 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differentiable Rank-Based Objective For Better Feature Learning
Feb 13, 2025In this paper, we leverage existing statistical methods to better understand feature learning from data. We tackle this by modifying the model-free variable selection method, Feature Ordering by Conditional Independence (FOCI), which is introduced in \cite{azadkia2021simple}. While FOCI is based on a non-parametric coefficient of conditional dependence, we introduce its parametric, differentiable approximation. With this approximate coefficient of correlation, we present a new algorithm called difFOCI, which is applicable to a wider range of machine learning problems thanks to its differentiable nature and learnable parameters. We present difFOCI in three contexts: (1) as a variable selection method with baseline comparisons to FOCI, (2) as a trainable model parametrized with a neural network, and (3) as a generic, widely applicable neural network regularizer, one that improves feature learning with better management of spurious correlations. We evaluate difFOCI on increasingly complex problems ranging from basic variable selection in toy examples to saliency map comparisons in convolutional networks. We then show how difFOCI can be incorporated in the context of fairness to facilitate classifications without relying on sensitive data.
Understanding Classifier-Free Guidance: High-Dimensional Theory and Non-Linear Generalizations
Feb 11, 2025Recent studies have raised concerns about the effectiveness of Classifier-Free Guidance (CFG), indicating that in low-dimensional settings, it can lead to overshooting the target distribution and reducing sample diversity. In this work, we demonstrate that in infinite and sufficiently high-dimensional contexts CFG effectively reproduces the target distribution, revealing a blessing-of-dimensionality result. Additionally, we explore finite-dimensional effects, precisely characterizing overshoot and variance reduction. Based on our analysis, we introduce non-linear generalizations of CFG. Through numerical simulations on Gaussian mixtures and experiments on class-conditional and text-to-image diffusion models, we validate our analysis and show that our non-linear CFG offers improved flexibility and generation quality without additional computation cost.
The Root Shapes the Fruit: On the Persistence of Gender-Exclusive Harms in Aligned Language Models
Nov 06, 2024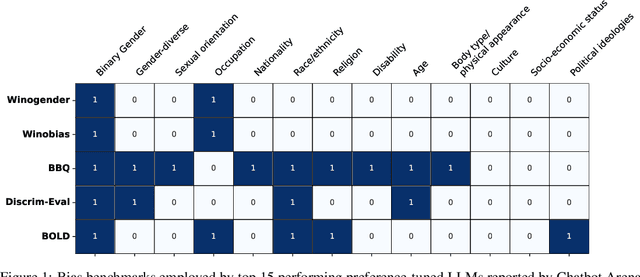

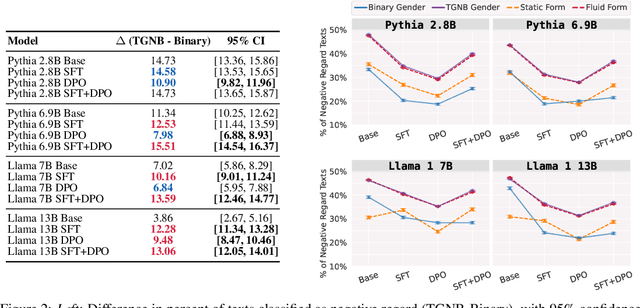

Natural-language assistants are designed to provide users with helpful responses while avoiding harmful outputs, largely achieved through alignment to human preferences. Yet there is limited understanding of whether alignment techniques may inadvertently perpetuate or even amplify harmful biases inherited from their pre-aligned base models. This issue is compounded by the choice of bias evaluation benchmarks in popular preference-finetuned models, which predominantly focus on dominant social categories, such as binary gender, thereby limiting insights into biases affecting underrepresented groups. Towards addressing this gap, we center transgender, nonbinary, and other gender-diverse identities to investigate how alignment procedures interact with pre-existing gender-diverse bias in LLMs. Our key contributions include: 1) a comprehensive survey of bias evaluation modalities across leading preference-finetuned LLMs, highlighting critical gaps in gender-diverse representation, 2) systematic evaluation of gender-diverse biases across 12 models spanning Direct Preference Optimization (DPO) stages, uncovering harms popular bias benchmarks fail to detect, and 3) a flexible framework for measuring harmful biases in implicit reward signals applicable to other social contexts. Our findings reveal that DPO-aligned models are particularly sensitive to supervised finetuning (SFT), and can amplify two forms of real-world gender-diverse harms from their base models: stigmatization and gender non-affirmative language. We conclude with recommendations tailored to DPO and broader alignment practices, advocating for the adoption of community-informed bias evaluation frameworks to more effectively identify and address underrepresented harms in LLMs.
Approximate Heavy Tails in Offline (Multi-Pass) Stochastic Gradient Descent
Oct 27, 2023



A recent line of empirical studies has demonstrated that SGD might exhibit a heavy-tailed behavior in practical settings, and the heaviness of the tails might correlate with the overall performance. In this paper, we investigate the emergence of such heavy tails. Previous works on this problem only considered, up to our knowledge, online (also called single-pass) SGD, in which the emergence of heavy tails in theoretical findings is contingent upon access to an infinite amount of data. Hence, the underlying mechanism generating the reported heavy-tailed behavior in practical settings, where the amount of training data is finite, is still not well-understood. Our contribution aims to fill this gap. In particular, we show that the stationary distribution of offline (also called multi-pass) SGD exhibits 'approximate' power-law tails and the approximation error is controlled by how fast the empirical distribution of the training data converges to the true underlying data distribution in the Wasserstein metric. Our main takeaway is that, as the number of data points increases, offline SGD will behave increasingly 'power-law-like'. To achieve this result, we first prove nonasymptotic Wasserstein convergence bounds for offline SGD to online SGD as the number of data points increases, which can be interesting on their own. Finally, we illustrate our theory on various experiments conducted on synthetic data and neural networks.
MARS: Meta-Learning as Score Matching in the Function Space
Oct 24, 2022



Meta-learning aims to extract useful inductive biases from a set of related datasets. In Bayesian meta-learning, this is typically achieved by constructing a prior distribution over neural network parameters. However, specifying families of computationally viable prior distributions over the high-dimensional neural network parameters is difficult. As a result, existing approaches resort to meta-learning restrictive diagonal Gaussian priors, severely limiting their expressiveness and performance. To circumvent these issues, we approach meta-learning through the lens of functional Bayesian neural network inference, which views the prior as a stochastic process and performs inference in the function space. Specifically, we view the meta-training tasks as samples from the data-generating process and formalize meta-learning as empirically estimating the law of this stochastic process. Our approach can seamlessly acquire and represent complex prior knowledge by meta-learning the score function of the data-generating process marginals instead of parameter space priors. In a comprehensive benchmark, we demonstrate that our method achieves state-of-the-art performance in terms of predictive accuracy and substantial improvements in the quality of uncertainty estimates.