 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Targeted Dynamic Chunking for Tokenization-Free Hierarchical Model
May 28, 2026Tokenization-free hierarchical models are emerging as a promising alternative to traditional Large Language Models (LLMs), addressing inherent preprocessing issues such as vocabulary design complexity, out-of-vocabulary (OOV) errors, and language-specific constraints. However, a significant challenge in these byte-level methods is the optimization of the compression ratio, a critical factor that dictates model performance for processing bytes data via chunks. In this paper, we propose Adaptive Targeted Dynamic Chunking (ATDC), a novel byte-compression control mechanism designed to enhance the effectiveness of dynamic chunking within hierarchical architectures. Our approach utilizes curriculum learning to progressively adjust the compression ratio during training, transitioning from low to high compression to stabilize the learning process. We provide an analysis establishing the relationship between the target compression ratio and Bytes-Per-Innermost-Chunk (BPIC), allowing for tracking of chunk-size evolution throughout the training phase. Evaluations conducted on the FineWeb-Edu 100B dataset demonstrate that hierarchical models equipped with ATDC achieve competitive Bits-Per-Byte (BPB) performance compared to conventional baselines operating at both byte and token levels. Furthermore, the proposed method exhibits more stable training dynamics and superior final performance across diverse downstream tasks compared to models using fixed compression ratios, while maintaining the inherent robustness and flexibility of byte-level processing.
Scalpel: Fine-Grained Alignment of Attention Activation Manifolds via Mixture Gaussian Bridges to Mitigate Multimodal Hallucination
Feb 10, 2026Rapid progress in large vision-language models (LVLMs) has achieved unprecedented performance in vision-language tasks. However, due to the strong prior of large language models (LLMs) and misaligned attention across modalities, LVLMs often generate outputs inconsistent with visual content - termed hallucination. To address this, we propose \textbf{Scalpel}, a method that reduces hallucination by refining attention activation distributions toward more credible regions. Scalpel predicts trusted attention directions for each head in Transformer layers during inference and adjusts activations accordingly. It employs a Gaussian mixture model to capture multi-peak distributions of attention in trust and hallucination manifolds, and uses entropic optimal transport (equivalent to Schrödinger bridge problem) to map Gaussian components precisely. During mitigation, Scalpel dynamically adjusts intervention strength and direction based on component membership and mapping relationships between hallucination and trust activations. Extensive experiments across multiple datasets and benchmarks demonstrate that Scalpel effectively mitigates hallucinations, outperforming previous methods and achieving state-of-the-art performance. Moreover, Scalpel is model- and data-agnostic, requiring no additional computation, only a single decoding step.
SchröMind: Mitigating Hallucinations in Multimodal Large Language Models via Solving the Schrödinger Bridge Problem
Feb 10, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have achieved significant success across various domains. However, their use in high-stakes fields like healthcare remains limited due to persistent hallucinations, where generated text contradicts or ignores visual input. We contend that MLLMs can comprehend images but struggle to produce accurate token sequences. Minor perturbations can shift attention from truthful to untruthful states, and the autoregressive nature of text generation often prevents error correction. To address this, we propose SchröMind-a novel framework reducing hallucinations via solving the Schrödinger bridge problem. It establishes a token-level mapping between hallucinatory and truthful activations with minimal transport cost through lightweight training, while preserving the model's original capabilities. Extensive experiments on the POPE and MME benchmarks demonstrate the superiority of Schrödinger, which achieves state-of-the-art performance while introducing only minimal computational overhead.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021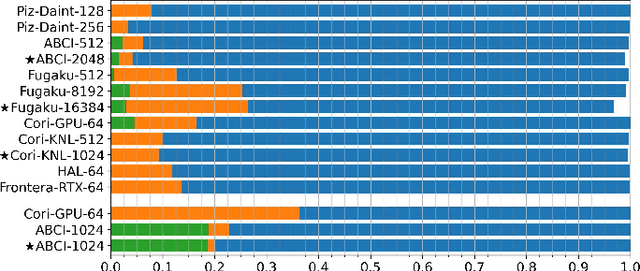
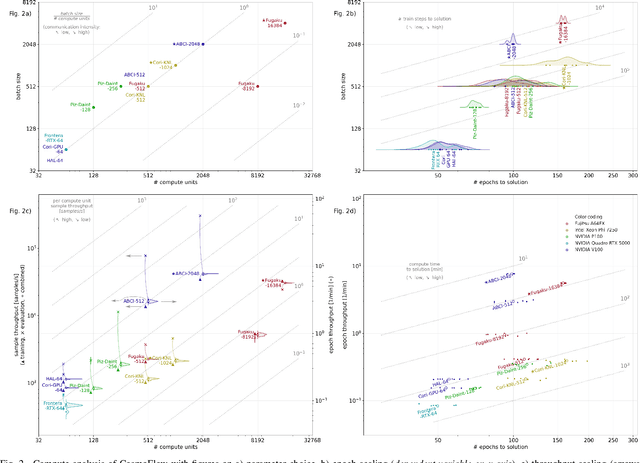
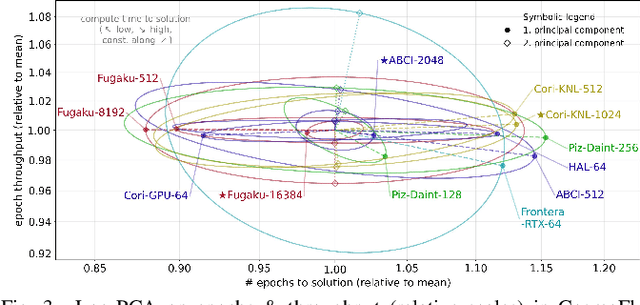
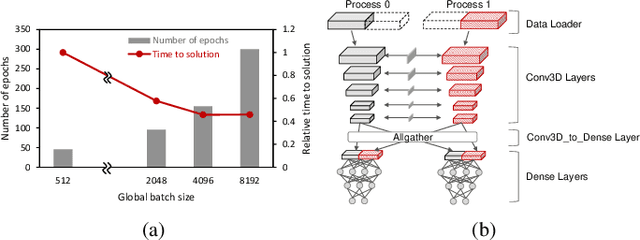
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
An Automated CNN Recommendation System for Image Classification Tasks
Dec 27, 2016



Nowadays the CNN is widely used in practical applications for image classification task. However the design of the CNN model is very professional work and which is very difficult for ordinary users. Besides, even for experts of CNN, to select an optimal model for specific task may still need a lot of time (to train many different models). In order to solve this problem, we proposed an automated CNN recommendation system for image classification task. Our system is able to evaluate the complexity of the classification task and the classification ability of the CNN model precisely. By using the evaluation results, the system can recommend the optimal CNN model and which can match the task perfectly. The recommendation process of the system is very fast since we don't need any model training. The experiment results proved that the evaluation methods are very accurate and reliable.