 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete diffusion samplers and bridges: Off-policy algorithms and applications in latent spaces
Feb 05, 2026Sampling from a distribution $p(x) \propto e^{-\mathcal{E}(x)}$ known up to a normalising constant is an important and challenging problem in statistics. Recent years have seen the rise of a new family of amortised sampling algorithms, commonly referred to as diffusion samplers, that enable fast and efficient sampling from an unnormalised density. Such algorithms have been widely studied for continuous-space sampling tasks; however, their application to problems in discrete space remains largely unexplored. Although some progress has been made in this area, discrete diffusion samplers do not take full advantage of ideas commonly used for continuous-space sampling. In this paper, we propose to bridge this gap by introducing off-policy training techniques for discrete diffusion samplers. We show that these techniques improve the performance of discrete samplers on both established and new synthetic benchmarks. Next, we generalise discrete diffusion samplers to the task of bridging between two arbitrary distributions, introducing data-to-energy Schrödinger bridge training for the discrete domain for the first time. Lastly, we showcase the application of the proposed diffusion samplers to data-free posterior sampling in the discrete latent spaces of image generative models.
FINALLY: fast and universal speech enhancement with studio-like quality
Oct 08, 2024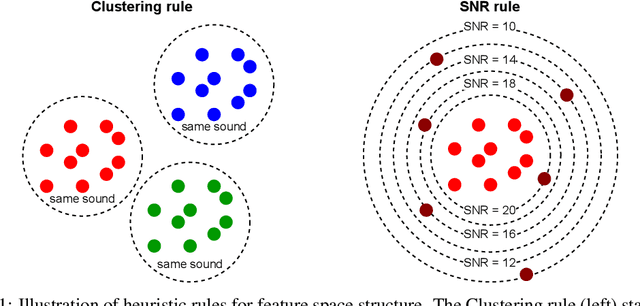
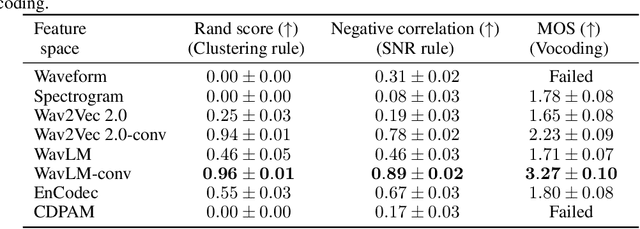
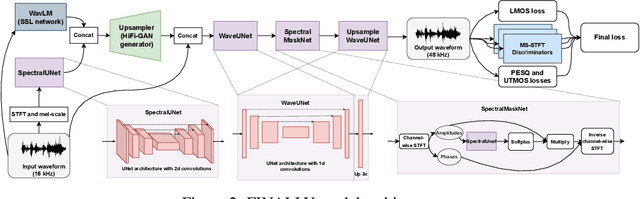
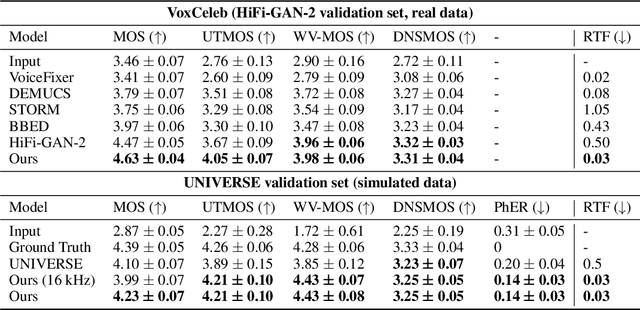
In this paper, we address the challenge of speech enhancement in real-world recordings, which often contain various forms of distortion, such as background noise, reverberation, and microphone artifacts. We revisit the use of Generative Adversarial Networks (GANs) for speech enhancement and theoretically show that GANs are naturally inclined to seek the point of maximum density within the conditional clean speech distribution, which, as we argue, is essential for the speech enhancement task. We study various feature extractors for perceptual loss to facilitate the stability of adversarial training, developing a methodology for probing the structure of the feature space. This leads us to integrate WavLM-based perceptual loss into MS-STFT adversarial training pipeline, creating an effective and stable training procedure for the speech enhancement model. The resulting speech enhancement model, which we refer to as FINALLY, builds upon the HiFi++ architecture, augmented with a WavLM encoder and a novel training pipeline. Empirical results on various datasets confirm our model's ability to produce clear, high-quality speech at 48 kHz, achieving state-of-the-art performance in the field of speech enhancement.