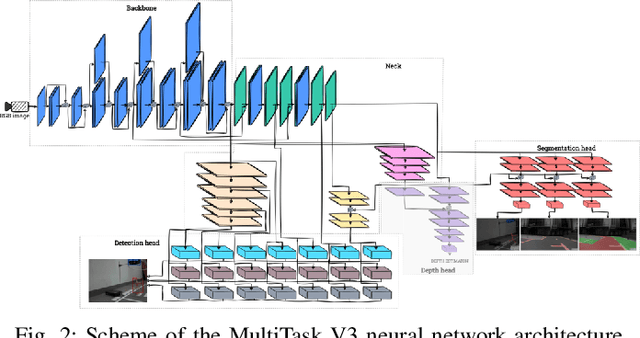
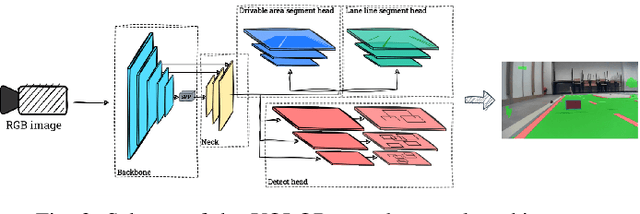
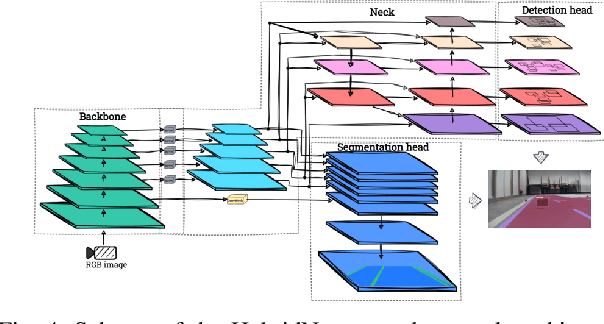
Object detection and segmentation are two core modules of an autonomous vehicle perception system. They should have high efficiency and low latency while reducing computational complexity. Currently, the most commonly used algorithms are based on deep neural networks, which guarantee high efficiency but require high-performance computing platforms. In the case of autonomous vehicles, i.e. cars, but also drones, it is necessary to use embedded platforms with limited computing power, which makes it difficult to meet the requirements described above. A reduction in the complexity of the network can be achieved by using an appropriate: architecture, representation (reduced numerical precision, quantisation, pruning), and computing platform. In this paper, we focus on the first factor - the use of so-called detection-segmentation networks as a component of a perception system. We considered the task of segmenting the drivable area and road markings in combination with the detection of selected objects (pedestrians, traffic lights, and obstacles). We compared the performance of three different architectures described in the literature: MultiTask V3, HybridNets, and YOLOP. We conducted the experiments on a custom dataset consisting of approximately 500 images of the drivable area and lane markings, and 250 images of detected objects. Of the three methods analysed, MultiTask V3 proved to be the best, achieving 99% mAP_50 for detection, 97% MIoU for drivable area segmentation, and 91% MIoU for lane segmentation, as well as 124 fps on the RTX 3060 graphics card. This architecture is a good solution for embedded perception systems for autonomous vehicles. The code is available at: https://github.com/vision-agh/MMAR_2023.