 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINALLY: fast and universal speech enhancement with studio-like quality
Oct 08, 2024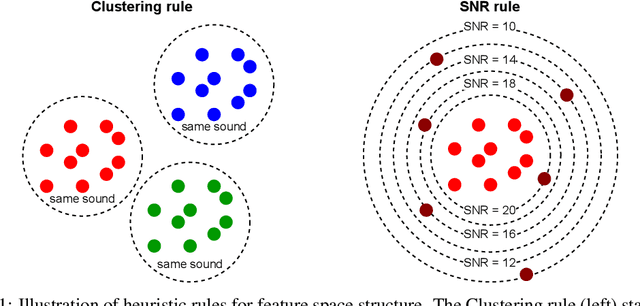
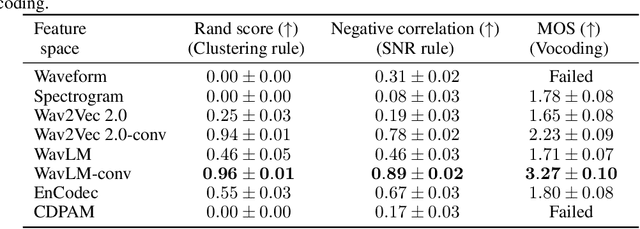
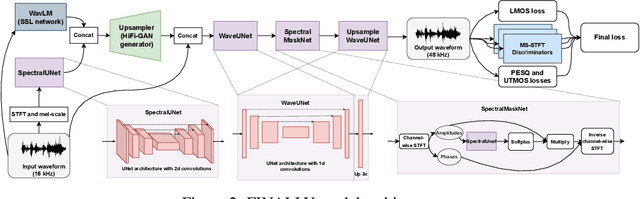
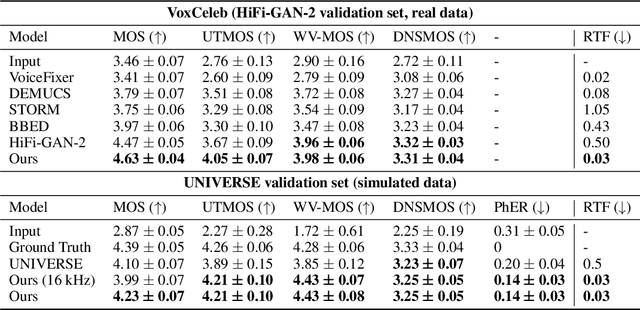
In this paper, we address the challenge of speech enhancement in real-world recordings, which often contain various forms of distortion, such as background noise, reverberation, and microphone artifacts. We revisit the use of Generative Adversarial Networks (GANs) for speech enhancement and theoretically show that GANs are naturally inclined to seek the point of maximum density within the conditional clean speech distribution, which, as we argue, is essential for the speech enhancement task. We study various feature extractors for perceptual loss to facilitate the stability of adversarial training, developing a methodology for probing the structure of the feature space. This leads us to integrate WavLM-based perceptual loss into MS-STFT adversarial training pipeline, creating an effective and stable training procedure for the speech enhancement model. The resulting speech enhancement model, which we refer to as FINALLY, builds upon the HiFi++ architecture, augmented with a WavLM encoder and a novel training pipeline. Empirical results on various datasets confirm our model's ability to produce clear, high-quality speech at 48 kHz, achieving state-of-the-art performance in the field of speech enhancement.