 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINALLY: fast and universal speech enhancement with studio-like quality
Oct 08, 2024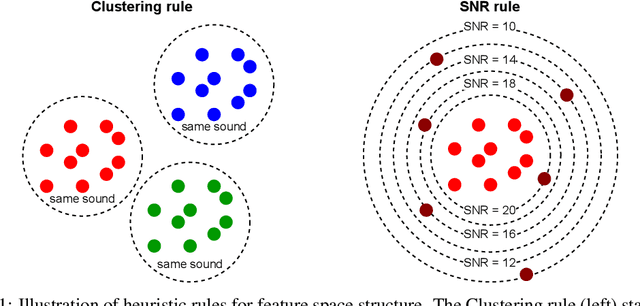
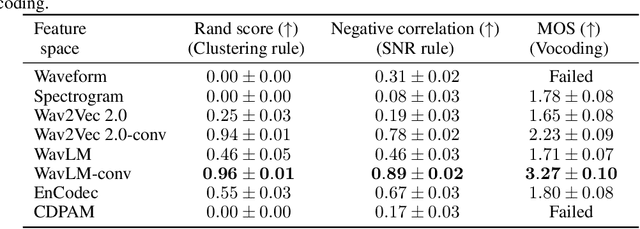
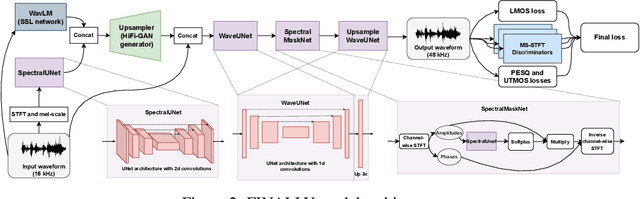
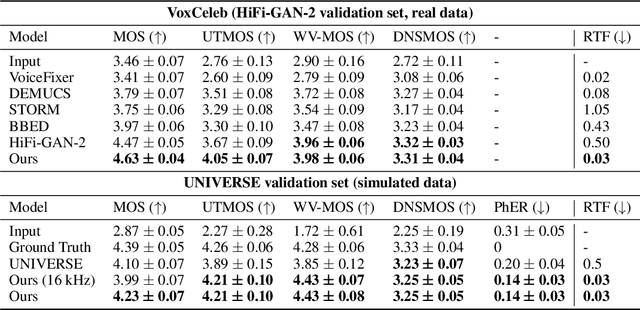
In this paper, we address the challenge of speech enhancement in real-world recordings, which often contain various forms of distortion, such as background noise, reverberation, and microphone artifacts. We revisit the use of Generative Adversarial Networks (GANs) for speech enhancement and theoretically show that GANs are naturally inclined to seek the point of maximum density within the conditional clean speech distribution, which, as we argue, is essential for the speech enhancement task. We study various feature extractors for perceptual loss to facilitate the stability of adversarial training, developing a methodology for probing the structure of the feature space. This leads us to integrate WavLM-based perceptual loss into MS-STFT adversarial training pipeline, creating an effective and stable training procedure for the speech enhancement model. The resulting speech enhancement model, which we refer to as FINALLY, builds upon the HiFi++ architecture, augmented with a WavLM encoder and a novel training pipeline. Empirical results on various datasets confirm our model's ability to produce clear, high-quality speech at 48 kHz, achieving state-of-the-art performance in the field of speech enhancement.
Speech Boosting: Low-Latency Live Speech Enhancement for TWS Earbuds
Sep 27, 2024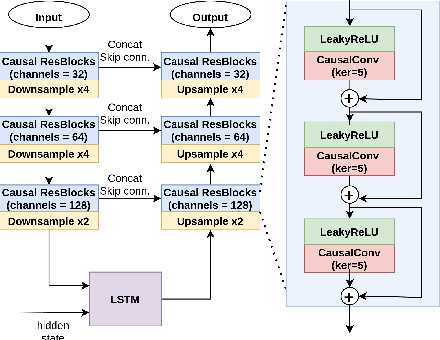


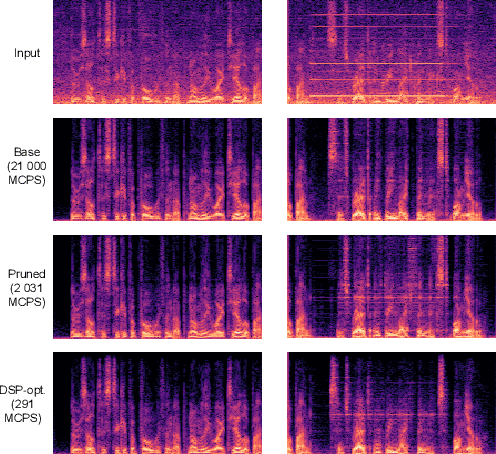
This paper introduces a speech enhancement solution tailored for true wireless stereo (TWS) earbuds on-device usage. The solution was specifically designed to support conversations in noisy environments, with active noise cancellation (ANC) activated. The primary challenges for speech enhancement models in this context arise from computational complexity that limits on-device usage and latency that must be less than 3 ms to preserve a live conversation. To address these issues, we evaluated several crucial design elements, including the network architecture and domain, design of loss functions, pruning method, and hardware-specific optimization. Consequently, we demonstrated substantial improvements in speech enhancement quality compared with that in baseline models, while simultaneously reducing the computational complexity and algorithmic latency.
Iterative autoregression: a novel trick to improve your low-latency speech enhancement model
Nov 03, 2022Streaming models are an essential component of real-time speech enhancement tools. The streaming regime constrains speech enhancement models to use only a tiny context of future information, thus, the low-latency streaming setup is generally assumed to be challenging and has a significant negative effect on the model quality. However, due to the sequential nature of streaming generation, it provides a natural possibility for autoregression, i.e., using previous predictions when making current ones. In this paper, we present a simple, yet effective trick for training of autoregressive low-latency speech enhancement models. We demonstrate that the proposed technique leads to stable improvement across different architectures and training scenarios.